# Einbinden der Bibliothek, in der isoMDS istlibrary(MASS)# Einlesen der Datenbav_cit_data <-read.csv("https://bookdown.org/Armin_E/mds_ex_1/data/bav_cit.csv", row.names =1, sep=",", dec =".")# Ausgabe der Datenbav_cit_data
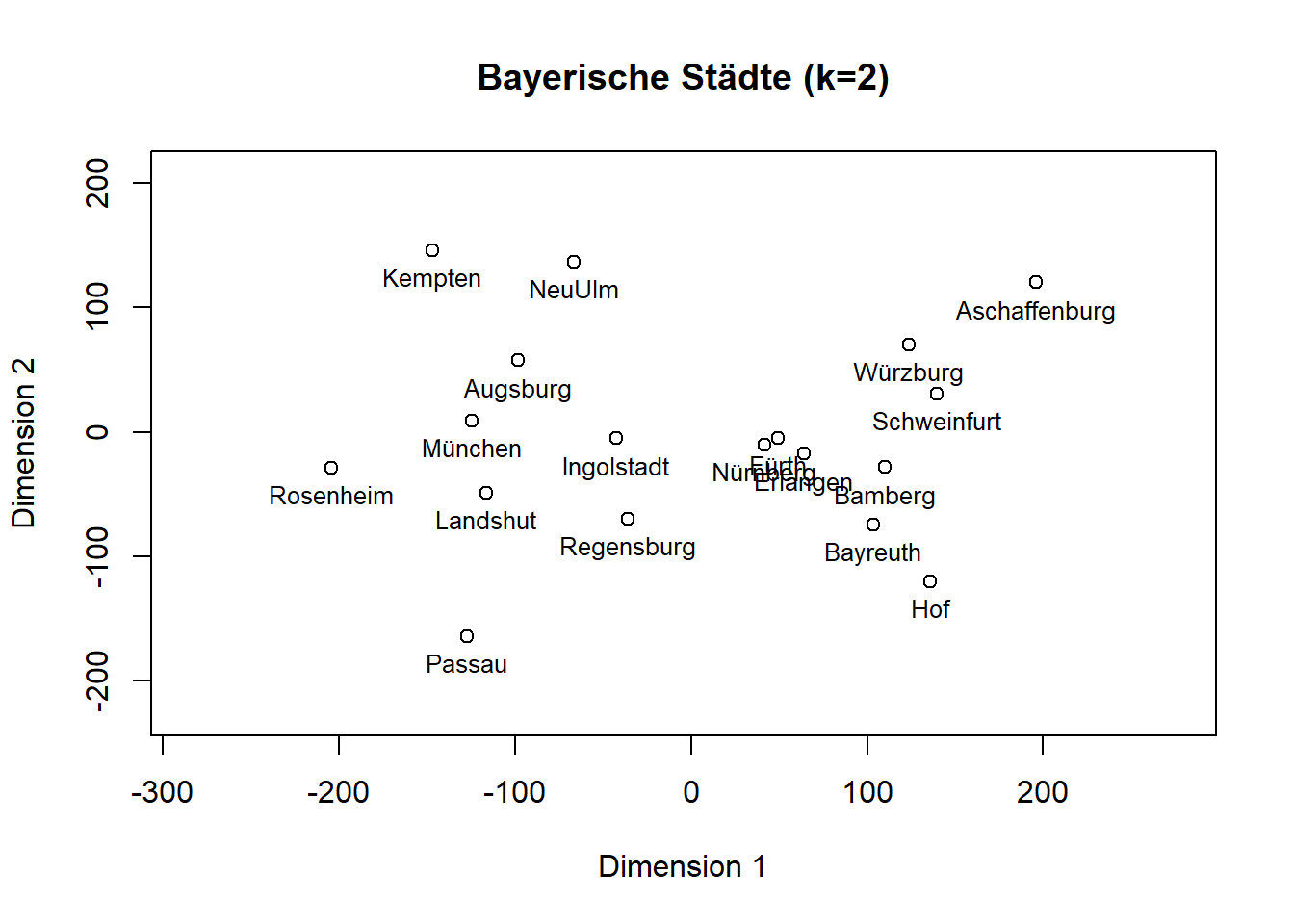
# Umwandeln in den Datentyp Matrix und speichern der Matrix in derselben Variablenbav_cit_data <-as.matrix(bav_cit_data)# Symmetrisieren einer unsymmetrischen Matrixbav_cit_data <- (bav_cit_data +t(bav_cit_data)) /2# Die eigentliche MDS für 2 Dimensionenmds_result <-isoMDS(bav_cit_data, k=2, trace =FALSE)##### unwichtig: nur Aufhübschen ############ Ermittlung der Ausdehnung der Punkte für k=2xrange <-range(mds_result$points[, 1])yrange <-range(mds_result$points[, 2])# Erweiterung der Ränder, damit Labels nicht abgeschnitten werdenxlim <- xrange +c(-1, 1) *diff(xrange) *0.2ylim <- yrange +c(-1, 1) *diff(yrange) *0.2######################################### Ergebnisse plotten für k=2plot(mds_result$points, type ="p", main ="Bayerische Städte (k=2)", xlab ="Dimension 1", ylab ="Dimension 2", xlim = xlim, ylim = ylim)# Beschriftung der Datenpunktetext(mds_result$points, labels =rownames(bav_cit_data), cex =0.8, pos =1)
# STRESS-Wert ausgeben (in %)mds_result$stress
[1] 4.727519
Aufgabe 2: Property Fitting 1
Call:
lm(formula = Längengrade ~ MDS1 + MDS2, data = data)
Residuals:
Min 1Q Median 3Q Max
-0.14955 -0.04283 0.01695 0.05098 0.09694
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.1553056 0.0169408 658.49 < 2e-16 ***
MDS1 -0.0040168 0.0001443 -27.84 2.5e-14 ***
MDS2 -0.0104501 0.0002077 -50.30 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.07187 on 15 degrees of freedom
Multiple R-squared: 0.9956, Adjusted R-squared: 0.995
F-statistic: 1699 on 2 and 15 DF, p-value: < 2.2e-16
Call:
lm(formula = Breitengrade ~ MDS1 + MDS2, data = data)
Residuals:
Min 1Q Median 3Q Max
-0.14042 -0.04224 0.02269 0.04738 0.08903
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.1032500 0.0168650 2911.55 < 2e-16 ***
MDS1 0.0066595 0.0001436 46.37 < 2e-16 ***
MDS2 -0.0023975 0.0002068 -11.59 6.92e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.07155 on 15 degrees of freedom
Multiple R-squared: 0.9934, Adjusted R-squared: 0.9925
F-statistic: 1126 on 2 and 15 DF, p-value: < 2.2e-16
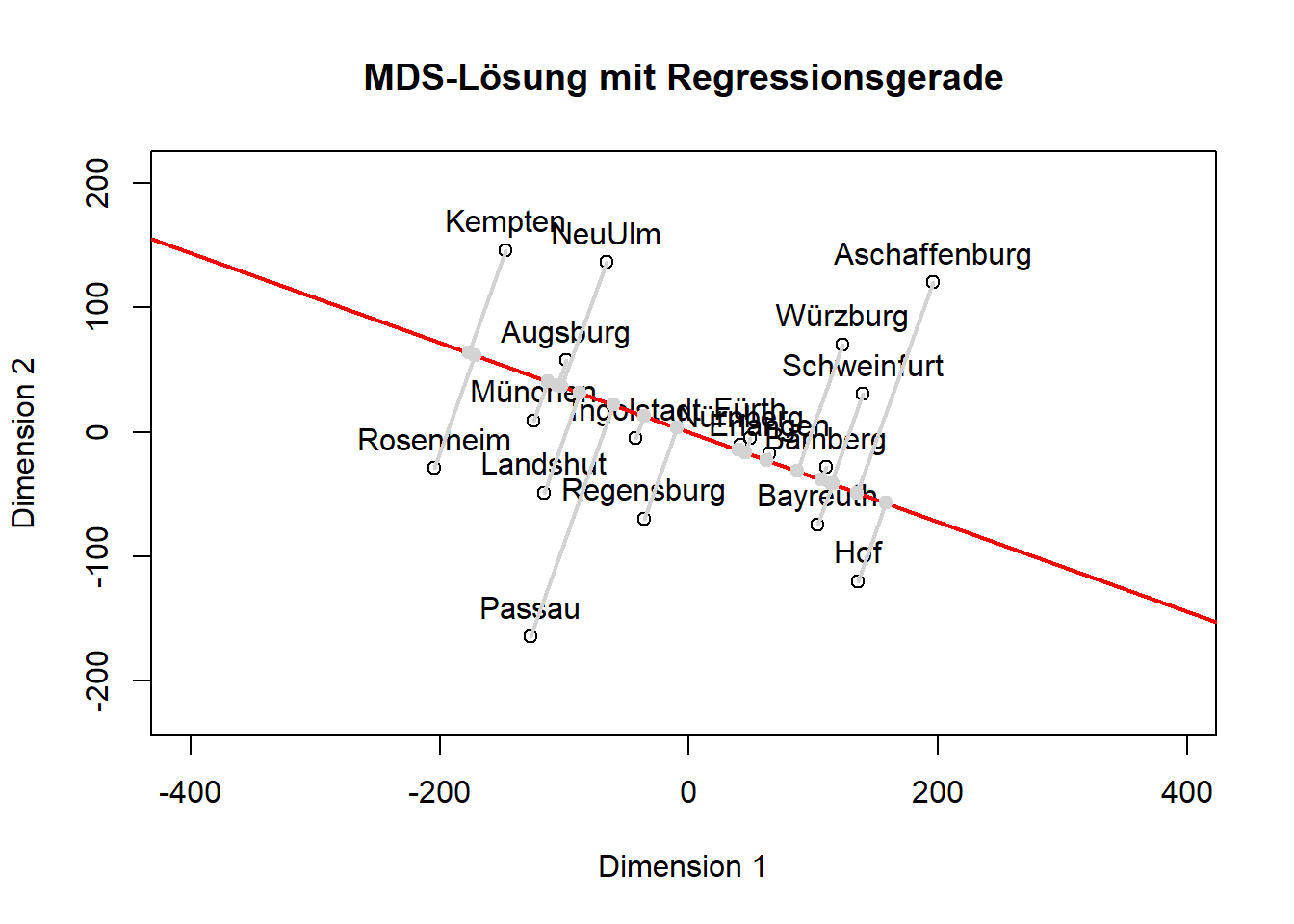
# Speichern der Steigung und des Interceptsb0 <-0b1 <-coef(regression_model)[3] /coef(regression_model)[2] # evtl. 2 und 3 vertauschen; ich glaube aber es stimmt so# Plot der MDS-Koordinatenplot(mds_result$points, main ="MDS-Lösung mit Regressionsgerade", xlab ="Dimension 1", ylab ="Dimension 2", xlim = xlim, ylim = ylim, asp=1)text(mds_result$points, labels =rownames(data), pos =3)# Hinzufügen der Regressionsgeradeabline(a = b0, b = b1, col ="red", lwd =2)steigung <- b1for (i in1:nrow(data)) {# Koordinaten des Datenpunkts x0 <- data$MDS1[i] y0 <- data$MDS2[i]# Berechnung des Lotfußpunkts (x1, y1) auf die Linie y = steigung * x x1 <- (x0 + steigung * y0) / (1+ steigung^2) y1 <- steigung * x1# Zeichnen des Lotssegments(x0, y0, x1, y1, col ="lightgrey", lwd =2)# Zeichnen des Lotfußpunktspoints(x1, y1, col ="lightgrey", pch =19)}
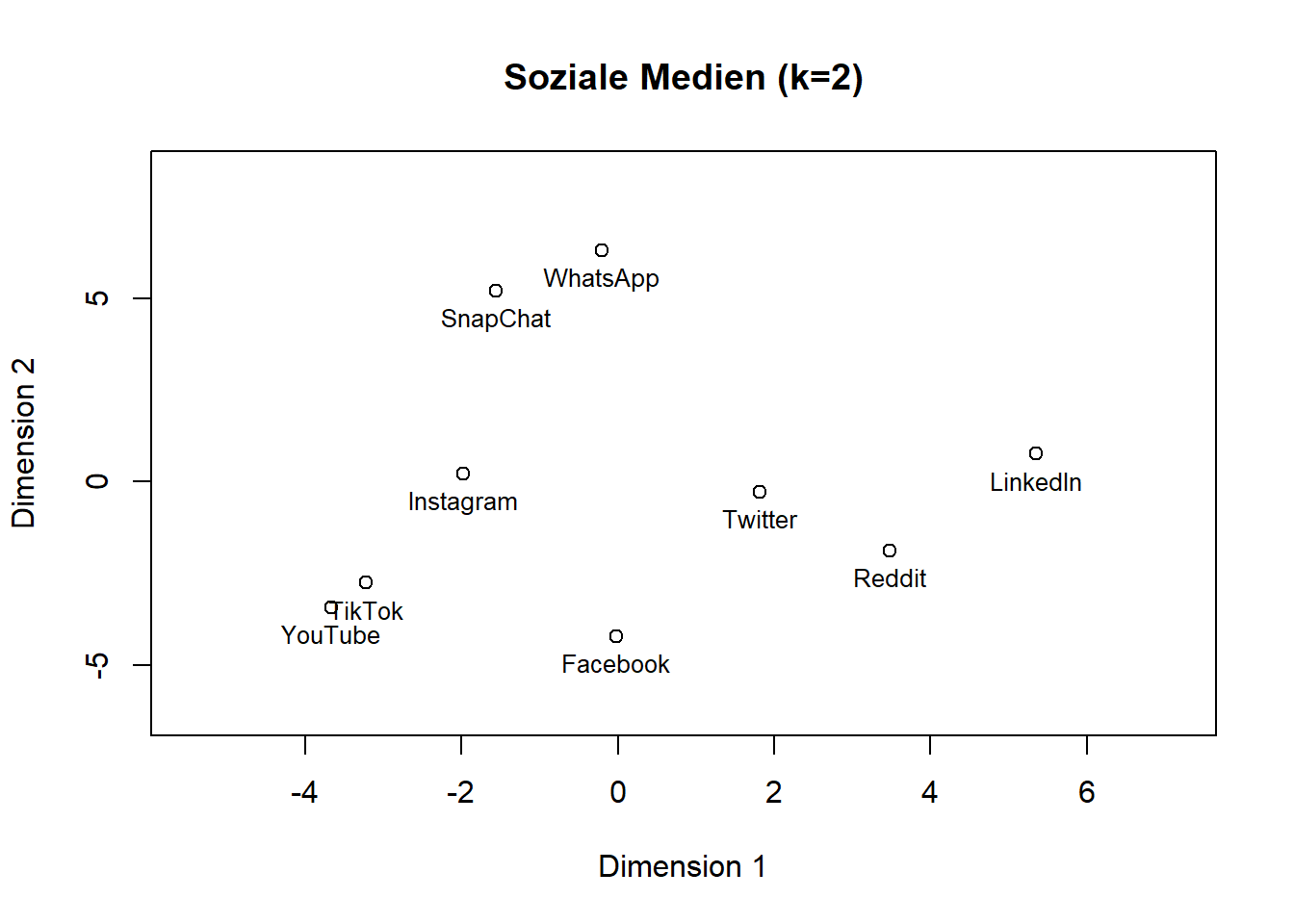
Aufgabe 4: Soziale Medien
Ausgangspunkt ist die Summen-Matrix in der Datei auf iLearn (Bereich Q2:Z11).
Kopieren Sie diesen Bereich und fügen Sie ihn in eine Excel-Datei ein.
# Einlesen der Daten über die URL (Sie lesen damit also meine Daten ein)#soz_med_data <- read.csv("https://bookdown.org/Armin_E/mds_ex_1/data/sozmed_dist.csv", row.names = 1, sep=";", dec = ".")soz_med_data <-read.csv("./data/sozmed_dist.csv", row.names =1, sep=";", dec =".")# Ausgabe der Datensoz_med_data
Twitter Instagram Reddit LinkedIn TikTok SnapChat YouTube WhatsApp
Twitter 8 NA NA NA NA NA NA NA
Instagram 0 8 NA NA NA NA NA NA
Reddit 6 0 8 NA NA NA NA NA
LinkedIn 1 0 2 8 NA NA NA NA
TikTok 0 4 0 0 8 NA NA NA
SnapChat 0 2 0 0 0 8 NA NA
YouTube 0 2 0 0 7 0 8 NA
WhatsApp 0 0 0 0 0 5 0 8
Facebook 4 3 1 0 1 0 1 0
Facebook
Twitter NA
Instagram NA
Reddit NA
LinkedIn NA
TikTok NA
SnapChat NA
YouTube NA
WhatsApp NA
Facebook 8
# Umwandeln in den Datentyp Matrix und speichern der Matrix in derselben Variablensoz_med_data <-as.matrix(soz_med_data)# Symmetrisieren: Vorgehen wir in der Vorlesung# Bei den bayerischen Städten hatten wir schon eine vollständige Matrix,# die aber unsymmetrisch war; hier haben wir nur die untere Hälfte der Matrix, # die wir nach oben kopieren müssensoz_med_data[upper.tri(soz_med_data)] <-t(soz_med_data)[upper.tri(soz_med_data)]# Ausgabe zur Überprüfungsoz_med_data
# Wir haben Ähnlichkeiten und brauchen Distanzen, daher...:# Maximale Ähnlichkeit bestimmenmax_value <-max(soz_med_data)# Dieser Schritt erzeugt die Distanzensoz_med_data <- max_value - soz_med_data# Ab jetzt: Distanzensoz_med_data