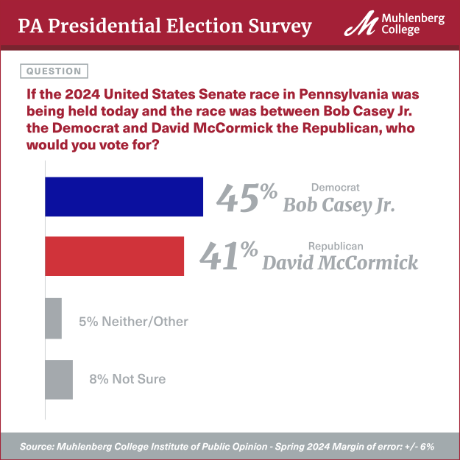
Ψlogical
Testing
House keeping 🧹🧺
- First exam 3/6 (Thurs)
- In class, but administered via Canvas (Ch 1 \(\rightarrow\) 8)
- Lab grade
- Poll incoming
- Project:
- Citi training
- Take a look at feedback (Thurs)


Reliability is…
…freedom from error (within scores)

Error as focus of measurement:
The proof and measurement of association between two things (Spearman, 1904)
An Introduction to the Theory of Mental and Social Measurements (Thorndike, 1904)
The theory of the estimation of test reliability (Kuder & Richardson, 1937)
Coefficient alpha and the internal structure of tests (Cronbach, 1951)

Role of error
- Classical Test Theory (CTT)
- aka True Score Theory (TST)
- Relies on concept of True score
- \(X=T+e_{r}\)
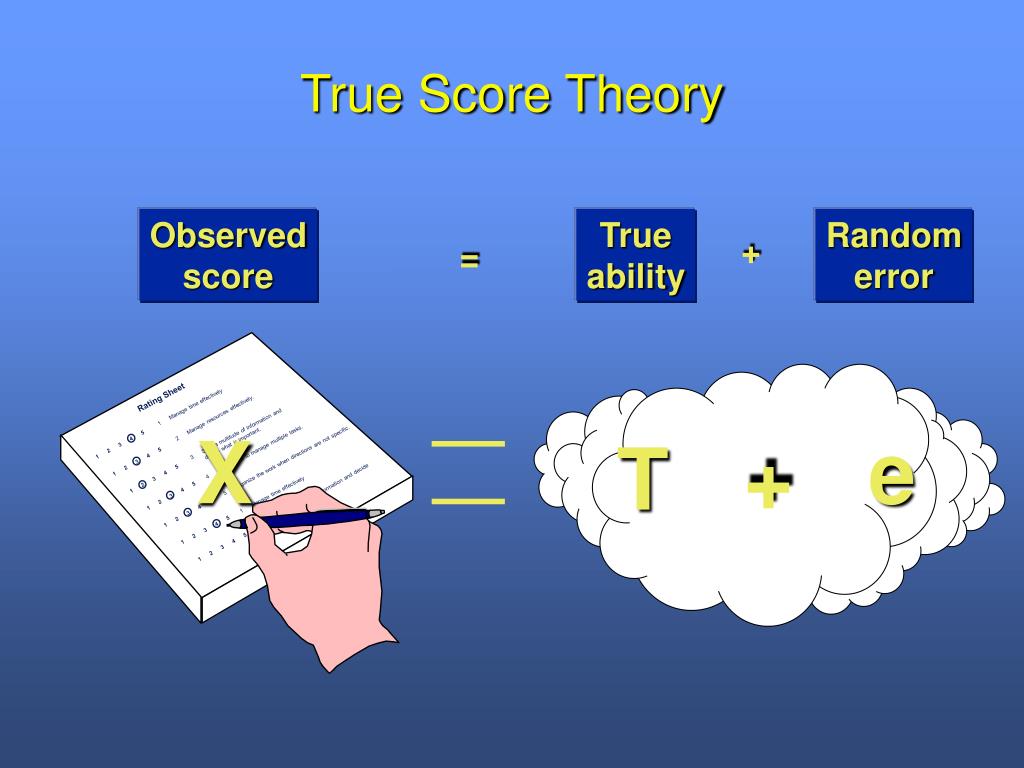
True score…
…theoretical average of scores obtained from the same person over multiple occasions
Standard error of measurement…
…is the standard deviation of these theoretical distributions (here “dispersion” indicates error)


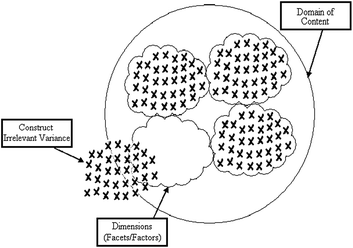
Domain sampling
A universe of possible items exists, but we practically only sample a subset from that vast universe
- defining construct
- populating the content domain
- writing items
- sampling from the content domain
Tip
Content domain = what’s inside your circle
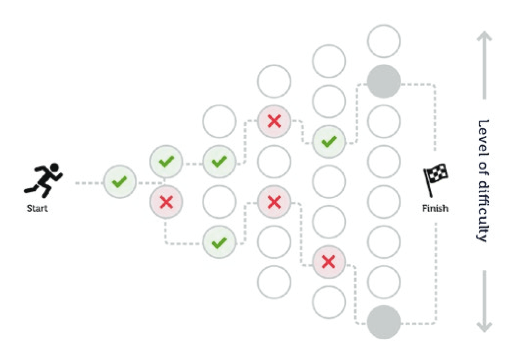
Item Response Theory
- Test adaptive to respondent’s demonstrated level of ability
Note
SAT and ACT are administered and scored traditionally
Models of reliability

Test-retest
- same test, different occasion
- do scores maintain same ordering (across people) over time?
- carryover effect vs construct change
- pre- post- design without intervention

Parallel forms
- different test, same occasion1
- aka sampling from the same domain elements
- similarly representative of construct
- items should be of same difficulty level

Parallel forms? 🤔
…which are “parallel” to Form A and
which are not?
| Form | Item 1 | Item 2 | Item 3 | Item 4 |
|---|---|---|---|---|
| A | \(2+3=?\) | \(9\div3=?\) | \(4\times5=?\) | \(4-1=?\) |
| B | \(1+4=?\) | \(6-3=?\) | \(2\times3=?\) | \(8\div4=?\) |
| C | \(-3+1.5=?\) | \(7\div13=?\) | \(.13\times\frac{5}{6}=?\) | \(-9-6=?\) |
| D | \(4+3=?\) | \(5+2=?\) | \(6+1=?\) | \(2+4=?\) |
Split-half
- same test, same occasion
- treat as though 2 different tests
- must apply correction because of artificial halving
- Spearman-Brown prophecy formula
- what reliability would have been if you hadn’t chopped test in two

Split-half (II)
- content needs to match
- same as parallel forms
- ⚠️🛑DO NOT🛑⚠️ simply take 1st and 2nd halves!!!


\(\alpha\) and KR20
- same test, same occasion
- both indices of internal consistency
- cohesion of item response within scale
- scale needs at least 3 items
- KR20 used with tests
- \(\alpha\) used with inventories

Behavioral observations
- aka inter-rater reliability
- do judges tend to agree (e.g., who is best, worst, etc)
- sometimes uses correlation coefficient
- sometimes uses other index (e.g., Kappa)

Reliability indices
- For MOST, index expressed as correlation
- For ALL:
- larger = greater reliability
- capped at value of 1.0
- typically1 never expressed as negative value

Using reliability
- Standard error of measurement
- used to construct score bands
- same concept as within political polling
- True value thought to be within band (with, e.g., 95% certainty)