Section 9 Etude de cas : Modélisation des crues
Cette activité mobilise les notions vues dans la section “Écoulement”. Les acquis d’apprentissage visés sont :
- S’initier à la modélisation hydrologique
- Estimer les paramètres des fonctions de production et de transfert à partir de données observées de pluie et de débit
- Suggérer des ajustements des méthodes ou des paramètres pour améliorer les simulations produites
9.1 Contexte de l’étude de cas proposée
La modélisation hydrologique est aujourd’hui au cœur de l’hydrologie scientifique. Même si la modélisation n’a pas été abordée de façon explicite dans les cours de ce module, les notions vues dans la section “Écoulement” vont vous permettre de vous initier à la modélisation.
L’étude proposée ici est assez proche des analyses qui peuvent être menées en bureaux d’études, lorsque l’on cherche à déterminer un “débit de projet” afin de dimensionner les différents ouvrages hydrauliques. L’estimation de ce débit requiert la détermination d’une pluie de projet, d’une répartition temporelle de la pluie nette (fonction de production), ainsi que d’une fonction de transfert permettant de transformer la pluie nette en hydrogramme.
Une partie de l’analyse repose sur la sélection d’évènements de crue et la séparation entre écoulement rapide et lent. Ces étapes sont longues et délicates et les évènements sélectionnés ainsi que la séparation des hydrogrammes sont des données fournies, que vous remettrez éventuellement en question.
9.2 Méthodologie et données
Cette section détaille les données que vous pouvez utiliser et les méthodes à suivre.
9.2.1 Etapes de l’étude de cas
Vous pourrez suivre la démarche suivante :
Mise en place de la stratégie de calage-validation.
Détermination du/des paramètres de la fonction de production
Détermination du/des paramètres de la fonction de transfert
Application du modèle sur les évènements de validation
Ces différentes étapes marqueront les différentes taches à réaliser pour cette étude de cas.
9.2.2 Données mobilisées pour l’étude de cas
Toutes les données utilisées dans le cadre de cette étude de cas sont publiques. Ces données publiques sont disponibles sur d’autres bassins à l’échelle de la France et la méthodologie est donc réplicable à d’autres bassins versants. Les données historiques d’observation de précipitation de bassin et de débit sont extraites de la base de données CAMELS-FR (https://doi.org/10.57745/WH7FJR).
En général, on dispose des données historiques sur près de 50 ans (1971-2020) de données en continu au pas de temps journalier. Dans cette étude de cas, le travail se focalise sur la modélisation à l’échelle des évènements. Nous avons donc réalisé en amont de cette étude une sélection d’évènements de crue à partir des chroniques journalières continues. Cette étape de séparations des évènements a suivi la méthodologie décrite dans Saadi et al. (2020).
Dans l’outil de visualisation des données proposé ci-dessous vous permettra de choisir le bassin versant d’étude en connaissance de sa situation géographique et des caractéristiques topographique et d’occupation du sol. Il vous permettra aussi de visualiser les évènements et d’en importer les données.
Les données d’altitude ont été extraites du produit SRTM et les donnes d’occupation du sol du produit Corine Land Cover. Ces deux bases de données sont en accès libre. L’outil de visualisation de données a été développé avec le package R Shiny. Pour un rendu optimal, ouvrez dans un nouvel onglet en cliquant ici
9.3 A vous de jouer…
9.3.1 Etape 0 : Choisissez votre bassin versant et charger les données nécessaires
Vous avez le choix entre 11 bassins versants situés dans différents contextes climatique et géographique. L’outil de visualisation des données vous permettra de charger les données nécessaires.
Pour plus d’informations sur le site choisi, vous pouvez consulter le site Hydroportail (https://hydro.eaufrance.fr/) qui vous permettra de trouver le nom de la rivière à partir du code de la station hydrométrique.
9.3.2 Etape 1 : Déterminez les pluies de bassin à partir de méthodes de spatialisation
Cette étape est importante et doit se faire de façon indépendante des autres étapes. C’est-à-dire que vous ne devez pas revenir sur le choix des évènements une fois que le travail de calage des paramètres est initié.
Le travail ici consiste à composer deux sous ensemble d’évènements : un ensemble de calage qui servira à déterminer les paramètres du modèle et un ensemble de validation qui servira à tester le modèle dans des conditions opérationnelles. Voici quelques éléments à considérer pour vous guider dans votre choix
Vous pouvez commencer par analyser les évènements disponibles en fonction des saisons d’occurrence ;
Vous pouvez distinguer des évènements “simple” générer par une pluie continue ou des évènements multiples générés par plusieurs évènements pluvieux. Il peut être plus facile de déterminer les paramètres de la fonction de transfert lorsque le débit est généré par une seule pluie nette sur un pas de temps. Des évènements simples doivent donc constituer votre ensemble de calage ;
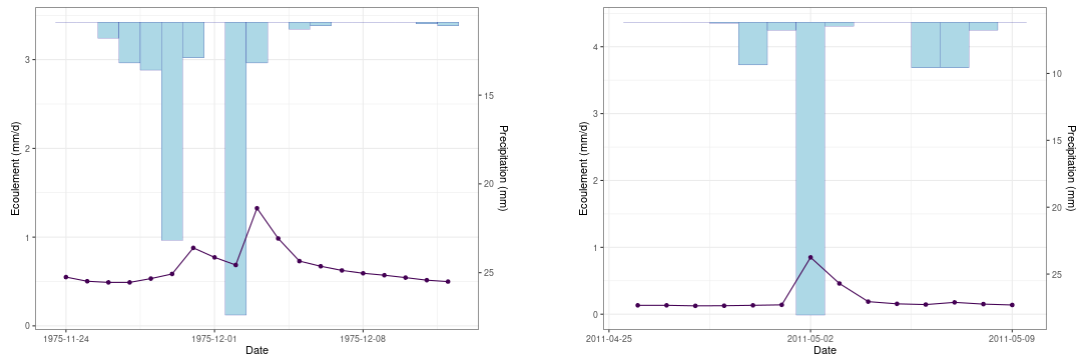
Exemple de deux hydrogrammes. A gauche, un écoulement complexe lié à deux évènements de pluie rapprochés mais avec une interruption et à droite une crue généré par une seule grosse pluie sur un pas de temps.
- Vous pouvez distinguer les évènements en fonction du cumul d’écoulement de surface “Quickflow” et du rapport entre ce cumul et le cumul de pluie de l’évènement.
9.3.3 Etape 2 : Détermination du/des paramètres de la fonction de production
La fonction de production va permettre de déterminer la pluie nette, c’est-à-dire la part de la pluie brute qui va être convertie en écoulement de surface (“quickflow”). Plusieurs fonctions de production ont été présentées dans la section Écoulement du cours.
Nous proposons ici (mais vous êtes libres de faire un autre choix) de tester la méthode SCS (Soil Conservation Service) et de faire l’hypothèse d’un « Curve Number » CN unique quel que soit le degré de saturation du sol (les évènements ont été sélectionnés de telle sorte que les précipitations antérieures étaient faibles).
Vous utiliserez les données des évènements de votre ensemble de calage pour ajuster CN au bassin versant. L’hypothèse principale de la méthode SCS (Soil Conservation Service) est que le rapport des pertes réelles sur les quantités d’eau ruisselées est égal au rapport des pertes maximales potentielles sur le ruissellement maximum potentiel. Ceci peut s’écrire simplement comme suit :
\[ \sum_{j=1}^{nbj} Pn_j = \frac{(\sum_{j=1}^{nbj} P_j-I_a)^2}{\sum_{j=1}^{nbj} P_j-I_a + S} \quad (1) \]
où \(Pn_j\) est la pluie nette du jour \(j\), \(nbj\) est le nombre de jours de l’évènement, \(P_j\) est la pluie de jour \(j\), \(I_a\) est l’abstraction initiale et \(S\) est la capacité de stockage du bassin versant.
Pour réduire le nombre de paramètre, nous utiliserons l’hypothèse classique reliant S au curve number \(CN\) (équation 2) et la relation entre l’abstraction initiale et la capacité de stockage du bassin versant (équation 3).
\[ S = 25.4(\frac{1000}{CN} -10) \quad (2) \]
\[ I_a = 0,2.S \quad (3) \]
Ainsi, l’équation (1) devient :
\[ \sum_{j=1}^{nbj} Pn_j = \frac{(\sum_{j=1}^{nbj} P_j - 0,2.S)^2}{\sum_{j=1}^{nbj} P_j + 0,8.S} \quad (4) \]
avec :
\[ S = 25.4(\frac{1000}{CN} -10) \quad (5) \]
Pour chaque évènement, vous connaissez l’écoulement de surface “Quickflow” et par définition, le cumul de pluie nette sur l’évènement est égal au cumul d’écoulement de surface :
\[ \sum_{j=1}^{nbj} Pn_j = \sum_{j=1}^{nbj} Qs_j\quad (6) \]
Il est donc possible de déterminer la valeur de CN pour chaque évènement.
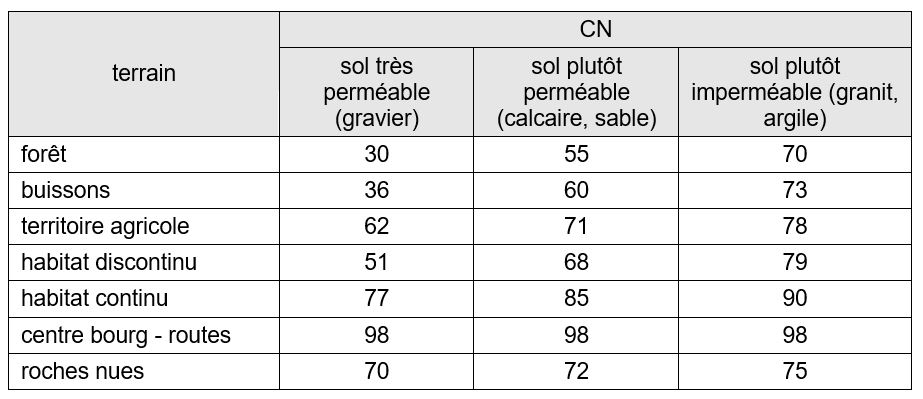
Ces valeurs de CN pourront être discutées vis-à-vis des valeurs de CN tabulaires que l’on peut mobiliser lorsqu’aucune donnée de débit n’est disponible (voir tableau ci-dessous).
9.3.4 Etape 3 : Détermination du/des paramètres de la fonction de transfert
Vous déterminerez l’hydrogramme unitaire à partir d’une sélection d’évènements « simples », c’est-à-dire d’évènements de crue générés par une pluie nette concentrée sur un seul jour.
Le cheminement pour déterminer les ordonnées de l’hydrogramme unitaire est le suivant :
Recensement des évènements pluie-débits passés, en se focalisant sur les évènements avec une seule pluie nette (vous avez besoin ici de la fonction de production déterminée à l’étape 2)
Normalisation des hydrogrammes de chaque évènement pour que la somme des écoulements de surface soit égale à 1.
Détermination d’un hydrogramme “moyen” à partir de l’ensemble des hydrogrammes normalisés.
9.3.5 Etape 4 : Application du modèle sur les évènements de validation
Cette étape consiste à appliquer le modèle obtenu (fonction de production + fonction de transfert) sur les évènements de validation. Plusieurs critères peuvent être ensuite considérés pour juger la qualité du modèle (en termes de respect des volumes, de respect des dynamiques). Des critères numériques comme le critère de Nash et Sutcliffe (1970) ou le critère de Kling- Gupta sont assez répandus et permettront de qualifier la qualité du modèle obtenu.
Pour aller plus loin, on pourra imaginer des tests de sensibilité du modèle au choix des paramètres (CN et ordonnées de l’hydrogramme unitaire), soit en faisant varier les valeurs des paramètres autour des valeurs déterminées aux étapes 1 et 2. Pour le CN, on peut aussi le faire varier pour quantifier l’impact de changements d’occupation du sol par exemple.