11 Communication
11.1 Information Theory
11.1.1 Entropy
Most of the examples are taken from philentropy package in R, which can be accessed via this link
11.1.1.1 Discrete Entropy
If pX=(px1,px2,...,pxn) is the probability distribution of the discrete random variable X with P(X=x)=pxi. Then, the entropy of the distribution is (Shannon 1948)
H(pX)=−∑xipxilog2pxi
where
- entropy unit is bits, and H(p)∈[0,1] and max at p=0.5
- or the unit is nats (loge)
- or the unit is dits (log10)
In general, if you have different bases, you can convert between units. Given bases a and b
logak=logab×logbk
where logab is a constant.
Generalize
Hb(X)=logba×Ha(X)
Equivalently,
H(X)=E(1logp(x))
Entropy is the measure of how much information gained from learning the value of X (Zwillinger 1995, 262). Entropy depends on the distribution of X.
Example:
If X has 2 values, then p=(p,1−p) and
H(pX)=H(p,1−p)=−plog2p−(1−p)log2(1−p)
which is known as binary entropy function
Plot of p vs. H(p) where max of H(pX)=log2n when X∼U
hb <- function(gamma) {
-gamma * log2(gamma) - (1 - gamma) * log2(1 - gamma) # output in bits
}
xs <- seq(0, 1, len = 100)
plot(xs,
hb(xs),
type = 'l',
xlab = "p",
ylab = "H(p)")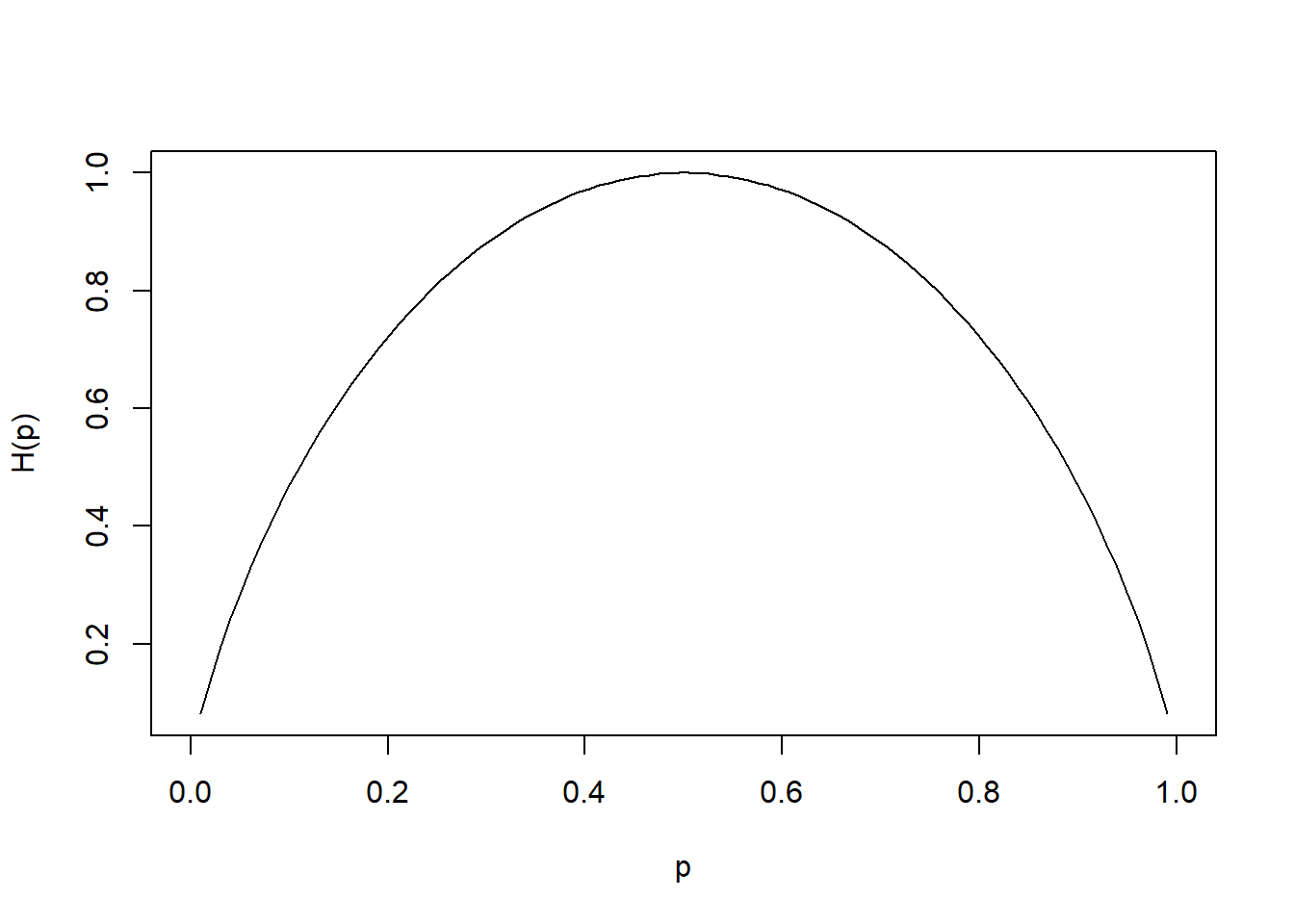
library("philentropy")
Prob <- 1:10/sum(1:10) # probabilities P(X)
H(Prob) # Shannon's Entropy## [1] 3.10364311.1.1.2 Mutual Information
If X and Y are two discrete random variables and pX×Y is the their joint distribution, the mutual information (i.e., learning of a value of X gives information about the value of Y) of X and Y is
I(X,Y)=I(Y,X)=H(pX)+H(pY)−H(pX×Y)
where I(X,Y)≥0 and I(X,Y)=0 iff X and Y are independent (information about X gives no information about Y).
Equivalently,
MI(X,Y)=n∑i=1m∑j=1P(xi,yj)×logb(P(xi,yj)P(xi)×P(yj))
Properties:
- I(X;X)=H(X) known as self-information
- I(X;Y)≥0 with equality iff X⊥Y
P_x <- 1:10/sum(1:10) # distribution P(X)
P_y <- 20:29/sum(20:29) # distribution P(Y)
P_xy <- 1:10/sum(1:10) # joint distribution P(X,Y)
MI(P_x, P_y, P_xy) # Mutual Information## [1] 3.31197311.1.1.3 Relative Entropy
The measure of the distance between distribution p and q is called relative entropy, denoted by D(p||q)
Equivalently, it measures the inefficiency of assuming distribution q when the true distribution is p.
The relative entropy between p(x) and q(x) is
D(p||q)=∑xp(x)logp(x)q(X)
where
- D(p||q)≥0 and equality iff p=q
11.1.1.5 Conditional Entropy
H(Y|X)=−n∑i=1m∑j=1P(xi,yj)×logb(P(xi)P(xi,yj))
P_x <- 1:10/sum(1:10) # distribution P(X)
P_y <- 1:10/sum(1:10) # distribution P(Y)
CE(P_x, P_y) # Joint-Entropy## [1] 0Relation among entropy measures
H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y)
Properties:
- Chain rule: H(X1,...,Xn)=∑ni=1H(Xi|Xi−1,...,X1)
- 0≤H(Y|X)≤H(Y) Information on X does not increase the entropy measure of Y
- If X⊥Y, then H(Y|X)=H(Y);H(X,Y)=H(X)+H(Y)
- H(X)≤log|nX| where nX = number of elements in X
- H(X)=log(nX) iff X∼U
- H(X1,...,Xn)≤∑niH(Xi)
- H(X1,...,Xn)=∑niH(Xi) iff Xi’s are mutually independent.
11.1.1.6 Continuous Entropy
If X is a continuous variable, its entropy is
h(X)=−∫Rdp(x)logp(x)dx
where d is the dimension of X.
If X and Y are continuous random variables with density functions p(x) and q(y), the relative entropy is
H(X,Y)=∫Rdp(x)logp(x)q(x)dx
More advance analysis can be access here
11.1.2 Divergence
Three metrics for divergence can be found here:
- Kullback-Leibler
- Jensen-Shannon
- Generalized Jensen-Shannon
11.1.3 Channel Capacity
The information channel capacity of a discrete memoryless channel is
C=max
which is the highest rate use at which information can be sent without much error.
More information can be found here