Chapter 5 Apuntes lectura capitulos I-VIII R4DS
Estos son algunos apuntes que hice el 2019 al leer R para ciencia de Datos de Hadley Wickham y Garrett Grolemund (version en español) r4ds, espero sea de utilidad, a la vez tiene algunos paquetes y gráficas extras.
5.1 Inicio - Primeros pasos
- Librerias
5.1.1 Conjunto de datos millas
Description
Este conjunto de datos contiene un subconjunto de los datos de economía de combustible que la Agencia de Protección Medioambiental (EPA) pone a disposición en http://fueleconomy.gov. Contiene sólo modelos que tuvieron una nueva versión cada año entre 1999 y 2008, lo que fue utilizado como un proxy de la popularidad del modelo."
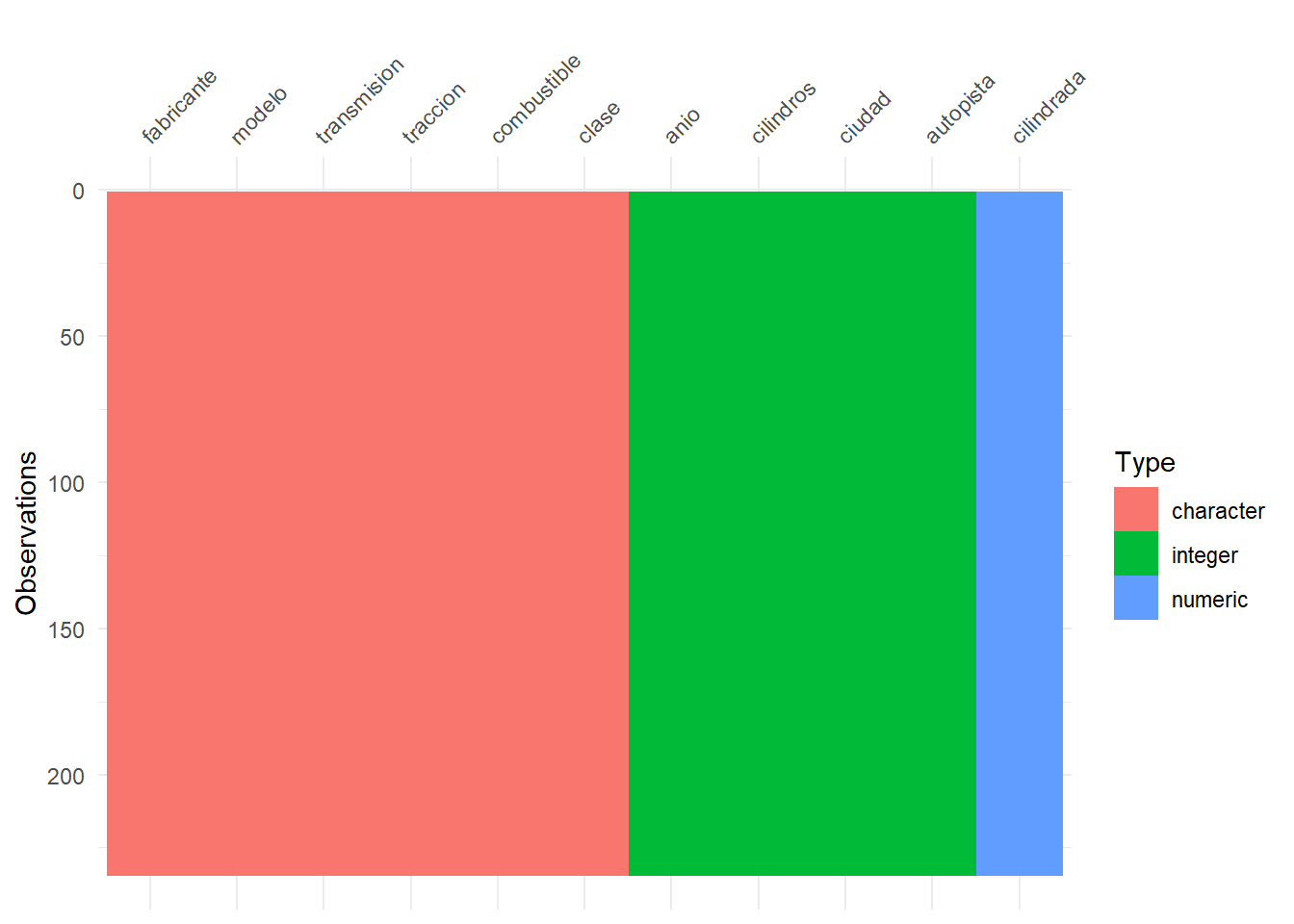
Format Un data.frame con 234 filas y 11 columnas
fabricante: fabricante
modelo: nombre del modelo
cilindrada: tamaño del cilindrada del automóvil, en litros
anio: año de fabricación
cilindros: número de cilindros
transmision: tipo de transmisión
traccion: tipo de tracción (d = delantera, t = trasera, 4 = 4 ruedas)
ciudad: millas por galón de combustible en ciudad
autopista: millas por galón de combustible en autopista
combustible: tipo de combustible (p = premium, r = regular, e = etanol, d = diesel, g = gas natural comprimido)
clase: tipo de auto
Rows: 234
Columns: 11
$ fabricante <chr> "audi", "audi", "audi", "audi", "audi", "audi", "audi",...
$ modelo <chr> "a4", "a4", "a4", "a4", "a4", "a4", "a4", "a4 quattro",...
$ cilindrada <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, ...
$ anio <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 2...
$ cilindros <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8...
$ transmision <chr> "auto(l5)", "manual(m5)", "manual(m6)", "auto(av)", "au...
$ traccion <chr> "d", "d", "d", "d", "d", "d", "d", "4", "4", "4", "4", ...
$ ciudad <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17,...
$ autopista <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25,...
$ combustible <chr> "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", "p", ...
$ clase <chr> "compacto", "compacto", "compacto", "compacto", "compac...- Una forma interactiva de visualizar los tipos de datos
5.1.2 Creando un grafico con ggplot
Aca solo ploteamos un versus entre dos variables y un versus con su densidad
p1=ggplot(data = millas) +
geom_point(mapping = aes(x=cilindrada,y=autopista))
p2=WVPlots::HexBinPlot(millas,"cilindrada","autopista","Scatter Plot 2D")
cowplot::plot_grid(p1,p2)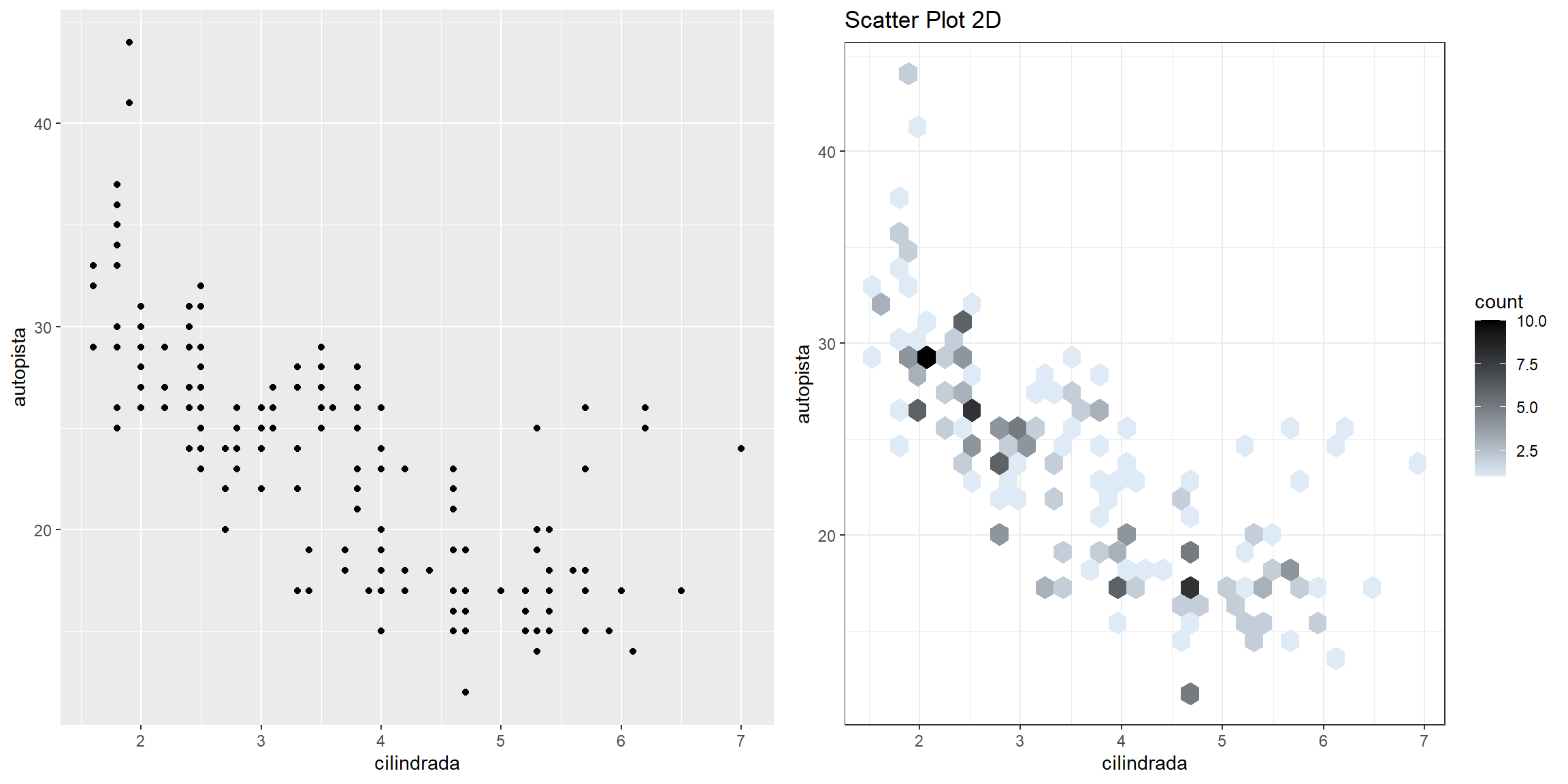
Pero que pasa si queremos ver todos los comportamientos,
5.2 Visualizando por cualidad scatter plots
5.2.1 De la mano de ggplot
Numeracion para shape
ggplot(data = millas) +
geom_point(mapping = aes(x = cilindrada, y = autopista, color = clase),size=4,shape=18)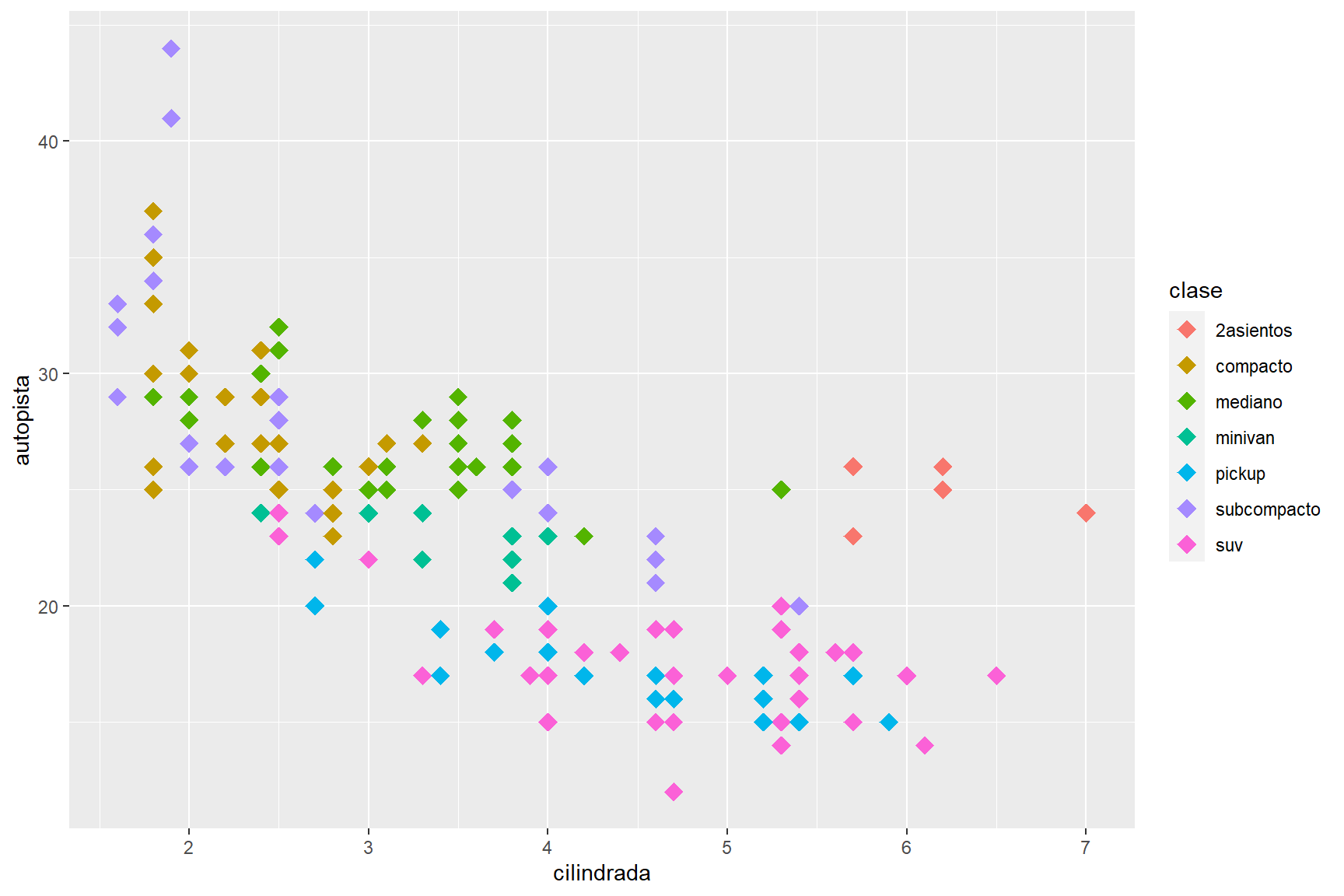
5.2.2 De la mano de WVPlots, de una manera distinta
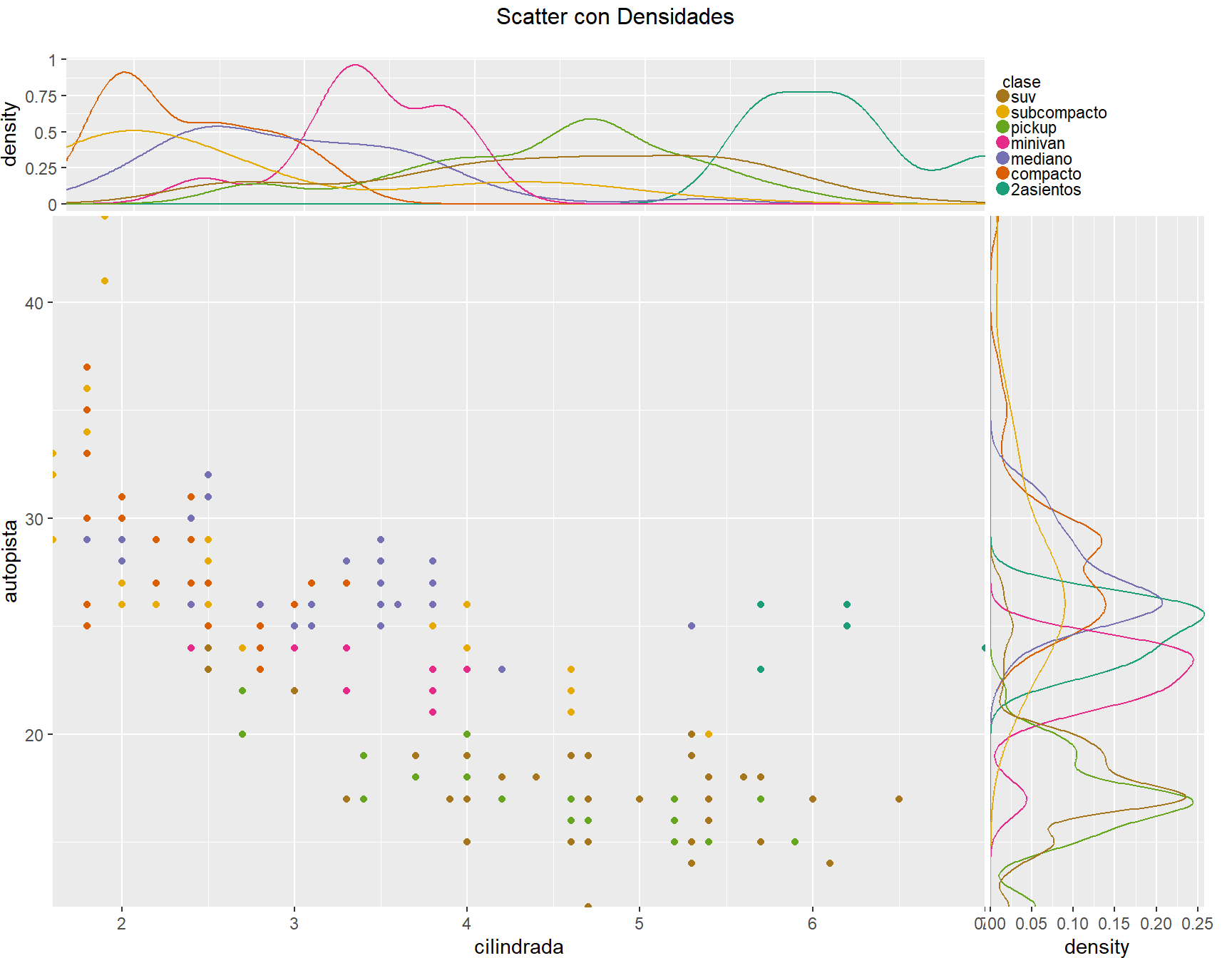
5.2.3 Separando en facetas con ggplot, Scatter plot
ggplot(data = millas) +
geom_point(mapping = aes(x = cilindrada, y = autopista)) +
facet_wrap(~ clase, nrow = 2)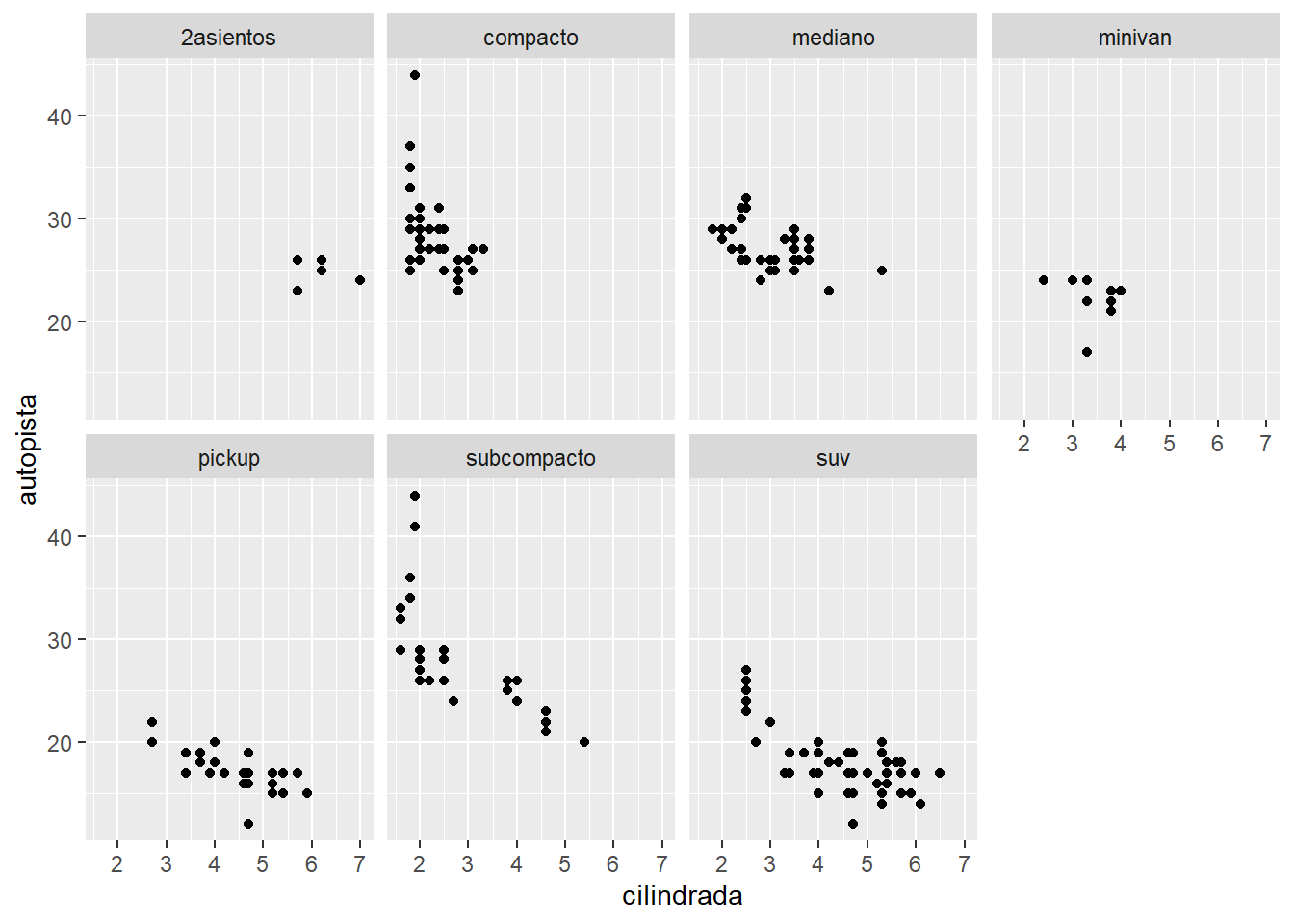
5.2.4 De la mano de WVPlots, de forma multiple
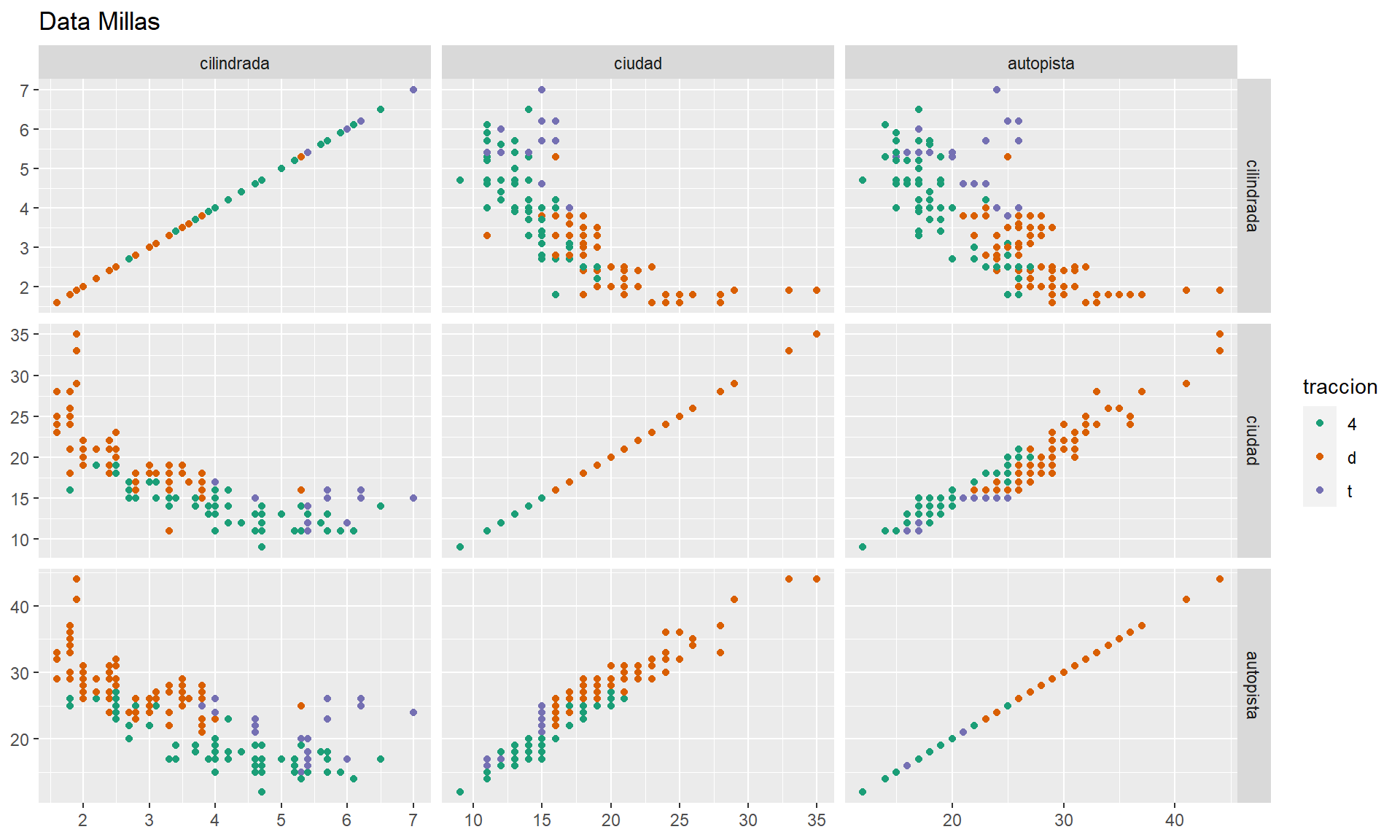
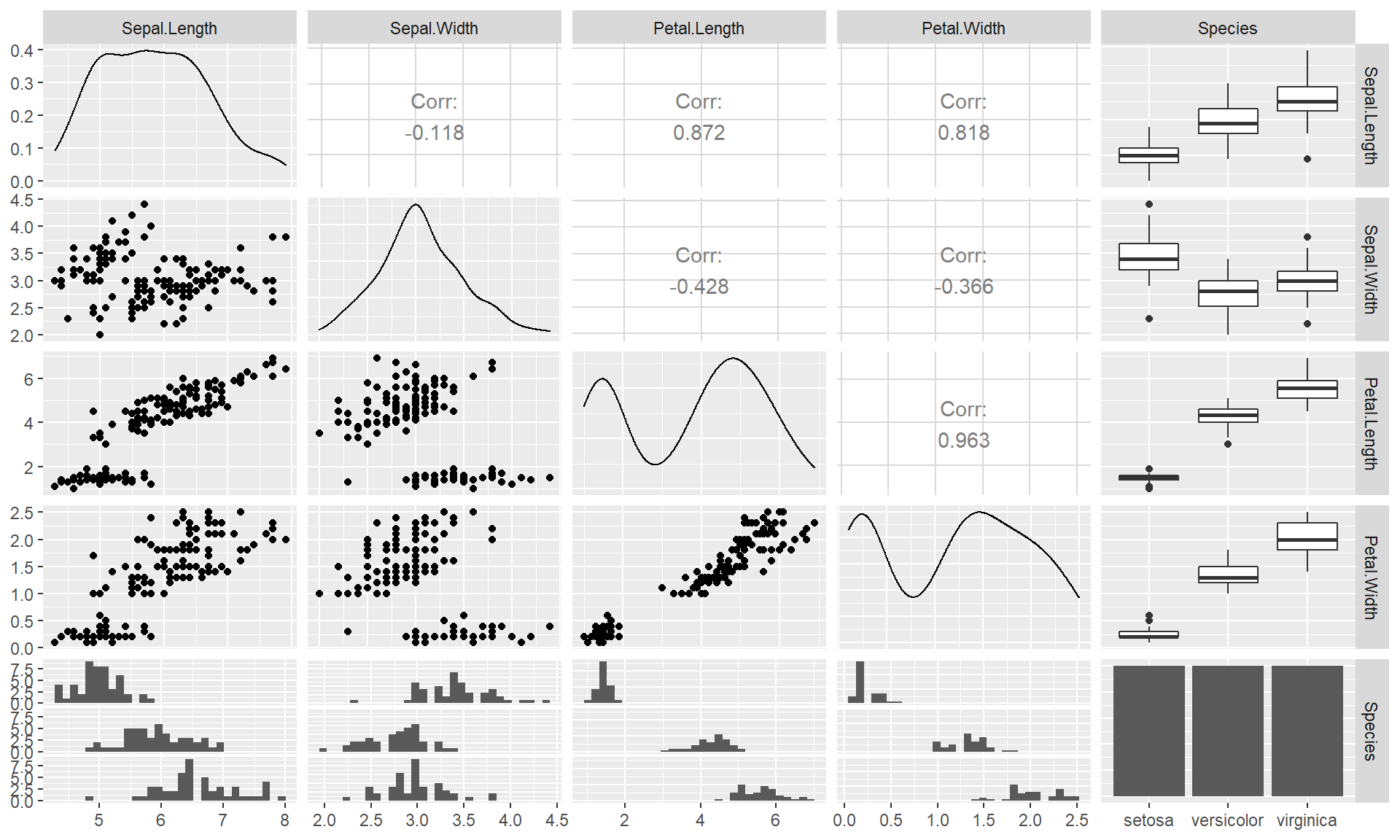
- Solo para variables continuas, con un kernel aproximandolo a la normal: psych::multi.hist() y sus correlaciones con circulos de error psych::pairs.panels(millas).
5.3 Valores Perdidos
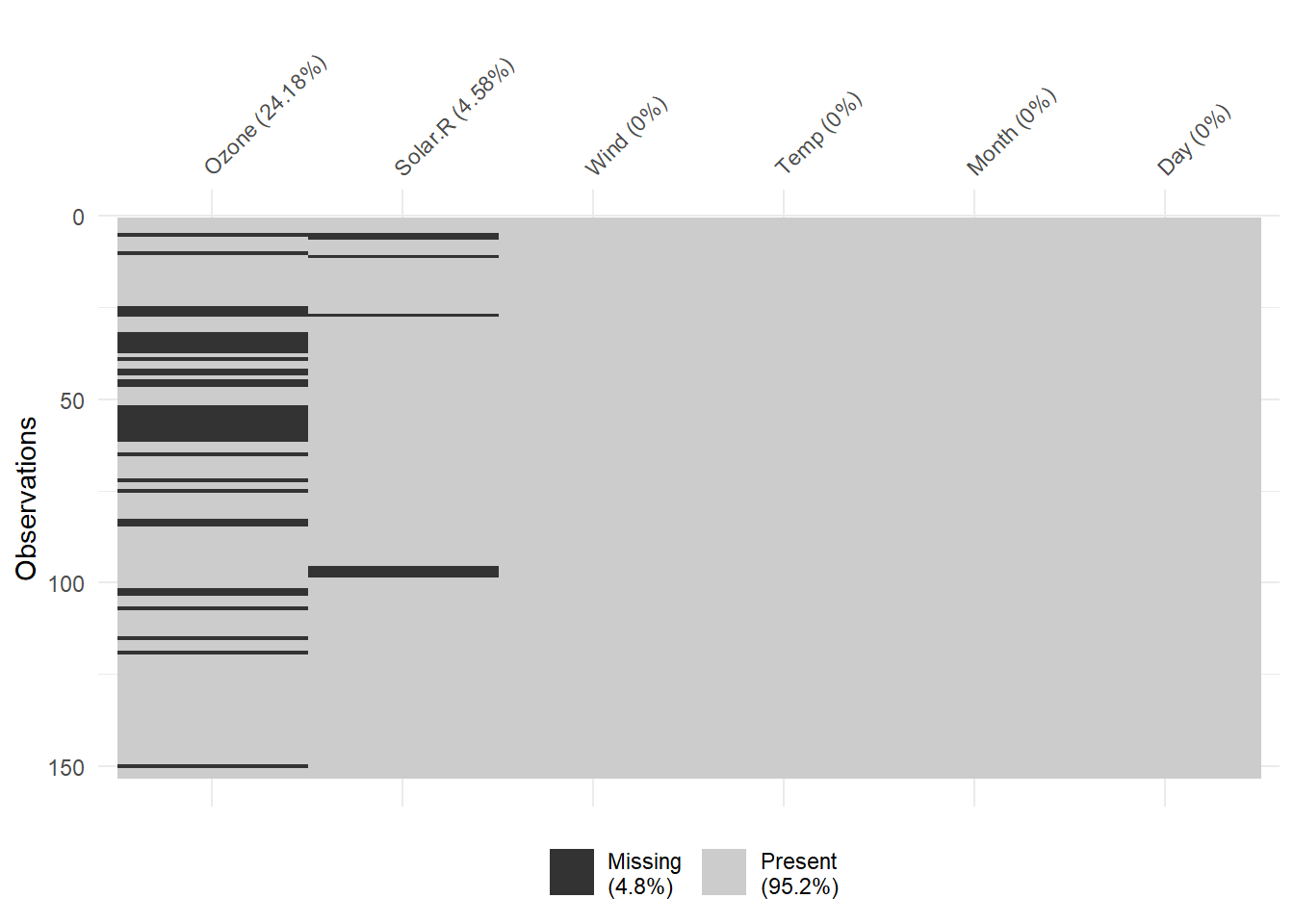
Tambien podemos ver valores perdidos y sus relaciones entre variables con naniar::gg_miss_upset().
5.4 Valores atipicos
5.4.1 Graficos de cajas
p1=WVPlots::ScatterBoxPlot(millas,"traccion","cilindrada",pt_alpha=0.5, title="Scatter/Box plot")
p2=WVPlots::ScatterBoxPlotH(millas,"cilindrada","fabricante",pt_alpha=0.5, title="Scatter/Box plot")
cowplot::plot_grid(p1,p2)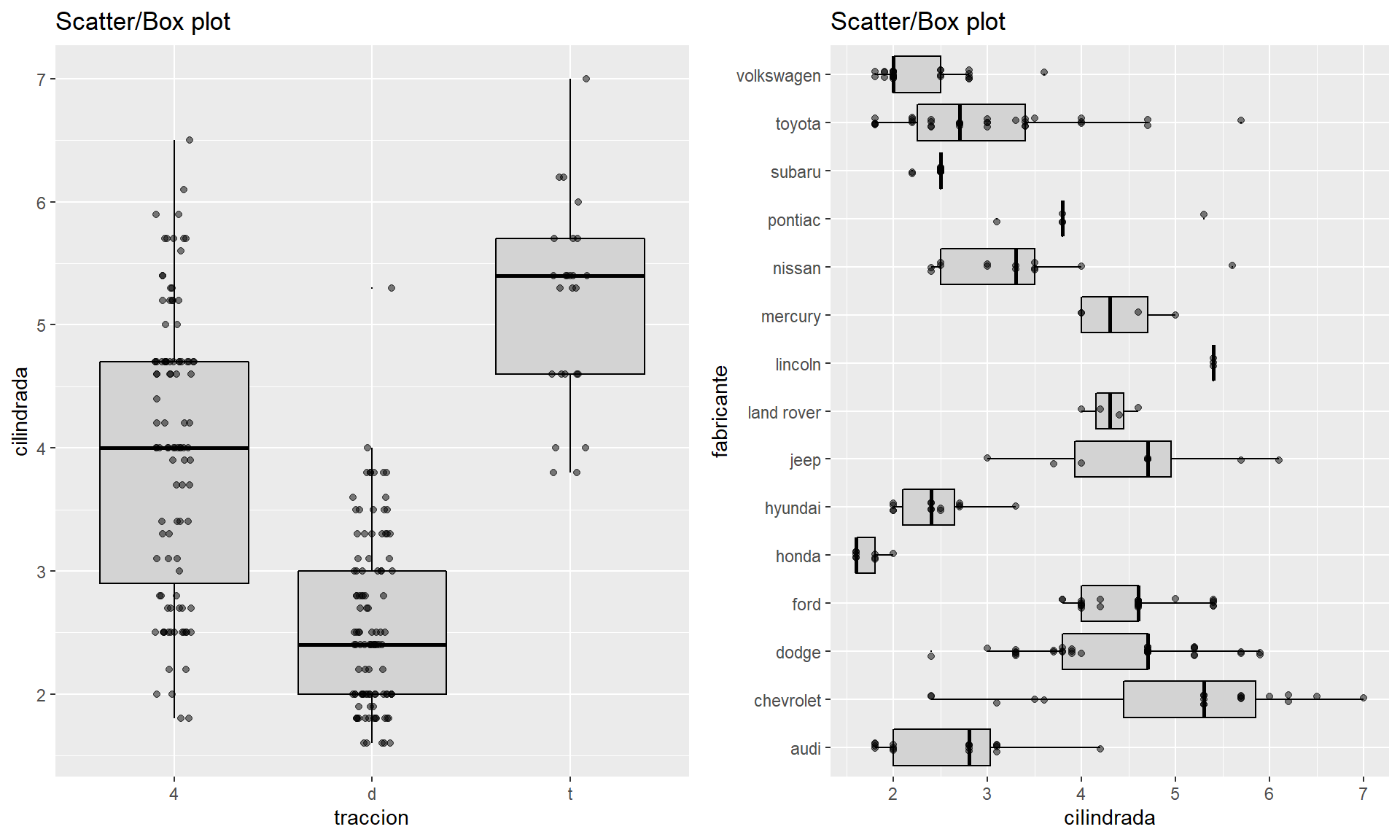
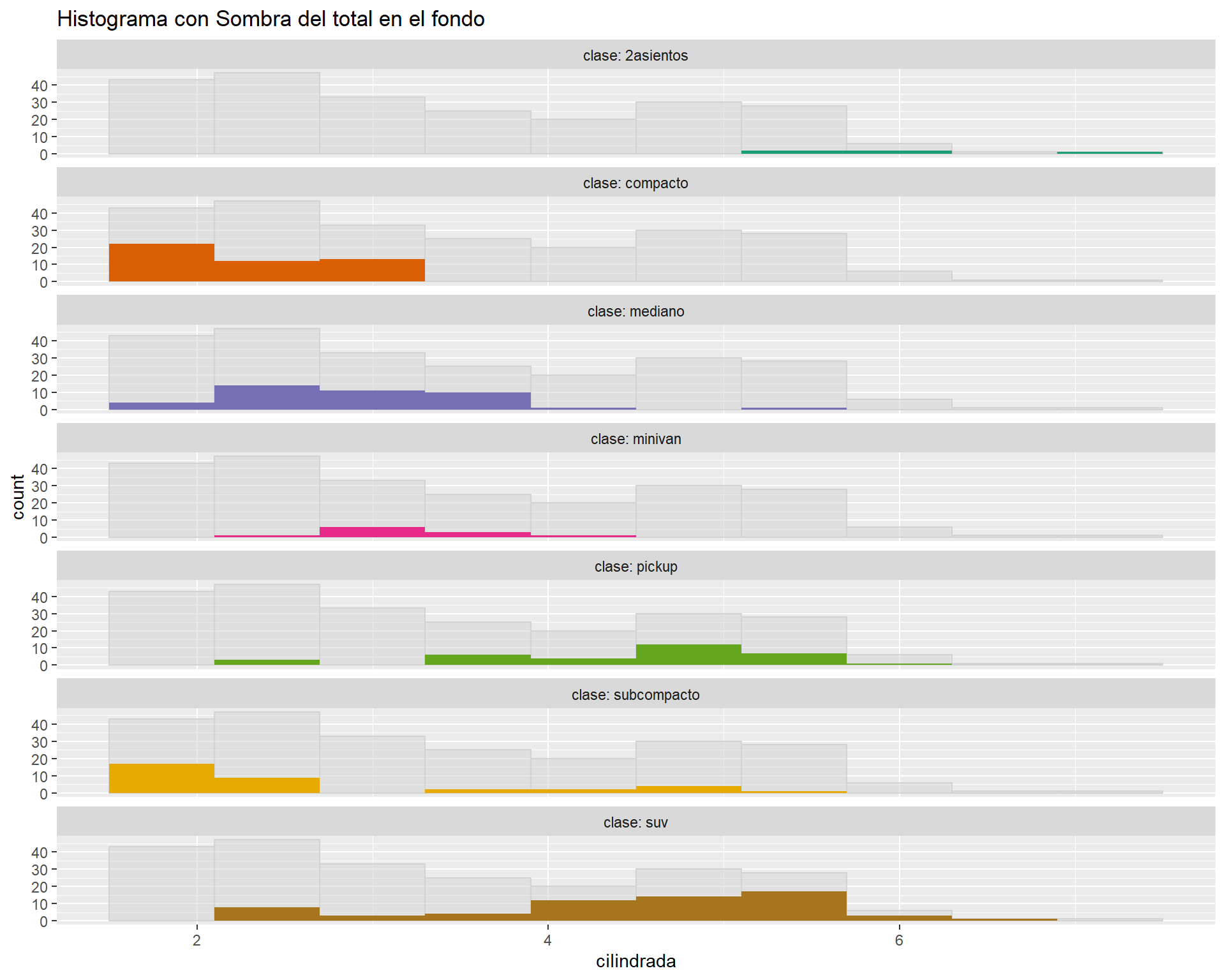
5.4.2 Histogramas de sombra
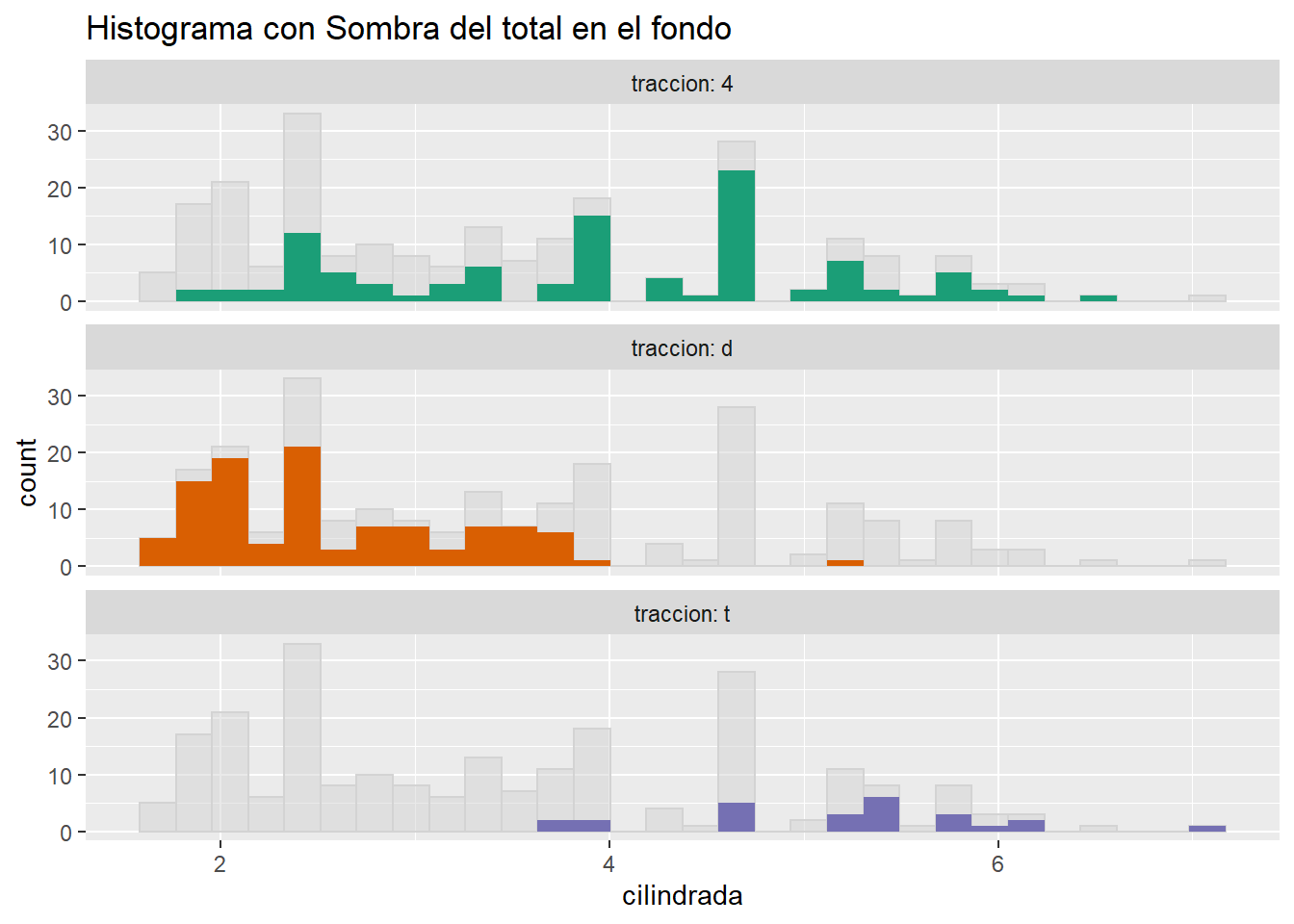
5.4.3 Violin charts
library(tidyverse)
library(hrbrthemes)
library(viridis)
p1=millas %>%
ggplot( aes(x=clase, y=cilindrada, fill=clase)) +
geom_violin() +
ggtitle("Basic Violin chart") +
xlab("")
p2=millas %>%
ggplot( aes(x=clase, y=cilindrada, fill=clase)) +
geom_violin() +
scale_fill_viridis(discrete = TRUE, alpha=0.6, option="A") +
ggtitle("Style Violin chart") +
xlab("")
cowplot::plot_grid(p1,p2)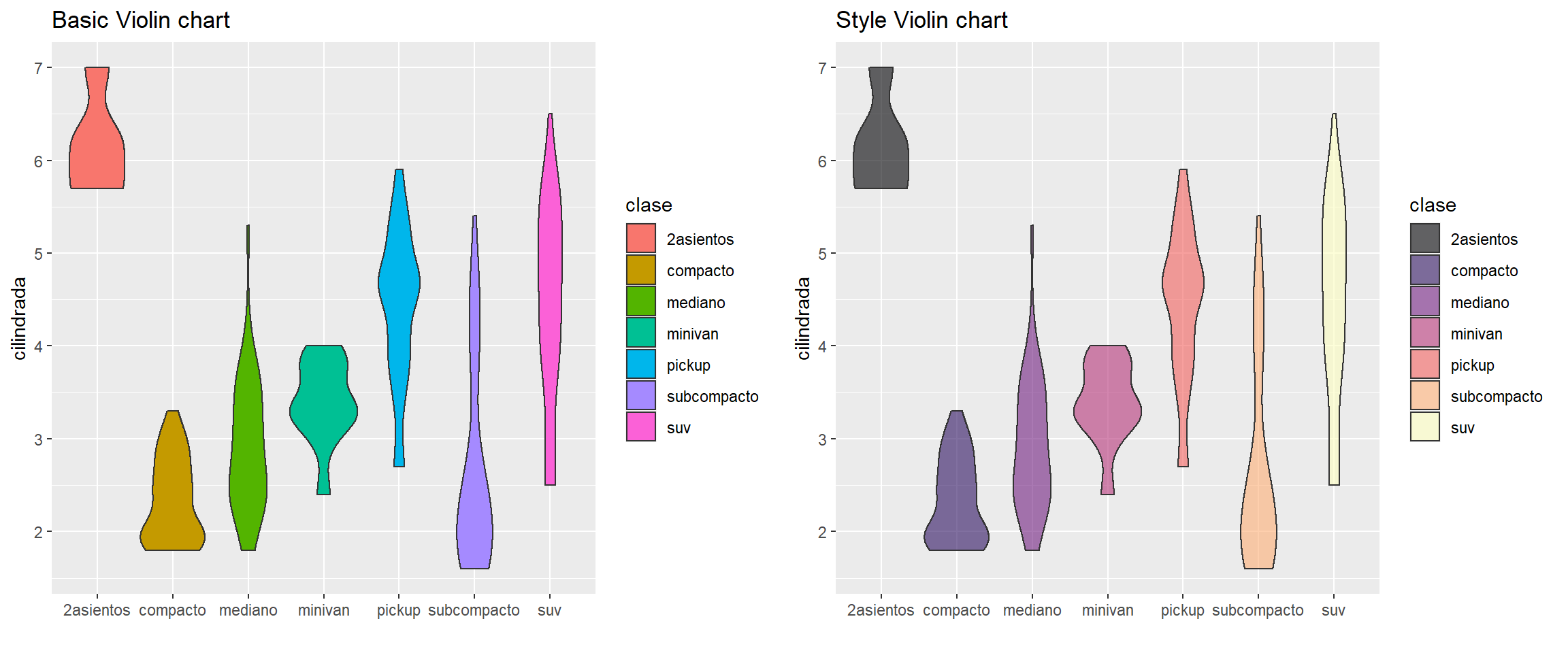
millas%>%
ggplot( aes(x=clase, y=cilindrada, fill=clase)) +
geom_violin(width=1.4) +
geom_boxplot(width=0.1, color="grey", alpha=0.2) +
scale_fill_viridis(discrete = TRUE) +
theme_ipsum() +
theme(
legend.position="none",
plot.title = element_text(size=11)
) +
ggtitle("A Violin wrapping a boxplot") +
xlab("")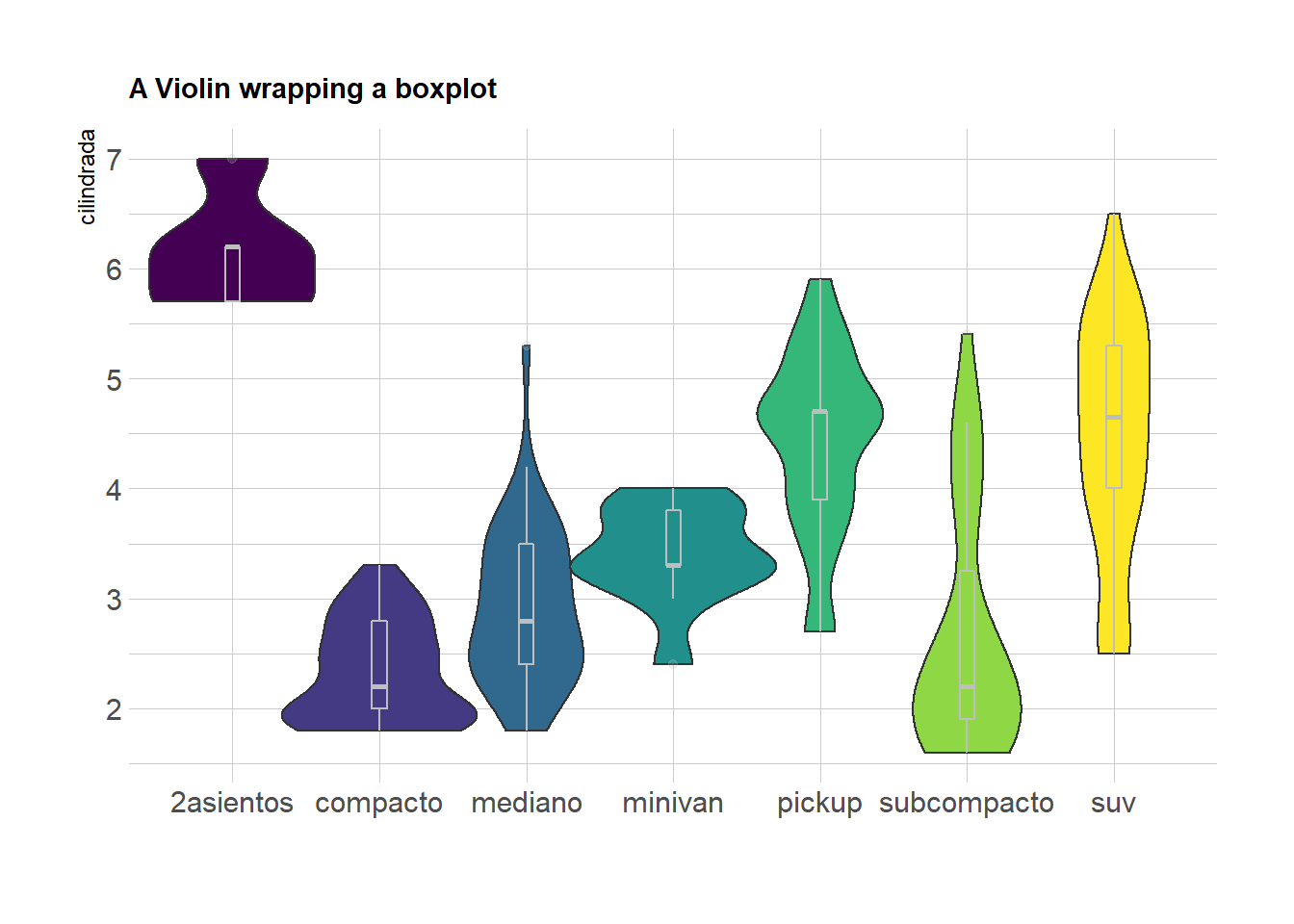
Datos
Format: Un data.frame con 336.776 filas y 19 columnas
anio:año de la fecha de salida
mes: mes de la fecha de salida
dia: día de la fecha de salida
horario_salida: horario efectivo de salida del vuelo (formato HHMM o HMM), hora local
salida_programada: horario programado para la salida (formato HHMM o HMM), hora local
atraso_salida: atraso de la salida en minutos. Valores negativos indican salida adelantada
horario_llegada: horario efectivo de llegada del vuelo (formato HHMM o HMM), hora local
llegada_programada: horario programado para la llegada (formato HHMM o HMM), hora local
atraso_llegada: atraso de la llegada en minutos. Valores negativos indican llegada adelantada
aerolinea: abreviación de dos letras de la aerolínea. Ver ‘aerolineas’ para obtener el nombre
vuelo: número de vuelo
codigo_cola: código de cola del avión
origen origen del vuelo. Ver ‘aeropuertos’ para metadatos adicionales
destino: destino del vuelo. Ver ‘aeropuertos’ para metadatos adicionales
tiempo_vuelo: cantidad de tiempo en aire, en minutos
distancia: distancia entre aeropuertos, en millas
hora: hora del horario programado para la salida
minuto: minutos del horario programado para la salida
fecha_hora: fecha y horario programados del vuelo en formato POSIXct
Rows: 336,776
Columns: 19
$ anio <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, ...
$ mes <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
$ dia <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
$ horario_salida <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558...
$ salida_programada <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600...
$ atraso_salida <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2,...
$ horario_llegada <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 75...
$ llegada_programada <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 74...
$ atraso_llegada <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3...
$ aerolinea <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", ...
$ vuelo <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79,...
$ codigo_cola <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN"...
$ origen <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR",...
$ destino <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL",...
$ tiempo_vuelo <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138,...
$ distancia <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944...
$ hora <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, ...
$ minuto <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0...
$ fecha_hora <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-...5.5 Dplyr - Uso de filter()
Recordar que R proporciona el conjunto estándar: >, >=, <, <=, != (no igual) y == (igual).
5.6 Funcion de filtrado filter()
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>5.6.1 Comparaciones
Para consultar valores numericos double. Lo siguiente resulta falso, cosa que suscede por la aproximacion que usa la computadora y como funciona R.
[1] FALSE[1] FALSEusar mejor near:
[1] TRUE[1] TRUE5.6.2 Operadores Logicos
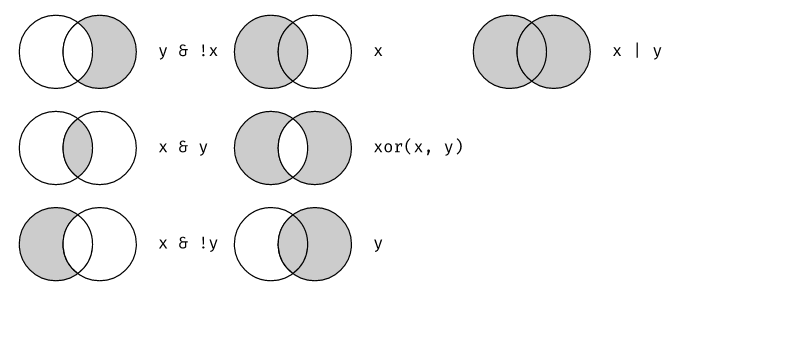
- Un ejemplo
El siguiente código sirve para encontrar todos los vuelos que partieron en noviembre o diciembre:
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 11 1 5 2359 6
2 2013 11 1 35 2250 105
3 2013 11 1 455 500 -5
4 2013 11 1 539 545 -6
5 2013 11 1 542 545 -3
6 2013 11 1 549 600 -11
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Tambien podemos hacerlo de la siguiente manera
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 11 1 5 2359 6
2 2013 11 1 35 2250 105
3 2013 11 1 455 500 -5
4 2013 11 1 539 545 -6
5 2013 11 1 542 545 -3
6 2013 11 1 549 600 -11
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Usando filter para texto
.
HOU IAH
2115 7198 5.6.3 Valores faltantes en filter()
filter() solo incluye filas donde la condición es TRUE; excluye tanto los valores FALSE como NA. Si deseas conservar valores perdidos, solicítalos explícitamente:
# A tibble: 1 x 1
x
<dbl>
1 3# A tibble: 2 x 1
x
<dbl>
1 NA
2 35.7 Dplyr - Uso de arrange()
vemos como originalmente estan los datos
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Vemos que ordena en funcion de la primera variable, es decir horario_salida.
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 4 10 1 1930 271
2 2013 5 22 1 1935 266
3 2013 6 24 1 1950 251
4 2013 7 1 1 2029 212
5 2013 1 31 1 2100 181
6 2013 2 11 1 2100 181
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Podriamos encontrarñe un buen uso para fechas.
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Ahora usamos para ordenar los datos de manera descendente
# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 9 641 900 1301
2 2013 6 15 1432 1935 1137
3 2013 1 10 1121 1635 1126
4 2013 9 20 1139 1845 1014
5 2013 7 22 845 1600 1005
6 2013 4 10 1100 1900 960
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>5.8 Dplyr - Uso de select()
Como en sql.
# A tibble: 6 x 3
anio mes dia
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1Seleccionar entre columnas
# A tibble: 6 x 3
anio mes dia
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1Seleccionar todas las columnas, excepto algunas entre un rango
# A tibble: 6 x 16
horario_salida salida_programa~ atraso_salida horario_llegada llegada_program~
<int> <int> <dbl> <int> <int>
1 517 515 2 830 819
2 533 529 4 850 830
3 542 540 2 923 850
4 544 545 -1 1004 1022
5 554 600 -6 812 837
6 554 558 -4 740 728
# ... with 11 more variables: atraso_llegada <dbl>, aerolinea <chr>,
# vuelo <int>, codigo_cola <chr>, origen <chr>, destino <chr>,
# tiempo_vuelo <dbl>, distancia <dbl>, hora <dbl>, minuto <dbl>,
# fecha_hora <dttm>Tambien tenemos otras funciones como:
starts_with(“abc”): coincide con los nombres que comienzan con “abc”.
ends_with(“xyz”): coincide con los nombres que terminan con “xyz”.
contains(“ijk”): coincide con los nombres que contienen “ijk”.
matches(“(.)\1”): selecciona variables que coinciden con una expresión regular. Esta en particular coincide con cualquier variable que contenga caracteres repetidos. Aprenderás más sobre expresiones regulares en Cadenas de caracteres.
num_range(“x”, 1:3): coincide con x1,x2 y x3.
Otra opción es usar select() junto con el auxiliar everything() (todo, en inglés). Esto es útil si se tiene un grupo de variables que se busca mover al comienzo del data frame.
# A tibble: 6 x 19
fecha_hora tiempo_vuelo anio mes dia horario_salida
<dttm> <dbl> <int> <int> <int> <int>
1 2013-01-01 05:00:00 227 2013 1 1 517
2 2013-01-01 05:00:00 227 2013 1 1 533
3 2013-01-01 05:00:00 160 2013 1 1 542
4 2013-01-01 05:00:00 183 2013 1 1 544
5 2013-01-01 06:00:00 116 2013 1 1 554
6 2013-01-01 05:00:00 150 2013 1 1 554
# ... with 13 more variables: salida_programada <int>, atraso_salida <dbl>,
# horario_llegada <int>, llegada_programada <int>, atraso_llegada <dbl>,
# aerolinea <chr>, vuelo <int>, codigo_cola <chr>, origen <chr>,
# destino <chr>, distancia <dbl>, hora <dbl>, minuto <dbl>5.9 Dplyr - uso de mutate()
Sirve para crear nuevas variables, viene del ingles mutar o transformar)
- Creamos un dataset pequeño
vuelos_sml <- select(vuelos,
anio:dia,
starts_with("atraso"),
distancia,
tiempo_vuelo
)
vuelos_sml %>%
names()[1] "anio" "mes" "dia" "atraso_salida"
[5] "atraso_llegada" "distancia" "tiempo_vuelo" - Ahora creamos las nuevas variables
mutate(vuelos_sml,
ganancia = atraso_salida - atraso_llegada,
velocidad = distancia / tiempo_vuelo * 60
) %>%
head()# A tibble: 6 x 9
anio mes dia atraso_salida atraso_llegada distancia tiempo_vuelo ganancia
<int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 2 11 1400 227 -9
2 2013 1 1 4 20 1416 227 -16
3 2013 1 1 2 33 1089 160 -31
4 2013 1 1 -1 -18 1576 183 17
5 2013 1 1 -6 -25 762 116 19
6 2013 1 1 -4 12 719 150 -16
# ... with 1 more variable: velocidad <dbl>mutate(vuelos_sml,
ganancia = atraso_salida - atraso_llegada,
velocidad = distancia / tiempo_vuelo * 60
) %>%
names()[1] "anio" "mes" "dia" "atraso_salida"
[5] "atraso_llegada" "distancia" "tiempo_vuelo" "ganancia"
[9] "velocidad" - Si solo se busca conservar las nuevas variables, usar transmute():
transmute(vuelos,
ganancia = atraso_salida - atraso_llegada,
horas = tiempo_vuelo / 60,
ganancia_por_hora = ganancia / horas
)%>%
head()# A tibble: 6 x 3
ganancia horas ganancia_por_hora
<dbl> <dbl> <dbl>
1 -9 3.78 -2.38
2 -16 3.78 -4.23
3 -31 2.67 -11.6
4 17 3.05 5.57
5 19 1.93 9.83
6 -16 2.5 -6.4 Operadores usados:
Operadores aritméticos: +, -,*,/,^.
Funciones: min(), max(), sum(), mean(), var(), sd(), sqrt(), etc.
Aritmética modular: %/% (división entera) y %% (resto).
# A tibble: 6 x 1
horario_salida
<int>
1 517
2 533
3 542
4 544
5 554
6 554Vemos que la hora esta junta, como 517, esto en verdad es 5:17 por lo que usando aritmetica modular podemos visualizarlo
transmute(vuelos,
horario_salida,
hora = horario_salida %/% 100,
minuto = horario_salida %% 100
) %>%
head()# A tibble: 6 x 3
horario_salida hora minuto
<int> <dbl> <dbl>
1 517 5 17
2 533 5 33
3 542 5 42
4 544 5 44
5 554 5 54
6 554 5 54Algunas funciones extras:
Logaritmos: log(), log2(), log10()
Rezagos: lead() y lag()
Agregados acumulativos y móviles: R proporciona funciones para ejecutar sumas, productos, mínimos y máximos: cumsum(), cumprod(), cummin(), cummax(); dplyr, por su parte, proporciona cummean() para las medias acumuladas. Si necesitas calcular agregados móviles (es decir, una suma calculada en una ventana móvil), prueba el paquete RcppRoll.
Ordenamiento: hay una serie de funciones de ordenamiento (ranking), pero deberías comenzar con min_rank(). Esta función realiza el tipo más común de ordenamiento (por ejemplo, primero, segundo, tercero, etc.). El valor predeterminado otorga la menor posición a los valores más pequeños; usa desc(x) para dar la menor posición a los valores más grandes.
Si min_rank() no hace lo que necesitas, consulta las variantes row_number(), dense_rank(), percent_rank(), cume_dist(),quantile(). Revisa sus páginas de ayuda para más detalles.
5.10 Dplyr - uso de summarise()
5.10.1 summarise()
El último verbo clave es summarise() (resumir, en inglés). Se encarga de colapsar un data frame en una sola fila:
# A tibble: 1 x 1
atraso
<dbl>
1 12.6summarise() no es muy útil a menos que lo enlacemos con group_by(). Esto cambia la unidad de análisis del conjunto de datos completo a grupos individuales. Luego, cuando uses los verbos dplyr en un data frame agrupado, estos se aplicarán automáticamente “por grupo”. Por ejemplo, si aplicamos exactamente el mismo código a un data frame agrupado por fecha, obtenemos el retraso promedio por fecha:
# A tibble: 6 x 19
# Groups: anio, mes, dia [1]
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Ahora aplicamos summarise:
# A tibble: 6 x 4
# Groups: anio, mes [1]
anio mes dia atraso
<int> <int> <int> <dbl>
1 2013 1 1 11.5
2 2013 1 2 13.9
3 2013 1 3 11.0
4 2013 1 4 8.95
5 2013 1 5 5.73
6 2013 1 6 7.15Vemos como se calcula el promedio de atraso por dia.
5.10.2 operaciones con el pipe %>%
Podriamos escribir todo eso para explorar la relación entre la distancia y el atraso promedio para cada ubicación.
por_destino <- group_by(vuelos, destino)
atraso <- summarise(por_destino,
conteo = n(),
distancia = mean(distancia, na.rm = TRUE),
atraso = mean(atraso_llegada, na.rm = TRUE)
)
atraso <- filter(atraso, conteo > 20, destino != "HNL")
ggplot(data = atraso, mapping = aes(x = distancia, y = atraso)) +
geom_point(aes(size = conteo), alpha = 1/3) +
geom_smooth(se = FALSE)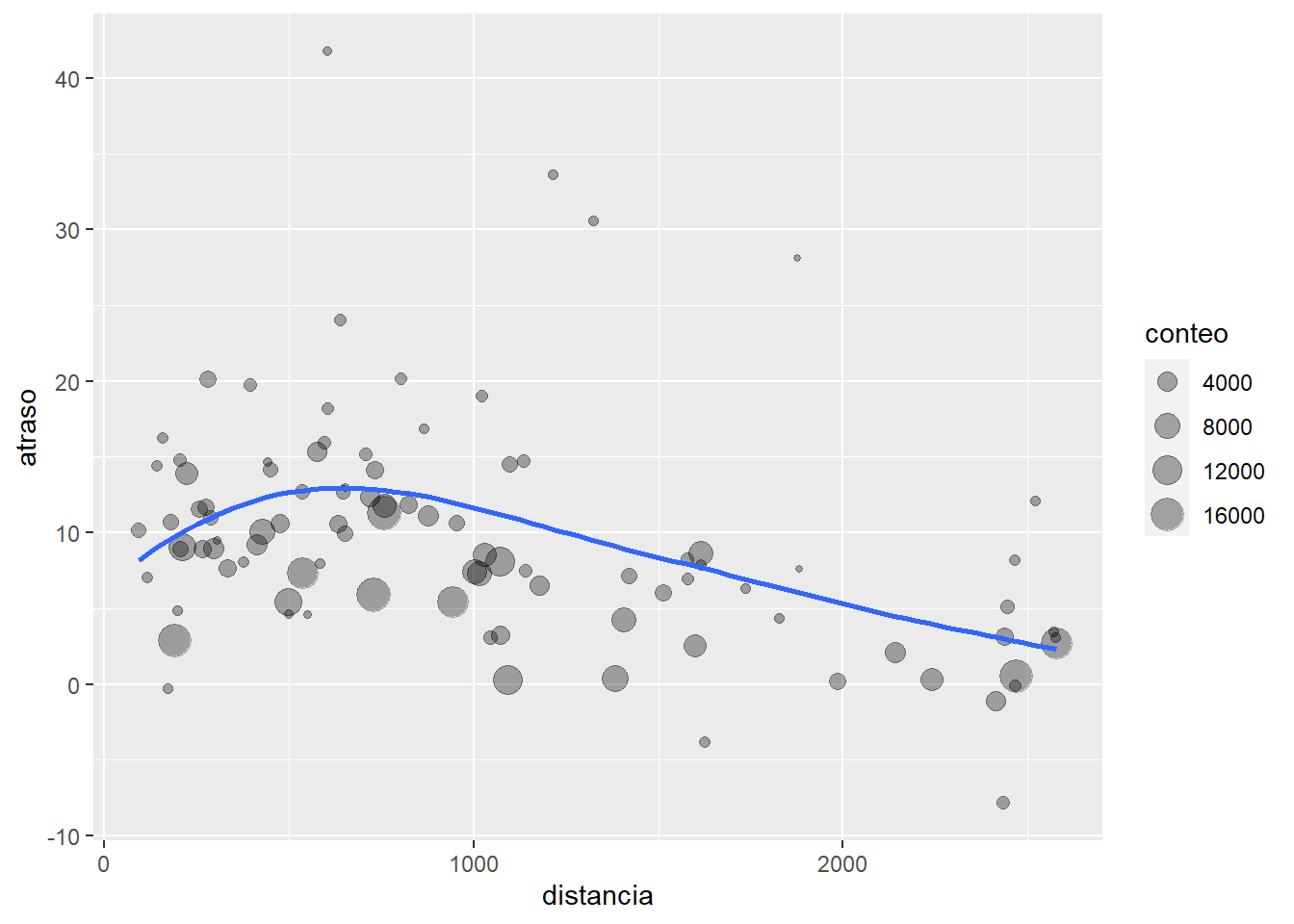
O podemos hacerlo de la siguiente manera con el pipe %>% que se lee
atrasos <- vuelos %>%
group_by(destino) %>%
summarise(
conteo = n(),
distancia = mean(distancia, na.rm = TRUE),
atraso = mean(atraso_llegada, na.rm = TRUE)
) %>%
filter(conteo > 20, destino != "HNL")Este código se enfoca en las transformaciones, no en lo que se está transformando, lo que hace que sea más fácil de leer. Puedes leerlo como una serie de declaraciones imperativas: agrupa, luego resume y luego filtra. Como sugiere esta lectura, una buena forma de pronunciar %>% cuando se lee el código es “luego”.
5.11 Trato Valores faltantes
Un error en el promedio? Es probable que tengamos NAs.
# A tibble: 6 x 4
# Groups: anio, mes [1]
anio mes dia mean
<int> <int> <int> <dbl>
1 2013 1 1 NA
2 2013 1 2 NA
3 2013 1 3 NA
4 2013 1 4 NA
5 2013 1 5 NA
6 2013 1 6 NAPor eso es recomendable usar el na.rm para las funciones de agregacion.
vuelos %>%
group_by(anio, mes, dia) %>%
summarise(mean = mean(atraso_salida, na.rm = TRUE)) %>%
head()# A tibble: 6 x 4
# Groups: anio, mes [1]
anio mes dia mean
<int> <int> <int> <dbl>
1 2013 1 1 11.5
2 2013 1 2 13.9
3 2013 1 3 11.0
4 2013 1 4 8.95
5 2013 1 5 5.73
6 2013 1 6 7.15Creamos un conjunto de datos:
no_cancelados <- vuelos %>%
filter(!is.na(atraso_salida), !is.na(atraso_llegada))
no_cancelados %>%
head()# A tibble: 6 x 19
anio mes dia horario_salida salida_programa~ atraso_salida
<int> <int> <int> <int> <int> <dbl>
1 2013 1 1 517 515 2
2 2013 1 1 533 529 4
3 2013 1 1 542 540 2
4 2013 1 1 544 545 -1
5 2013 1 1 554 600 -6
6 2013 1 1 554 558 -4
# ... with 13 more variables: horario_llegada <int>, llegada_programada <int>,
# atraso_llegada <dbl>, aerolinea <chr>, vuelo <int>, codigo_cola <chr>,
# origen <chr>, destino <chr>, tiempo_vuelo <dbl>, distancia <dbl>,
# hora <dbl>, minuto <dbl>, fecha_hora <dttm>Ya no tenemos el error con los NAS.
# A tibble: 6 x 4
# Groups: anio, mes [1]
anio mes dia mean
<int> <int> <int> <dbl>
1 2013 1 1 11.4
2 2013 1 2 13.7
3 2013 1 3 10.9
4 2013 1 4 8.97
5 2013 1 5 5.73
6 2013 1 6 7.155.12 Conteos
Siempre que realices una agregación, es una buena idea incluir un conteo (n()) o un recuento de valores no faltantes (sum(!is.na(x))). De esta forma, puedes verificar que no estás sacando conclusiones basadas en cantidades muy pequeñas de datos. Por ejemplo, veamos los aviones (identificados por su número de cola) que tienen las demoras promedio más altas:
atrasos <- no_cancelados %>%
group_by(codigo_cola) %>%
summarise(
atraso = mean(atraso_llegada)
)
ggplot(data = atrasos, mapping = aes(x = atraso)) +
geom_freqpoly(binwidth = 10)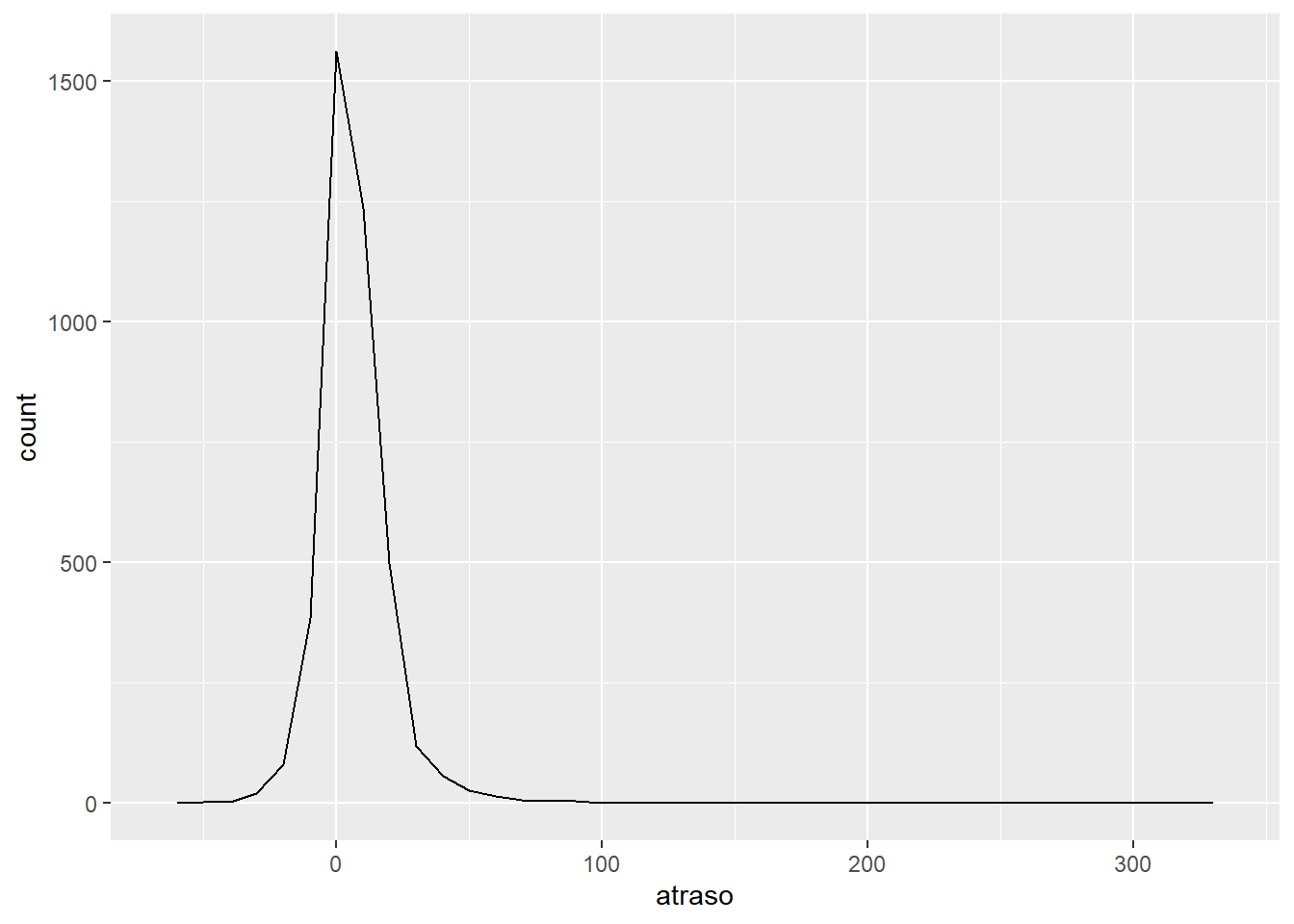
¡Hay algunos aviones que tienen una demora promedio de 5 horas (300 minutos)!
Podemos verlo de otra manera, estamos agrupando por codigo de cola,guardaremos una variable con el promedio de atraso de llegada y otra con conteos
atrasos <- no_cancelados %>%
group_by(codigo_cola) %>%
summarise(
atraso = mean(atraso_llegada, na.rm = TRUE),
n = n()
)
atrasos %>%
head()# A tibble: 6 x 3
codigo_cola atraso n
<chr> <dbl> <int>
1 D942DN 31.5 4
2 N0EGMQ 9.98 352
3 N10156 12.7 145
4 N102UW 2.94 48
5 N103US -6.93 46
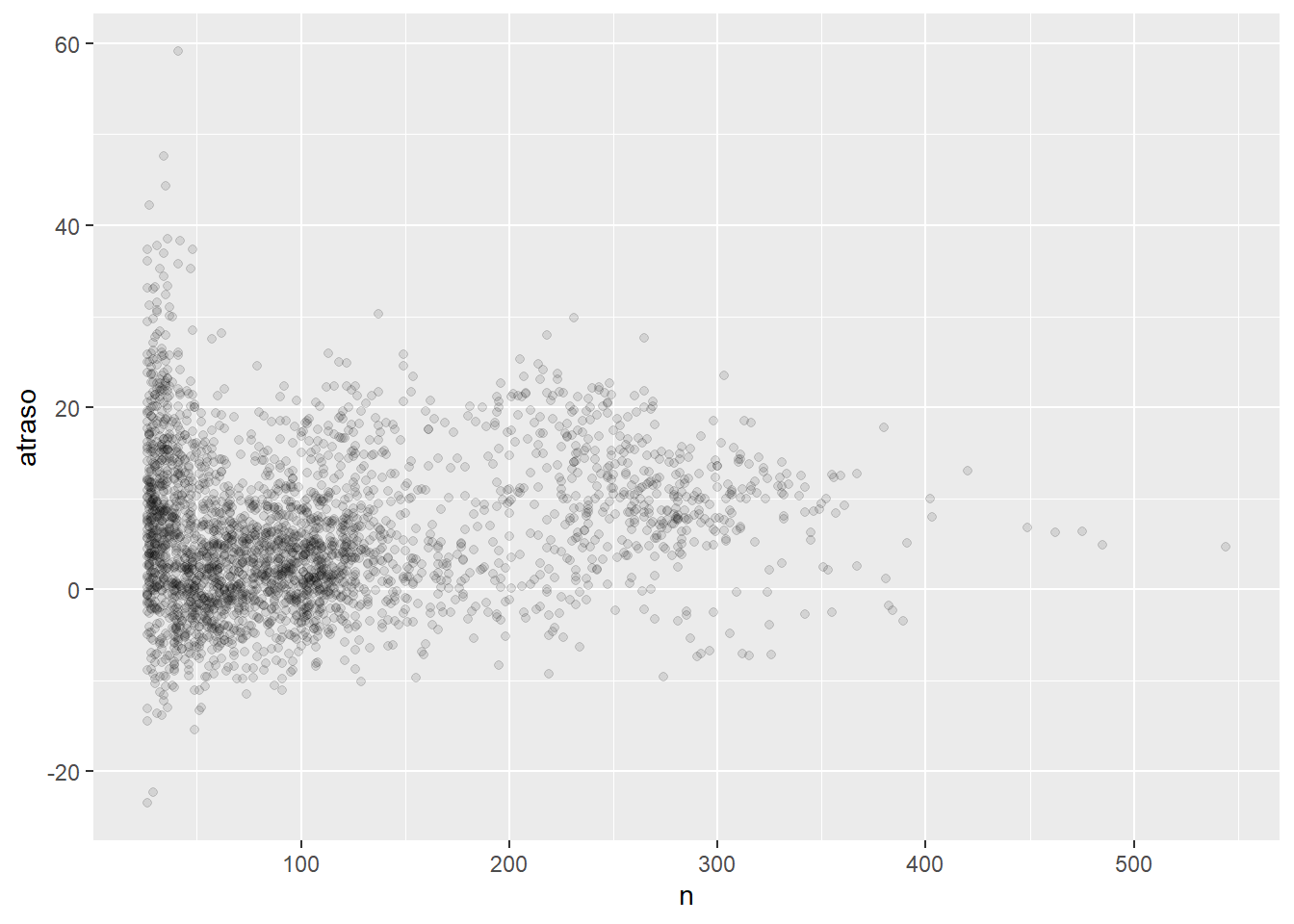
6 N104UW 1.80 46Visualizaremos esos conteos en funcion del promedio:
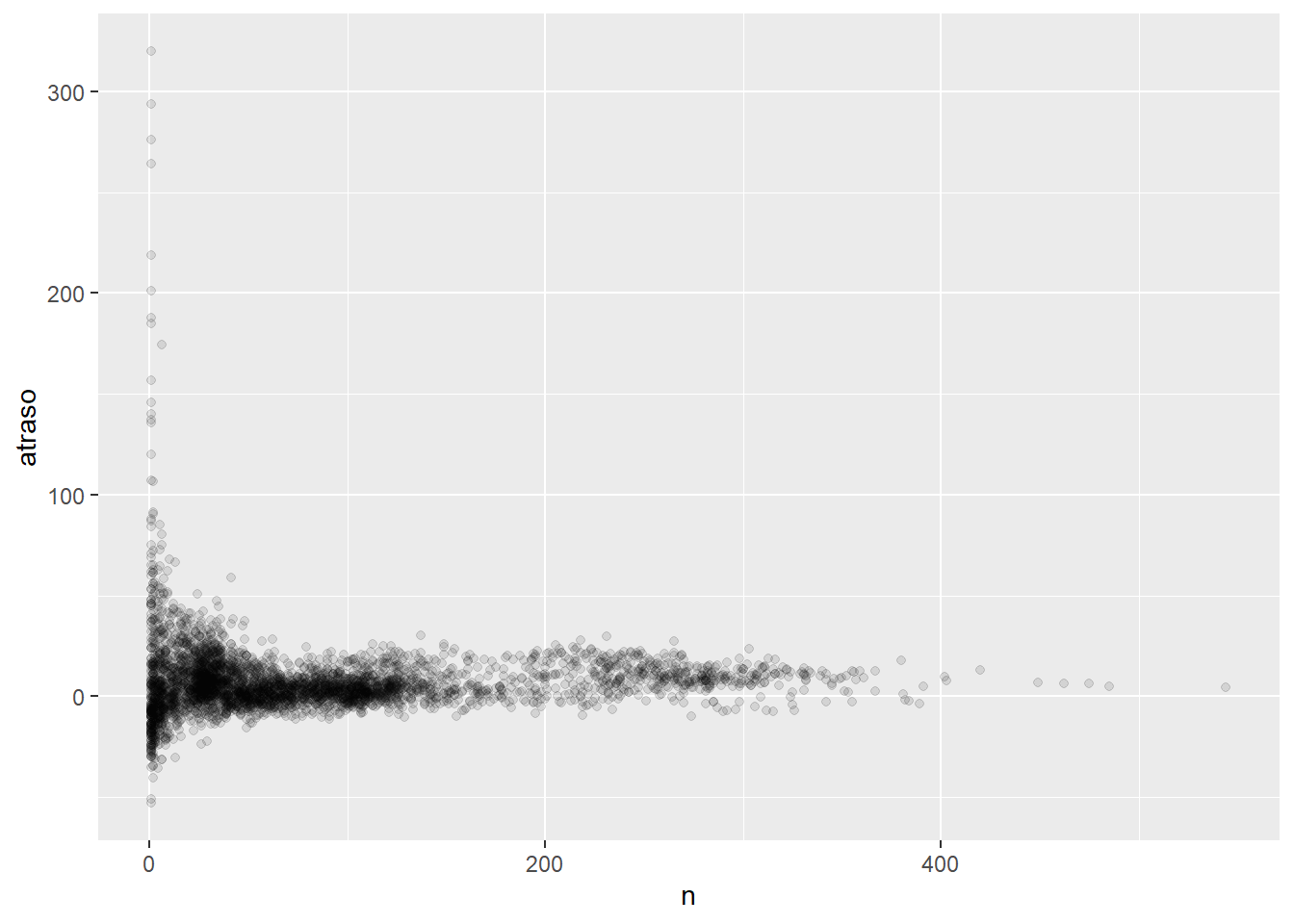
Vemos que para pocos vuelos, el tiempo promedio de atraso varia mas.
- Ojo:
cuando trazas un promedio (o cualquier otra medida de resumen) contra el tamaño del grupo, verás que la variación decrece a medida que el tamaño de muestra aumenta.
- TIP:
Cuando se observa este tipo de gráficos, resulta útil eliminar los grupos con menor número de observaciones, ya que puedes ver más del patrón y menos de la variación extrema de los grupos pequeños.
En la data atrasos, filtramos los conteos de vuelos superiores a 25, luego ploteamos el grafico anterior pero sin estos valores pequeños.