1 Introdução
Uma abordagem inicial sobre o pacote Shiny e Machine Learning.
1.1 Shiny
Primeiramente, vamos entender como funciona a estrutura de um aplicativo Shiny. Na criação de qualquer aplicativo, é necessário que se tenha uma interface, que no caso do pacote Shiny é chamado de interface do usuário (ui), ou seja, é a parte com a qual o usuário interage.
Para criar seu primeiro aplicativo em Shiny, você precisa instalar o pacote Shiny.
install.packages("shiny")Em seguida deve carregar o pacote.
library(shiny)A criação de uma interface (ou layout) em Shiny pode ser desde a mais simples até a mais sofisticada, utilizando apenas recursos do pacote Shiny é possível criar um bom layout para seu aplicativo.
Neste tutorial abordo as principais funções disponíveis no pacote Shiny para criação da interface do aplicativo, assim como outras funções de pacotes auxiliares que estão disponíveis nas bibliotecas R.
O servidor (ou server) é outra parte que compõe uma aplicação Shiny, é nessa parte da aplicação que toda a estrutura computacional funciona, é onde está o código utilizado na análise e onde o aplicativo reage de acordo com a solicitaçao do usuário. É nessa parte que é criado a função reatividade que será abordada mais adiante.
É no server que tudo acontece, a partir da solicitação realizada pelo usuário, a função server reage permitindo interações reativas entre a modelagem de entradas e resultados. Utilizando o pacote Shiny é possível interagir com linguagens externas ao R, como por exemplo CSS, JavaScript e HTML.
Essa é a estrutura de um aplicativo em Shiny.
ui <- fluidPage(
titlePanel("Olá Shiny!")
)
server <- function(input, output, session ){
}
shinyApp(ui = ui, server = server)
Figure 1.1: Estrutura básica de um aplicativo Shiny.
Fonte: Elaborado pela Autora.
Observe que não foi utilizado nenhum estrutura server nesta situação.
1.2 Machine Learning
Machine Learning é uma área da inteligência artificial onde sistemas têm a capacidade de aprender por meio associações de diferentes dados, imagens, entre outras. Os tipos de aprendizagem são divididos em quatro: supervisionada, semi-supervisionada, não supervisionada e de reforço. Nesse tutorial é abordado a aprendizagem supervisionada, mas veremos um breve descrição das quatro.
A aprendizagem supervisionada, baseia-se na classificação e regressão, onde a partir de um determinado banco de dados a máquina é ensinada a aprender com aqueles dados, a partir daí é realizado o teste para verificar quanto a máquina aprendeu, para isso existe vários modelos de aprendizagem, quais serão descritos mais adiante. O problema da aprendizagem supervisionada é que o modelo pode se ajustar demais aos dados o que pode resultar em viés.
Os modelos de classificação são avaliados usando métricas como acurácia, precisão, Curva ROC, entre outras, que são obtidas a partir de uma matriz de confusão que tem como objetivo retornar o total de erros e/ou acertos que o modelo cometeu ao realizar a classificação. A métrica utilizada depende da situação que se deseja avaliar, a Figura 1.2 demonstra uma matriz de confusão.

Figure 1.2: Exemplo de uma matriz de confusão.
Fonte: https://vitorborbarodrigues.medium.com/
A métrica que será utilizada é a Curva ROC (ou AUC) que é interpretada pelo o valor obtido a partir da área sob a Curva Roc, quanto maior for essa área sob a curva maior a AUC. Para calcular a curva Roc é necessário calcular as probabilidades de cada observação pertencer a determinada classe. A Figura 1.3 ilustra uma curva ROC.
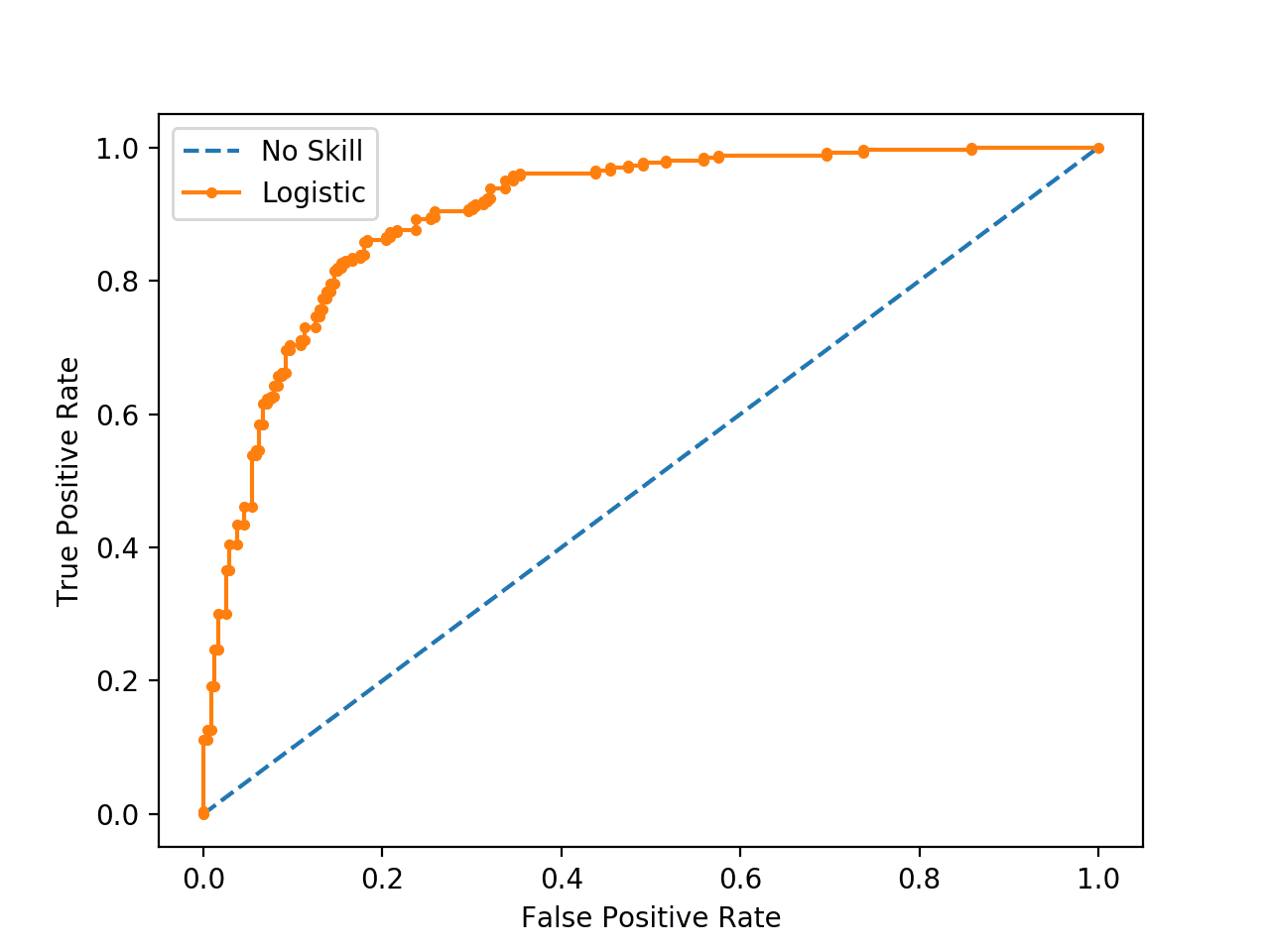
Figure 1.3: Representação de uma Curva ROC.
Fonte: https://machinelearningmastery.com/
Nos modelos de regressão pode-se utilizar as métricas de R-Squared (R quadrado), a mais comum que verifica quão bem o modelo de regressão explica os dados observados e o RMSE que é a raiz quadrada da variância dos resíduos e calculada conforme Figura 1.4.
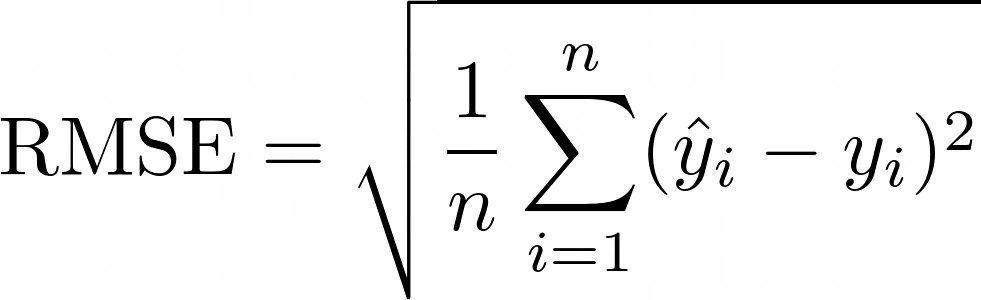
Figure 1.4: Equação da Raiz do Erro Quadrático Médio.
Fonte: https://medium.com/
A Raiz do Erro Quadrático Médio, é comumente usada para expressar a acurácia dos resultados numéricos do modelo. Portanto, como é um erro, quanto maior for o seu valor, pior o desempenho do modelo.
Os modelos de aprendizagem supervisionada abordados neste tutorial são:
- Árvore de decisão
- Floresta Aleatória (Random Forest)
- K-ésimo Vizinho mais Próximo (K-Nearest Neighbors)
- Regressão logística
- Regressão linear
- eXtreme Gradient Boosting (XGBoost)
Sendo a Regressão logística utilizada apenas para classificação, enquanto a Regressão Linear é um modelo apenas de regressão. Os demais modelos são utlizados tanto para classificação quanto para regressão.
A aprendizagem semi-supervisionada é um tipo de aprendizado útil para situações onde amostras rotuladas não são facilmente obtidas quando comparado a amostras não rotuladas, que por sua vez são mais baratas e fáceis de serem obtidas. A aprendizagem semi-supervisionada visa trabalhar com conjunto de dados, no qual a maioria dos dados não estão rotulados como pertencentes a uma determinada classe.
Na aprendizagem não supervisionada a máquina inicia a análise dos dados sozinha e começa a identificar padrões, no decorrer do tempo ela começa a distinguir as informações uma das outras, com intuito de formar grupos com as observações semelhantes, esse processo pode ser demorado e é um dos motivos pelo qual esse tipo de aprendizagem não é das mais utilizadas.
O aprendizado por reforço é como se fosse a apredizagem pela experiência, onde o algoritmo recebe uma recompensa por cada ação correta e recebe uma penalidade por cada ação errada. Dessa maneira a máquina deve lidar com erro cometido e procurar uma abordagem correta.
1.2.1 Pacote Tidymodels
O pacote Tidymodels é uma evolução do pacote Caret, ele foi criado por Max Kuhn e Hadley Wickham para modelagem e análise estatística. Ao instalar o pacote um conjunto de outros pacote são instalados juntos, os principais pacotes são:
rsample fornece infraestrutura para divisão e reamostragem eficientes de dados.
parsnip é uma interface organizada e unificada para modelos que podem ser usados para experimentar uma variedade de outros modelos.
recipes utiliza ferramentas de pré-processamento de dados para engenharia de recursos.
workflows faz o unificação do pré-processamento, modelagem e pós-processamento.
tune otimiza os hiperparâmetros de seu modelo e as etapas de pré-processamento.
yardstick mede a eficácia dos modelos usando métricas de desempenho.
broom converte as informações em objetos estatísticos comuns do R em formatos previsíveis e fáceis de usar.
dials cria e gerencia parâmetros de ajuste e grades de parâmetros.
Resumidamente o Tidymodels é uma pacote de pacotes, criado como uma versão Tidyverse do Caret.