Achievement 1: Using exploratory data analysis for multinomial logistic regression (Section 11.4)
Achievement 2: Estimating and interpreting a multinomial logistic regression model (Section 11.5)
Achievement 3: Checking assumptions for multinomial logistic regression (Section 11.6)
Achievement 4: Using exploratory data analysis for ordinal logistic regression (Section 11.7)
Achievement 5: Estimating and interpreting an ordinal logistic regression models (Section 11.8)
Achievement 6: Checking assumptions for ordinal logistic regression (Section 11.9)
Objectives 11.1: Achievements for chapter 11
11.2 The diversity dilemma in STEM
There is a lack of diversity in the science, technology, engineering, and math (STEM) fields and specifically about the lack of women. There are fewer women college graduates in computer science and math jobs now compared to 15 years ago.
There are three main reasons cited for fewer women in STEM:
beliefs about natural ability,
societal and cultural norms,
and institutional barriers.
One thing that appeared to encourage women in STEM is the visibility of other women in STEM careers.
11.3 Resources & Chapter Outline
11.3.1 Data, codebook, and R packages
Data, codebook, and R packages for learning about descriptive statistics
Data
Three options for accessing the data:
Download and save the original SAS file stem-nsf-2017-ch11.xpt from https://edge.sagepub.com/harris1e and run the code in the first code chunk to clean the data.
Download and save the original SAS file stem-nsf-2017-ch11.xpt from https://edge.sagepub.com/harris1e and follow the steps in Box 11.1 to clean the data.
Download and save the original 2017 National Survey of College Graduates data from the National Science Foundation’s SESTAT Data Tool (https://ncsesdata.nsf.gov/datadownload/) and follow Box 11.1 to clean the data.
As there is nothing new for me in the recoding procedures I will go for the first option.
Use the version that comes when downloading the raw data file from the National Science Foundation’s SESTAT Data Tool (https://ncsesdata.nsf.gov/datadownload/)
Packages
Packages used with the book (sorted alphabetically)
The variable names were not converted to lower case. So I had to change all variable names in the following recoding.
The {haven} function was extremely slow! In contrast to sasxport.get() with 3.94 seconds the file export took 104.12 second, e.g. more than 26 times longer!
I got with the export of a SAS transport file a labelled data frame with very long labels. After the recoding I lost many of these labels except of two columns. Therefore I used haven::zap_label() to remove all variable labels.
The original data file is too big for GitHub
After I committed to GitHub I got an error, because the file stem-nsf-2017-ch11.xpt was too large. I compressed it as .zip-file and changed the import code slightly to adapt this change. After testing that it worked I deleted the uncompressed file.
Using the {forcats} package
I changed the factor levels in the RecSatis() function with the {forcats} package.
11.3.3 Show raw data
Example 11.1 : Show summary of recoded data for chapter 11
R Code 11.2 : Show recoded data for chapter 11 (tbl11.1)
Code
tbl11.1<-base::readRDS("data/chap11/tbl11.1.rds")glue::glue("********** Summarizing with base:summary() **************")base::summary(tbl11.1)glue::glue(" ")glue::glue(" ")glue::glue("********** Summarizing with skimr::skim() **************")glue::glue(" ")skimr::skim(tbl11.1)
#> ********** Summarizing with base:summary() **************
#> age job_cat satis_advance
#> Min. :20.00 CS, Math, Eng :17223 Very satisfied :16980
#> 1st Qu.:32.00 Other Sciences: 7642 Somewhat satisfied :30443
#> Median :44.00 Nonscience :31043 Somewhat dissatisfied:15632
#> Mean :45.53 NA's :27764 Very dissatisfied : 6576
#> 3rd Qu.:58.00 NA's :14041
#> Max. :75.00
#> satis_salary satis_contrib sex
#> Very satisfied :21073 Very satisfied :35124 Male :45470
#> Somewhat satisfied :34453 Somewhat satisfied :25341 Female:38202
#> Somewhat dissatisfied: 9854 Somewhat dissatisfied: 6774
#> Very dissatisfied : 4251 Very dissatisfied : 2392
#> NA's :14041 NA's :14041
#>
#>
#>
#> ********** Summarizing with skimr::skim() **************
#>
Data summary
Name
tbl11.1
Number of rows
83672
Number of columns
6
_______________________
Column type frequency:
factor
5
numeric
1
________________________
Group variables
None
Variable type: factor
skim_variable
n_missing
complete_rate
ordered
n_unique
top_counts
job_cat
27764
0.67
FALSE
3
Non: 31043, CS,: 17223, Oth: 7642
satis_advance
14041
0.83
FALSE
4
Som: 30443, Ver: 16980, Som: 15632, Ver: 6576
satis_salary
14041
0.83
FALSE
4
Som: 34453, Ver: 21073, Som: 9854, Ver: 4251
satis_contrib
14041
0.83
FALSE
4
Ver: 35124, Som: 25341, Som: 6774, Ver: 2392
sex
0
1.00
FALSE
2
Mal: 45470, Fem: 38202
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
age
0
1
45.53
14.3
20
32
44
58
75
▆▇▆▆▃
Listing / Output 11.2: Show recoded data for chapter 11 (tbl11.1)
job_cat: Job caktegory of current job. n2ocprmg was the original variable name. Recoded into three categories:
CS, Math, Eng = Computer science, math, and engineering fields
Other sciences = Other science fields
Nonscience = Not a science field
satis_advance: Satisfaction with advancement opportunity. satadv was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied.
satis_salary: Satisfaction with salary. satsal was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied.
satis.contrib: Satisfaction with contribution to society. satsoc was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied
sex: gender was the original variable name. Two categories: Female, Male
age: Age in years, not recoded or renamed
R Code 11.3 : Sample 1500 cases: 500 from each job category
Code
tbl11.1<-base::readRDS("data/chap11/tbl11.1.rds")base::set.seed(seed =143)# take a sample of 1500 cases# 500 from each job.cat categorytbl11.2<-tbl11.1|>tidyr::drop_na(job_cat)|>dplyr::group_by(job_cat)|>dplyr::slice_sample(n =500)save_data_file("chap11", tbl11.2, "tbl11.2.rds")glue::glue("********** Summarizing with base:summary() **************")base::summary(tbl11.2)glue::glue(" ")glue::glue(" ")glue::glue("********** Summarizing with skimr::skim() **************")glue::glue(" ")skimr::skim(tbl11.2)
#> ********** Summarizing with base:summary() **************
#> age job_cat satis_advance
#> Min. :23.00 CS, Math, Eng :500 Very satisfied :342
#> 1st Qu.:32.00 Other Sciences:500 Somewhat satisfied :646
#> Median :40.00 Nonscience :500 Somewhat dissatisfied:361
#> Mean :42.89 Very dissatisfied :151
#> 3rd Qu.:54.00
#> Max. :75.00
#> satis_salary satis_contrib sex
#> Very satisfied :420 Very satisfied :732 Male :911
#> Somewhat satisfied :763 Somewhat satisfied :570 Female:589
#> Somewhat dissatisfied:225 Somewhat dissatisfied:154
#> Very dissatisfied : 92 Very dissatisfied : 44
#>
#>
#>
#>
#> ********** Summarizing with skimr::skim() **************
#>
Data summary
Name
tbl11.2
Number of rows
1500
Number of columns
6
_______________________
Column type frequency:
factor
4
numeric
1
________________________
Group variables
job_cat
Variable type: factor
skim_variable
job_cat
n_missing
complete_rate
ordered
n_unique
top_counts
satis_advance
CS, Math, Eng
0
1
FALSE
4
Som: 227, Ver: 115, Som: 115, Ver: 43
satis_advance
Other Sciences
0
1
FALSE
4
Som: 213, Som: 131, Ver: 109, Ver: 47
satis_advance
Nonscience
0
1
FALSE
4
Som: 206, Ver: 118, Som: 115, Ver: 61
satis_salary
CS, Math, Eng
0
1
FALSE
4
Som: 254, Ver: 163, Som: 68, Ver: 15
satis_salary
Other Sciences
0
1
FALSE
4
Som: 257, Ver: 128, Som: 79, Ver: 36
satis_salary
Nonscience
0
1
FALSE
4
Som: 252, Ver: 129, Som: 78, Ver: 41
satis_contrib
CS, Math, Eng
0
1
FALSE
4
Som: 230, Ver: 193, Som: 61, Ver: 16
satis_contrib
Other Sciences
0
1
FALSE
4
Ver: 297, Som: 163, Som: 34, Ver: 6
satis_contrib
Nonscience
0
1
FALSE
4
Ver: 242, Som: 177, Som: 59, Ver: 22
sex
CS, Math, Eng
0
1
FALSE
2
Mal: 389, Fem: 111
sex
Other Sciences
0
1
FALSE
2
Mal: 263, Fem: 237
sex
Nonscience
0
1
FALSE
2
Mal: 259, Fem: 241
Variable type: numeric
skim_variable
job_cat
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
age
CS, Math, Eng
0
1
41.00
12.39
23
30.75
37
52
74
▇▅▃▃▁
age
Other Sciences
0
1
43.08
13.26
23
32.00
40
55
73
▇▆▅▅▂
age
Nonscience
0
1
44.60
13.18
23
33.00
43
55
75
▇▇▆▆▂
Listing / Output 11.3: Show sampled data: 500 from each job category
11.4 Achievement 1: EDA for multinomial logistic regression
11.4.1 Visualizing employment
Example 11.2 : Visualizing employment in computer science, math, and engineering by sex and age
R Code 11.4 : Plotting distribution of sex within job type
Code
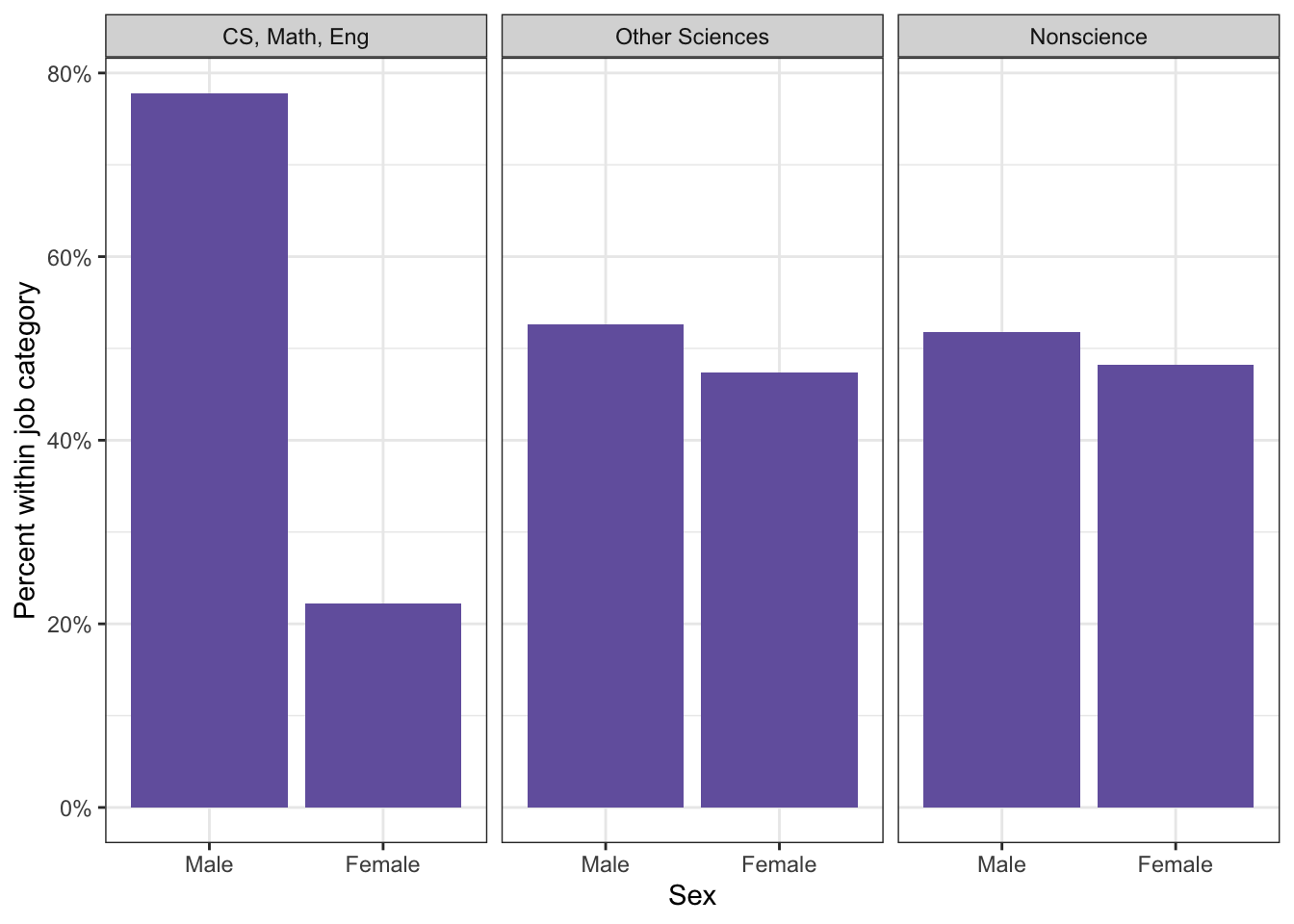
tbl11.2<-base::readRDS("data/chap11/tbl11.2.rds")# plotting distribution of sex within job type (Figure 11.3)tbl11.2|>ggplot2::ggplot(ggplot2::aes( x =sex, group =job_cat, y =ggplot2::after_stat(prop)))+ggplot2::geom_bar(fill ="#7463AC")+ggplot2::labs( y ="Percent within job category", x ="Sex")+# ggplot2::facet_grid(cols = ggplot2::vars(job_cat)) +# using another, more simple facet_grid() function:ggplot2::facet_grid(~job_cat)+ggplot2::scale_y_continuous(labels =scales::percent)
Listing / Output 11.4: Distribution of sex within job type among 1,500 college graduates in 2017
ggplot2::after_stat() replaces the old approach surrounding the variable names with .., e.g. ..prop... {ggplot2} throws a warning:
#> Warning: The dot-dot notation (..prop..) was deprecated in ggplot2 3.4.0.
#> ℹ Please use after_stat(prop) instead.
At first I had problems, because I used y = ggplot2::after_stat(count/sum(count)) inside the ggplot2::aes() function. This calculated the percentage over all different categories and not within each job category. The I learned with The ‘computed variables’ section in each stat lists which variables are available to access. that {ggplot2} computes with the ggplot2::stat_count() function for bar charts also groupwise proportion with ggplot2::after_stat(prop).
Read the help page to understand the differences between the different stages of mapping (direct input, after_stat() and after_scale()). Very important is the sentence: The ‘computed variables’ section in each stat lists which variables are available to access.
The first article of the very extensive series of articles going into many technical detail working — at least for me — as an eye opener how {ggplot2} works Demystifying delayed aesthetic evaluation: Part 1.
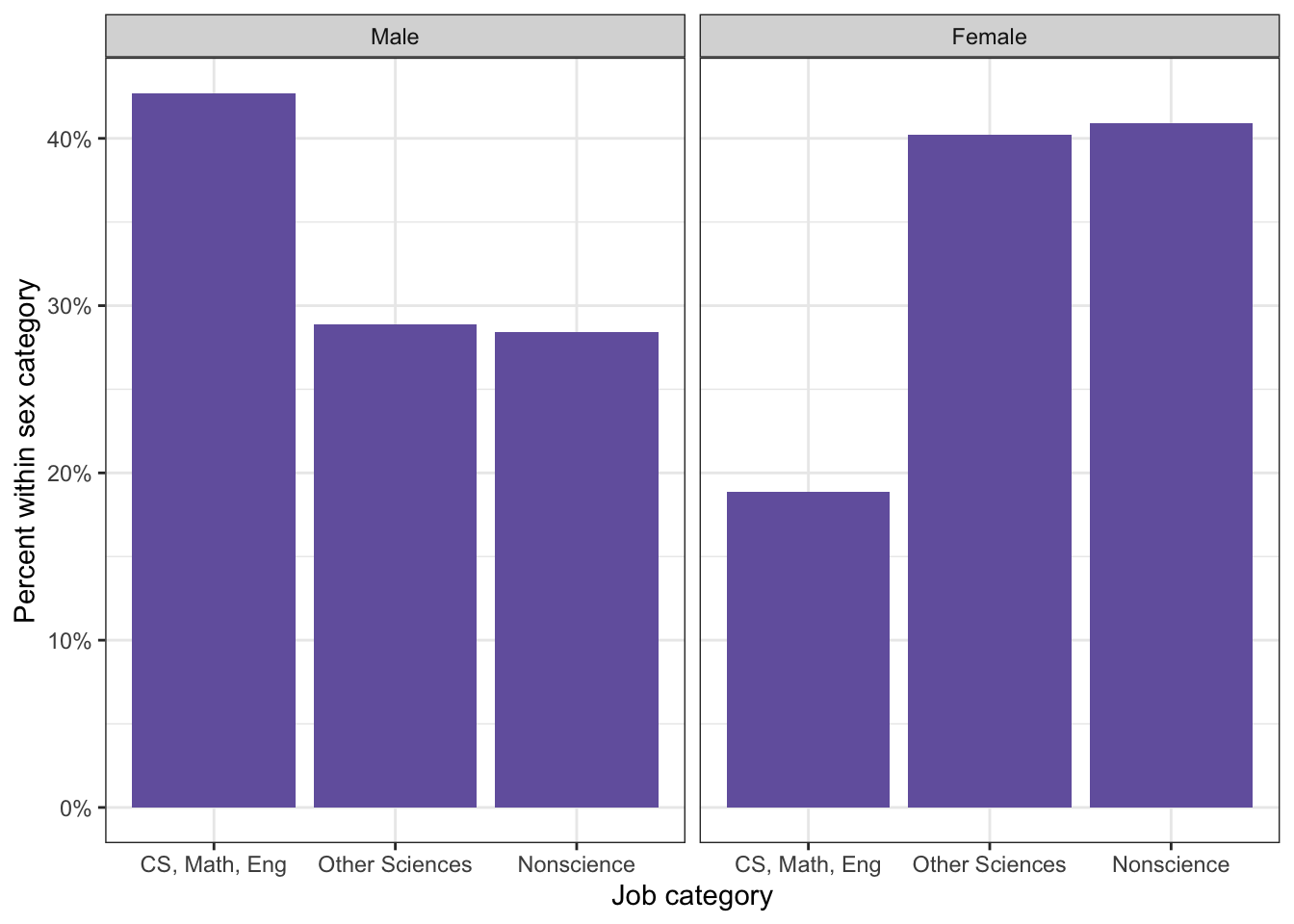
# plotting distribution of job type by sex (Figure 11.4)tbl11.2|>ggplot2::ggplot(ggplot2::aes( x =job_cat, group =sex, y =ggplot2::after_stat(prop)))+ggplot2::geom_bar(fill ="#7463AC")+ggplot2::labs( y ="Percent within sex category", x ="Job category")+ggplot2::facet_grid(cols =ggplot2::vars(sex))+ggplot2::scale_y_continuous(labels =scales::percent)
Listing / Output 11.5: Distribution of job type by sex
R Code 11.6 : Distribution of job type and age
Code
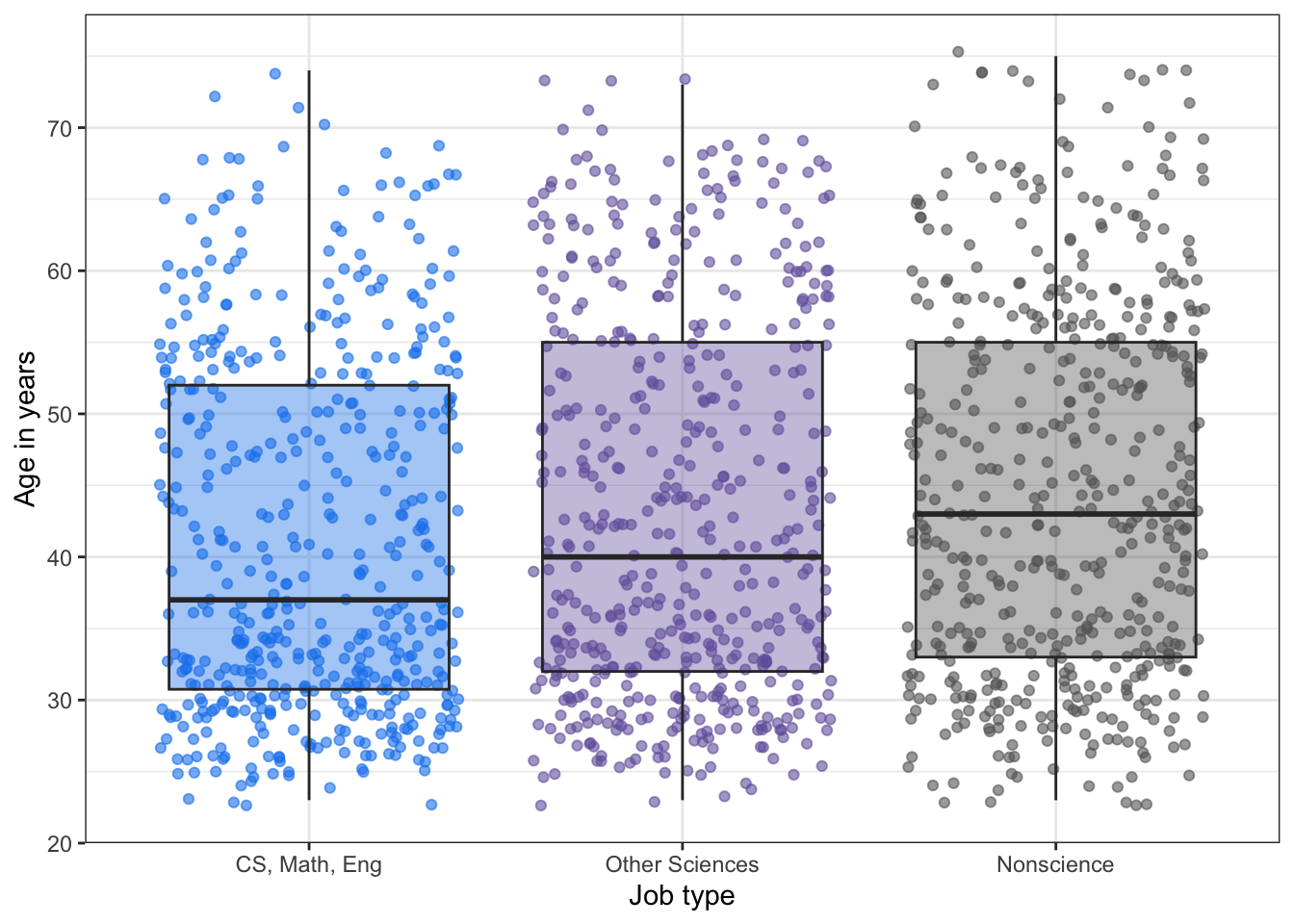
# plotting distribution of job type and age (Figure 11.5)tbl11.2|>ggplot2::ggplot(ggplot2::aes( y =age, x =job_cat))+ggplot2::geom_jitter(ggplot2::aes( color =job_cat), alpha =.6)+ggplot2::geom_boxplot(ggplot2::aes( fill =job_cat), alpha =.4)+ggplot2::scale_fill_manual( values =c("dodgerblue2","#7463AC", "gray40"), guide ="none")+ggplot2::scale_color_manual(values =c("dodgerblue2","#7463AC", "gray40"), guide ="none")+ggplot2::labs( x ="Job type", y ="Age in years")
Listing / Output 11.6: Distribution of job type and age
R Code 11.7 : Distribution of jobtype by age and sex
Code
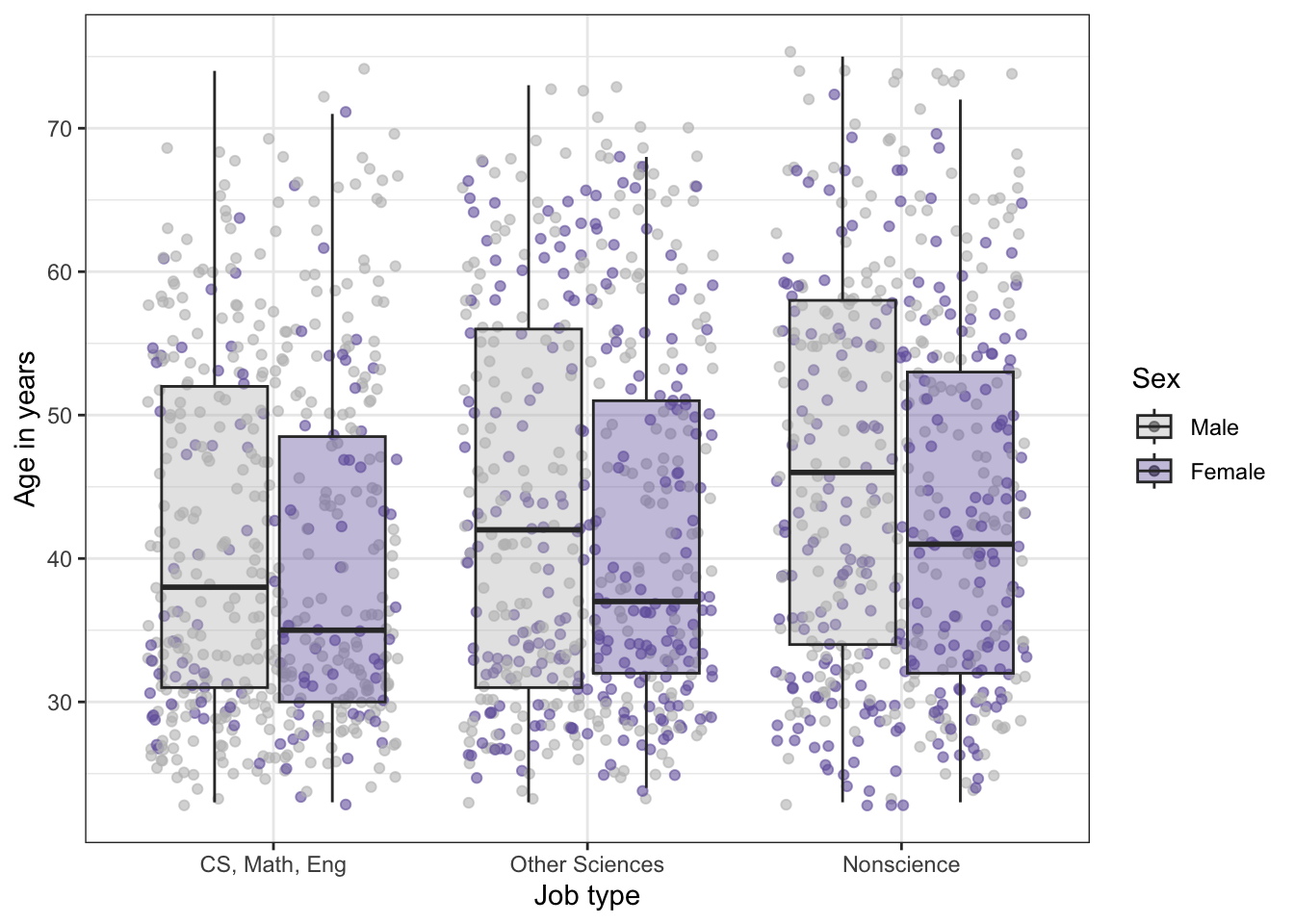
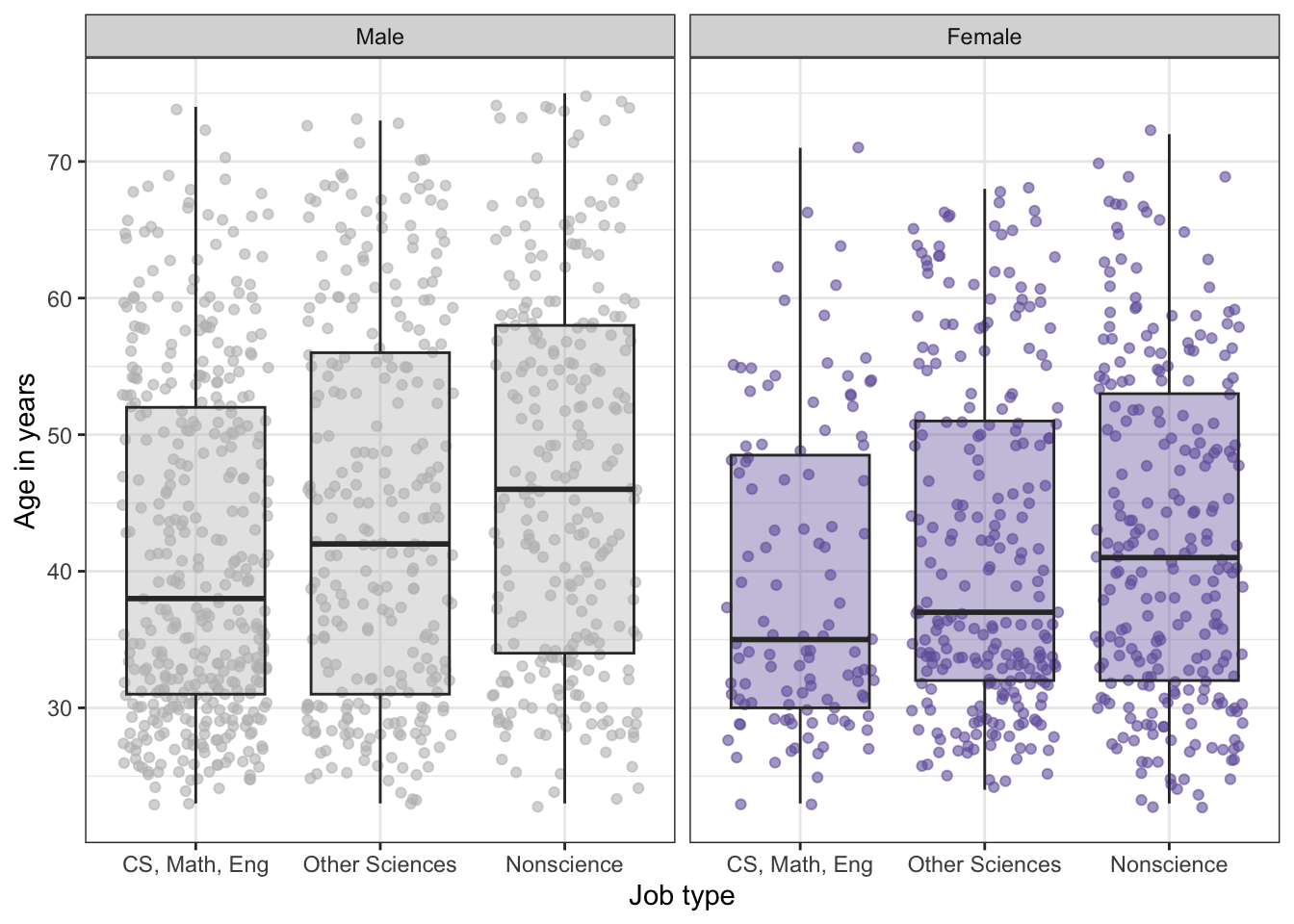
# plotting distribution of job type, age, and sex (Figure 11.6)tbl11.2|>ggplot2::ggplot(ggplot2::aes( y =age, x =job_cat, fill =sex))+ggplot2::geom_jitter(ggplot2::aes( color =sex), alpha =.6)+ggplot2::geom_boxplot(ggplot2::aes( fill =sex), alpha =.4)+ggplot2::scale_fill_manual( values =c("gray", "#7463AC"), name ="Sex")+ggplot2::scale_color_manual( values =c("gray", "#7463AC"), guide ="none")+ggplot2::labs( x ="Job type", y ="Age in years")
Listing / Output 11.7: Distribution of job type by age and sex
R Code 11.8 : Distribution by job type sex and age
Code
# plotting distribution of job type, sex, and age (Figure 11.7)tbl11.2|>ggplot2::ggplot(ggplot2::aes( y =age, x =job_cat))+ggplot2::geom_jitter(ggplot2::aes( color =sex), alpha =.6)+ggplot2::geom_boxplot(ggplot2::aes( fill =sex), alpha =.4)+ggplot2::scale_fill_manual( values =c("gray", "#7463AC"), guide ="none")+ggplot2::scale_color_manual( values =c("gray", "#7463AC"), guide ="none")+ggplot2::labs( x ="Job type", y ="Age in years")+ggplot2::facet_grid(cols =ggplot2::vars(sex))
Listing / Output 11.8: Distribution by job type sex and age
Report 11.1: Summary of the several plots about employment
Listing / Output 11.4: Computer science, math, and engineering have about a third as many females as males, other sciences and non-science were slightly more male than female.
Listing / Output 11.5: Computer science, math, and engineering jobs were the least common for females while this category was the largest for males.
Listing / Output 11.6: While the age range for all the data appeared similar across the three job types, the computer science, math, and engineering field employed the youngest people on average.
Listing / Output 11.7: In all three fields, the distribution of age showed that males have an older median age than females, and in the two science fields, the range of age is wider for males than females.
Listing / Output 11.8: The lowest median age for females is in computer science, math, and engineering and higher in other sciences and non-science. The age distribution for males showed a similar pattern across the three job types. Computer science, math, and engineering has the youngest median age for both sexes.
R Code 11.9 : Age distribution by job type among 1,500 college graduates in 2017
Code
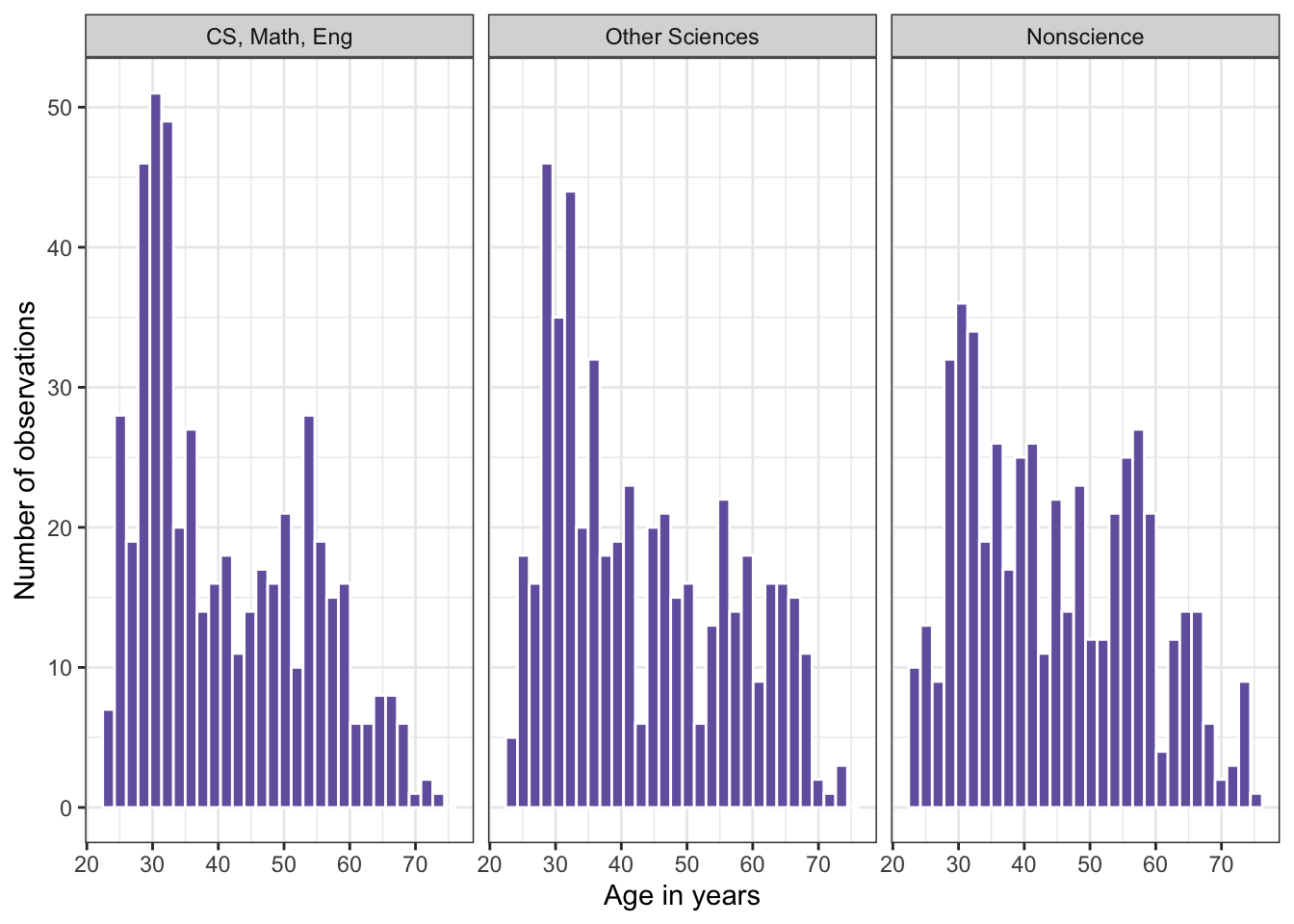
# plotting distribution of age (Figure 11.8)tbl11.2|>ggplot2::ggplot(ggplot2::aes(x =age))+ggplot2::geom_histogram( bins =30, fill ="#7463AC", color ="white")+ggplot2::labs( x ="Age in years", y ="Number of observations")+ggplot2::facet_grid(cols =ggplot2::vars(job_cat))
Listing / Output 11.9: Age distribution by job type among 1,500 college graduates in 2017
The histograms were not normally distributed for any of the three groups.
R Code 11.10 : Table of statistics to examine job_cat
Code
# make a table of statistics to examine job.cattable_desc<-tableone::CreateTableOne( data =tbl11.2, strata ='job_cat', vars =c('sex', 'age'))base::print(table_desc, showAllLevels =TRUE, nonnormal ='age')
#> Stratified by job_cat
#> level CS, Math, Eng Other Sciences
#> n 500 500
#> sex (%) Male 389 (77.8) 263 (52.6)
#> Female 111 (22.2) 237 (47.4)
#> age (median [IQR]) 37.00 [30.75, 52.00] 40.00 [32.00, 55.00]
#> Stratified by job_cat
#> Nonscience p test
#> n 500
#> sex (%) 259 (51.8) <0.001
#> 241 (48.2)
#> age (median [IQR]) 43.00 [33.00, 55.00] <0.001 nonnorm
Listing / Output 11.10: Table of statistics to examine job_cat
The visual differences in the graphs corresponded to statistically significant differences from the chi-squared and Kruskal-Wallis tests. The median age for college graduates in computer science, math, or engineering was 3 years lower than the median age in other sciences and 6 years younger than the median age in non-science careers. Computer science, math, and engineering has more than three times as many males as females.
11.5 Achievement 2: Estimating a multinomial logistic regression model
11.5.1 Introduction
Bullet List 11.1
: Important to report with every model
Model significance: Is the model significantly better than some baseline at explaining the outcome?
Model fit: How well does the model capture the relationships in the underlying data?
Predictor values and significance: What is the size, direction, and significance of the relationship between each predictor and the outcome?
Checking model assumptions: Are the model assumptions met?
11.5.2 Check reference groups
Before starting with the computation for the multinomial logistic regression it is practicable to check the reference groups with base::levels(). The results are easier to interpret if the reference groups (= the first level) is consistent with what one is interested in. Otherwise use stats::relevel() or one of the many functions in {forcats}, for instance fct_recode() or fct_relevel().
R Code 11.11 : Check reference groups for regression
Listing / Output 11.11: Reference group for job_cat (= “CS, Math, Eng”) and sex (= “Male”)
The reference group are fine; no change is necessary.
11.5.3 NHST Step 1
Write the null and alternate hypotheses:
Wording for H0 and HA
H0: A multinomial model including sex and age is not useful in explaining or predicting job type for college graduates.
HA: A multinomial model including sex and age is useful in explaining or predicting job type for college graduates.
11.5.4 NHST Step 2
A Google search revealed the most of the R tutorials use the {nnet} package recommended also by SwR. A newer approach uses the meta-package {tidymodel} (similar to tidyverse) which collects 22 packages for modeling, containing {parsnip} with the multinom_reg() function that ca fit different classification models, including {nnet} as default package.
TODO: Learn {tidymodels}
I already learned from the {tidymodels} approach three-four years ago. But at that time I thought that it is too advanced for my skill level. This has changed now. I have worked through all of the three pre-requisites mentioned on the start page of tidymodels. And now — coming to the end of SwR — I understand why this unification project is important.
R Code 11.14 : Compute test statistics for the multinomial model mnm11.1
Code
# get the job model chi-squaredjob_chisq<-mnm11.0$deviance-mnm11.1$deviance# get the degrees of freedom for chi-squaredjob_df<-length(x =summary(object =mnm11.1)$coefficients)-length(x =summary(object =mnm11.0)$coefficients)# get the p-value for chi-squaredjob_p<-stats::pchisq( q =job_chisq, df =job_df, lower.tail =FALSE)# put together into a vector and round to 3 decimal placesmodel_sig<-base::round(x =c(job_chisq, job_df, job_p), 3)# add names to the vectorbase::names(x =model_sig)<-c("Chi-squared", "df", "p")# print the vectormodel_sig
#> Chi-squared df p
#> 124.765 6.000 0.000
Listing / Output 11.14: Test statistics for the multinomial model
Finishing step 2 of the NHST procedure:
Compute the test statistics.
The test statistic is a chi-squared of 124.77 with 6 degrees of freedom.
11.5.5 NHST Step 3
Review and interpret the test statistics:
Calculate the probability that your test statistic is at least as big as it is if there is no relationship (i.e., the null is true).
The probability computed for the chi-squared was < .001.
11.5.6 NHST Step 4
Conclude and write report.
Report 11.2: Report the conclusion of the interpretation of the multinomial model mnm11.1
We have to reject the null hypothesis and conclude that a model including age, sex, and age*sex explained job type statistically significantly better [\(χ^2(6) = 124.77; p < .001\)] than a null model with no predictors.
R Code 11.15 : Show fitted.values and predict() results
Code
df1<-my_glance_data(data.frame(mnm11.1$fitted.values))df2<-my_glance_data(data.frame(predicted =stats::predict(mnm11.1)))dplyr::full_join(df1, df2, by =dplyr::join_by(obs))
Listing / Output 11.15: Random example rows of fitted.values to compare with the results from the predict() function
obs column: Number of row taken from the sample data tbl11.2.
The next column are the predicted probability for each person to be in each of the three job type groups. The data are taken from the fitted-values result of the multinomial model mnm11.1.
The last column predict the job category for each randomly chosen person. This is always the highest probability from the fitted.values categories.
R Code 11.16 : Compare observed job category with the predicted value
Code
# observed vs. predicted category for each observationfit_abs<-base::table( observed =mnm11.1$model$job_cat, predicted =stats::predict(object =mnm11.1))glue::glue("Absolute values: observed vs. predicted category for each observation")fit_abs# observed vs. predicted category for each observationfit_perc<-base::proportions(base::table( observed =mnm11.1$model$job_cat, predicted =predict(object =mnm11.1)), margin =1)glue::glue(" ")glue::glue(" ")glue::glue("Percentages: observed vs. predicted category for each observation")fit_perc
#> Absolute values: observed vs. predicted category for each observation
#> predicted
#> observed CS, Math, Eng Other Sciences Nonscience
#> CS, Math, Eng 342 66 92
#> Other Sciences 206 129 165
#> Nonscience 201 112 187
#>
#>
#> Percentages: observed vs. predicted category for each observation
#> predicted
#> observed CS, Math, Eng Other Sciences Nonscience
#> CS, Math, Eng 0.684 0.132 0.184
#> Other Sciences 0.412 0.258 0.330
#> Nonscience 0.402 0.224 0.374
Listing / Output 11.16: Observed job category versus the predicted value of the model (absolute and percentages)
The model was best at predicting the computer science, math, or engineering job type, with 68.4% of the observations in this category correctly predicted. The nonscience job type was predicted with 37.4% accuracy, and other sciences was predicted with 25.8% accuracy. Overall, the model predicted job type correctly for 658 out of 1,500 observations (43.9%). Given that the sample included 500 people from each job type, without any other information, we would guess that everyone was in a single category and would be right for 500, or 33.3%, of the observations. Although the overall correctness was low, it was higher than this baseline probability of correctly classifying observations by job type.
11.5.8 Multinomial model predictor interpretation
We know that the model is statistically significantly better than baseline at explaining job type and that the predictions from the model were better than a baseline percentage would be. We also know that the prediction was best for computer science, math, and engineering. The next thing we want to examine is the predictor fit and significance.
11.5.8.1 Predictor significance
Listing / Output 11.12 does not include any indication of whether or not each predictor (age, sex, age*sex) is statistically significantly associated with job type. To get statistical significance and more interpretable values, we need to compute odds ratios and 95% confidence intervals around the odds ratios.
# get odds ratios and transpose to get 'standard' formatbase::t(x =base::exp(x =stats::coef(object =mnm11.1)))
#> Other Sciences Nonscience
#> (Intercept) 0.3299285 0.1903055
#> age 1.0168517 1.0288710
#> sexFemale 3.2876930 4.5780248
#> age:sexFemale 1.0000501 0.9939356
Listing / Output 11.17: Odds ratios
Caution 11.1: Watch out for the correct reference group
It gets more complicated with this type of regression. Not only do the predictors have reference groups, but the outcome variable also has a reference group.
The reference group for the outcome variable is computer science, math, or engineering. This was not only our result with Listing / Output 11.11 but it is confirmed by missing this group in the result. (The missing group is always the reference group.)
Report 11.3: Example of an interpretation of the odds ratios
For every year older a person gets, the odds of having a career in other sciences is 1.02 times higher compared to the odds of being in computer science, math, or engineering.
R Code 11.18 : Compute confidence intervals
Code
# confidence intervals for odds ratiosbase::exp(x =stats::confint(object =mnm11.1))
Listing / Output 11.18: Confidence intervals for odds ratios
Remember: A confidence interval of odds ratio is statistically significant if it does not include 1. This is the case for age and Female sex but not for the interaction term age:sexFemale.
R Code 11.19 : Put odd ratios and confidence interval together into the same data table
Code
# get odds ratios for other sciences from the model objectoddsratio_other_sci<-base::t(x =base::exp(x =stats::coef(object =mnm11.1)))[ , 1]# get CI for other sciencesconfint_other_sci<-base::exp(x =stats::confint(object =mnm11.1))[ , 1:2, 1]# put into a data frame other_sci<-base::data.frame( oddsratio_other =oddsratio_other_sci, ci_other =confint_other_sci)# get odds ratios for non-scienceoddsratio_non_sci<-base::t(x =base::exp(x =stats::coef(object =mnm11.1)))[ , 2]# get CI for non-scienceconfint_non_sci<-base::exp(x =stats::confint(object =mnm11.1))[ , 1:2, 2]# put into a data framenon_sci<-base::data.frame( oddsratio_non =oddsratio_non_sci, ci_non =confint_non_sci)# all togetherdata.frame(other_sci, non_sci)
Listing / Output 11.19: Odd ratios and confidence intervals of the multinomial model mnm11.1
The first three columns of numbers are the odds ratios and confidence intervals for the job type of other sciences, while columns 4 through 6 are for the non-science job type.
11.5.8.2 Predictor interpretation
The outcome variable with multiple categories now had a reference group. In this case, the reference group is computer science, math, or engineering job type. The odds ratios are interpreted with respect to this reference group. This works OK for the continuous variable of age but gets a little tricky for the categorical variable of sex, where there are now two reference groups to consider.
Report 11.4: Predictor interpretation of the multinomial logistic regression model mnm11.1
The age row starts with the odds ratio of 1.02 with confidence interval 1.00–1.03. For every 1-year increase in age, the odds of being in an other sciences job are 1.02 times higher than being in a computer science, math, or engineering job (\(95% CI: 1.00–1.03\)). Likewise, for every 1-year increase in age, the odds of being in a non-science job are 1.03 times higher than being in a computer science, math, or engineering job (\(95% CI: 1.02–1.04\)).
Compared to males, the odds of females being in an other sciences job are 3.29 times higher than being in a computer science, math, or engineering job (\(95% CI: 1.24–8.71\)). Also, compared to males, females have 4.58 times higher odds of being in non-science jobs compared to computer science, math, or engineering jobs (\(95% CI: 1.71–12.22\)).
The interaction between age and sex was not statistically significant for either other sciences jobs or non-science jobs compared to computer science, math, or engineering jobs.
Overall, it seems that females had higher odds than males of being in other sciences or nonscience compared to being in computer science, math, or engineering. Likewise, the older someone gets, the more likely they are to work in other sciences or non-science compared to computer science, math, or engineering. It seems that, overall, computer science, math, or engineering job types are most likely to be held by males and people who are younger.
11.6 Achievement 3: Checking assumptions for multinomial logistic regression
Besides the assumption of independence of observations (which is met), there is the IIA assumption. The independence of irrelevant alternatives assumption requires that the categories of the outcome be independent of one another. For example, the relative probability of having a job in the computer science, math, or engineering field compared to the other science field cannot depend on the existence of non-science jobs.
This assumption can be tested by taking a subset of the data that includes two of the outcome categories and estimating binary logistic regression models with the same predictors. These model results can then be compared with the multinomial model results to see if the relationship is consistent. The test used for this assumption is the Hausman-McFadden test.
Remark 11.1. : What is the independence of irrelevant alternatives (IIA) assumption?
The above explanation of IIA in SwR is easy to misunderstand. The important clarification is that the third alternative (C) is not an alternative of the choice between A and B. Therefore we are talking of irrelevant alternatives. So what we state is that the probability of choosing A or B is independent of C. The following quote from Statistical Horizons brings an example that helped my understanding more than the example in SwR:
In discrete choice theory, the IIA assumption says that when people are asked to choose among a set of alternatives, their odds of choosing A over B should not depend on whether some other alternative C is present or absent. As an example, consider the 1992 U.S. presidential election. The two major party candidates were Bill Clinton and George H. W. Bush. But H. Ross Perot was also on the ballot in all 50 states. The IIA assumption says that, for each voter, the odds of choosing Clinton over Bush was not affected by Perot’s presence on the ballot. (Allison 2012)
The test strategy is the following: for each alternative, delete individuals who chose that alternative and re-estimate the model for the remaining alternatives; then construct a test comparing the new estimates with the original estimates.
In our voting example, for instance, we could exclude the people who voted for Perot, and estimate a binary logit model predicting Clinton vs. Bush. We could then test whether the binary coefficients were the same as the multinomial coefficients. We could also exclude the people who voted for Clinton and re-estimate the second equation by binary logit. Again, we could compare the binary coefficients with the multinomial coefficients. And, finally, we could redo the test with Bush as the excluded category.
Example 11.7 : Compute the Hausman-McFadden test for independence of irrelevant alternatives
R Code 11.20 : Re-estimate the model with {mlogit}
Code
# reshape data to use with the dfidx function from {dfidx}tbl11.2<-base::readRDS("data/chap11/tbl11.2.rds")tbl11.2_wide<-dfidx::dfidx(data =tbl11.2, choice ="job_cat", shape ="wide")# estimate the model and print its summarymnm3<-mlogit::mlogit(formula =job_cat~0|age+sex+age*sex, data =tbl11.2_wide)summary(object =mnm3)
Listing / Output 11.20: Model re-estimated with the {mlogit} package.
The function mlogit::mlogit.data() used in the book is deprecated and should be replaced with dfidx() from the {dfidx} package (see: Section A.16).
R Code 11.21 : Estimate the model with two outcome categories
Code
# estimate the model with two outcome categories and print its summarymnm3_alt<-mlogit::mlogit(formula =job_cat~0|age+sex+age*sex, data =tbl11.2_wide, alt.subset =c("CS, Math, Eng", "Nonscience"))summary(object =mnm3_alt)
#>
#> Hausman-McFadden test
#>
#> data: tbl11.2_wide
#> chisq = 0.4851, df = 4, p-value = 0.9749
#> alternative hypothesis: IIA is rejected
Listing / Output 11.22: Hausman-McFadden test
The p-value was .97, which is much higher than .05, so the null hypothesis is retained and the IIA assumption is met.
11.6.1 Conclusion of the multinomial logistic regression
Report 11.5: Report of the multinomial logistic regression of job types versus age and sex (final version)
A multinomial logistic regression including age, sex, and the interaction between age and sex was statistically significantly better at predicting job type than a null model with no predictors [\(χ^2(6) = 124.77; p < .001\)]. The model met its assumptions and correctly predicted the job type for 43.9% of observations.
For every 1-year increase in age, the odds of being in an other sciences job are 1.02 times higher than being in a computer science, math, or engineering job (95% CI: 1.00–1.03).
Likewise, for every 1-year increase in age, the odds of being in a nonscience job are 1.03 times higher than being in a computer science, math, or engineering job (95% CI: 1.02–1.04).
Compared to males, the odds of females being in an other sciences job are 3.29 times higher than being in a computer science, math, or engineering job (95% CI: 1.24–8.71).
Also, compared to males, females have 4.58 times higher odds of being in nonscience jobs compared to computer science, math, or engineering jobs (95% CI: 1.71–12.22).
The interaction between age and sex was not a statistically significant indicator of job type.
11.7 Achievement 4: EDA for ordinal logistic regression
11.7.1 Introduction
We are not going to compare satisfaction of women to the satisfaction of men with computer science, math, or engineering. Out interest is in understanding whether job satisfaction differs for women across the three job types.
We will take a sample of female participants from the original data frame so that we would have a larger number in the sample than using the females from the subset of 1,500. Since there were very few people (relatively speaking) in the dissatisfied categories (see Listing / Output 11.3), we will take 250 people from each category of one of the satisfaction variables to ensure to get enough people in the dissatisfied categories.
Example 11.8 : Exploratory data analysis for a ordinal logistic regression models
#> age job_cat satis_advance
#> Min. :23.00 CS, Math, Eng :177 Very satisfied :160
#> 1st Qu.:31.00 Other Sciences:133 Somewhat satisfied :356
#> Median :37.00 Nonscience :690 Somewhat dissatisfied:297
#> Mean :40.51 Very dissatisfied :187
#> 3rd Qu.:50.00
#> Max. :72.00
#> satis_salary satis_contrib sex
#> Very satisfied :235 Very satisfied :250 Male : 0
#> Somewhat satisfied :455 Somewhat satisfied :250 Female:1000
#> Somewhat dissatisfied:184 Somewhat dissatisfied:250
#> Very dissatisfied :126 Very dissatisfied :250
#>
#>
Listing / Output 11.23: Sample of 1,000 females
Warning 11.1: Different sample figures with the same set.seed() command
I got different figures after data sampling. I do not know from where the difference comes from. I had tried exactly the same code (e.g., using the deprecated function sample_n()), also I changed the set.seed() command to base::RNGkind(sample.kind = "Rounding") to meet the randomized sampling before version R 3.6.0. But in every case I got different figures than in the book example.
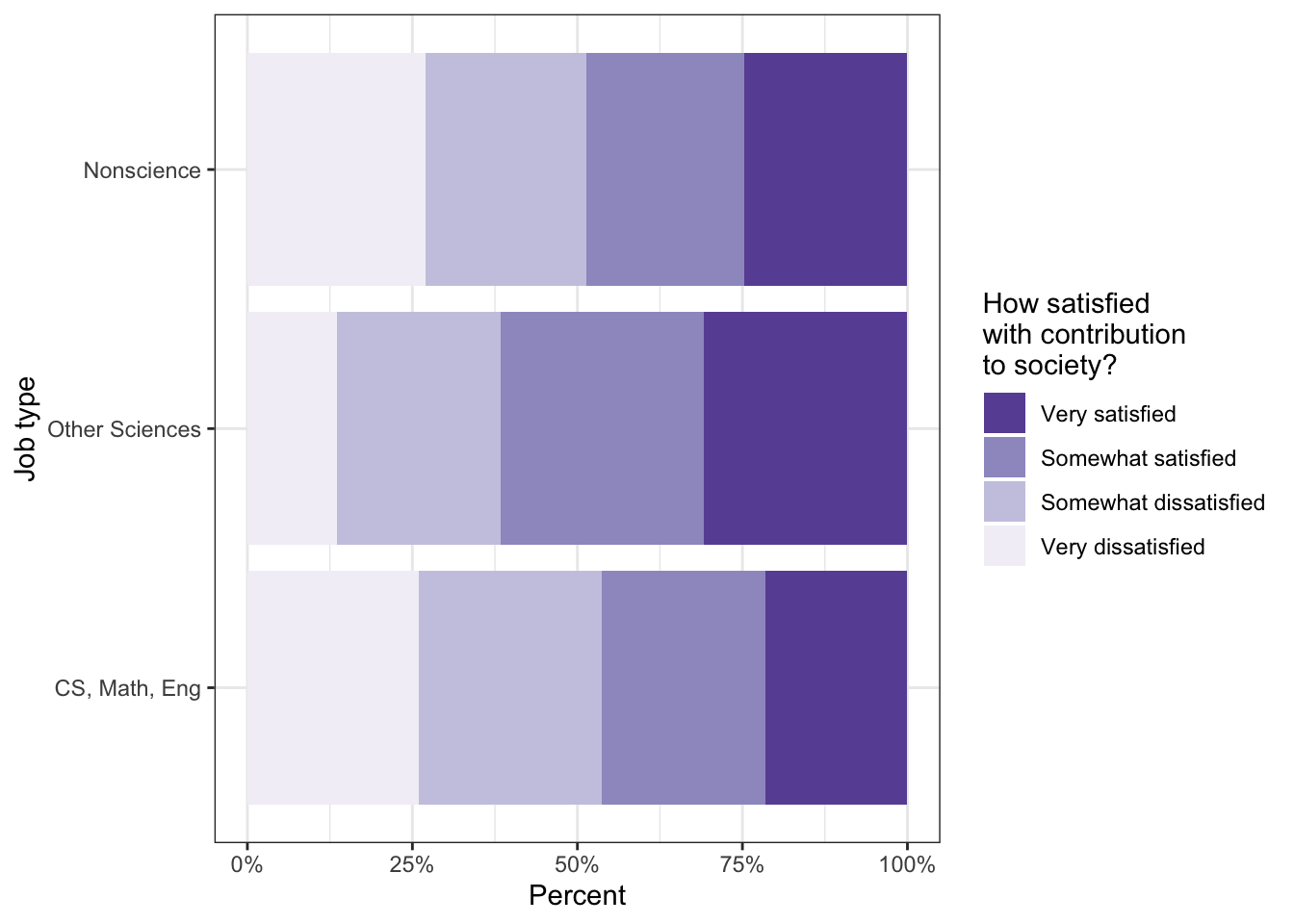
R Code 11.24 : Job satisfaction by society contribution
Code
# job satisfaction in job typetbl11.3|>ggplot2::ggplot(ggplot2::aes( x =job_cat, fill =satis_contrib))+ggplot2::geom_bar(position ="fill")+ggplot2::coord_flip()+ggplot2::labs( x ="Job type", y ="Percent")+ggplot2::scale_fill_brewer( name ="How satisfied\nwith contribution\nto society?", palette ="Purples", direction =-1)+ggplot2::scale_y_continuous(labels =scales::percent)
Listing / Output 11.24: Job satisfaction by society contribution
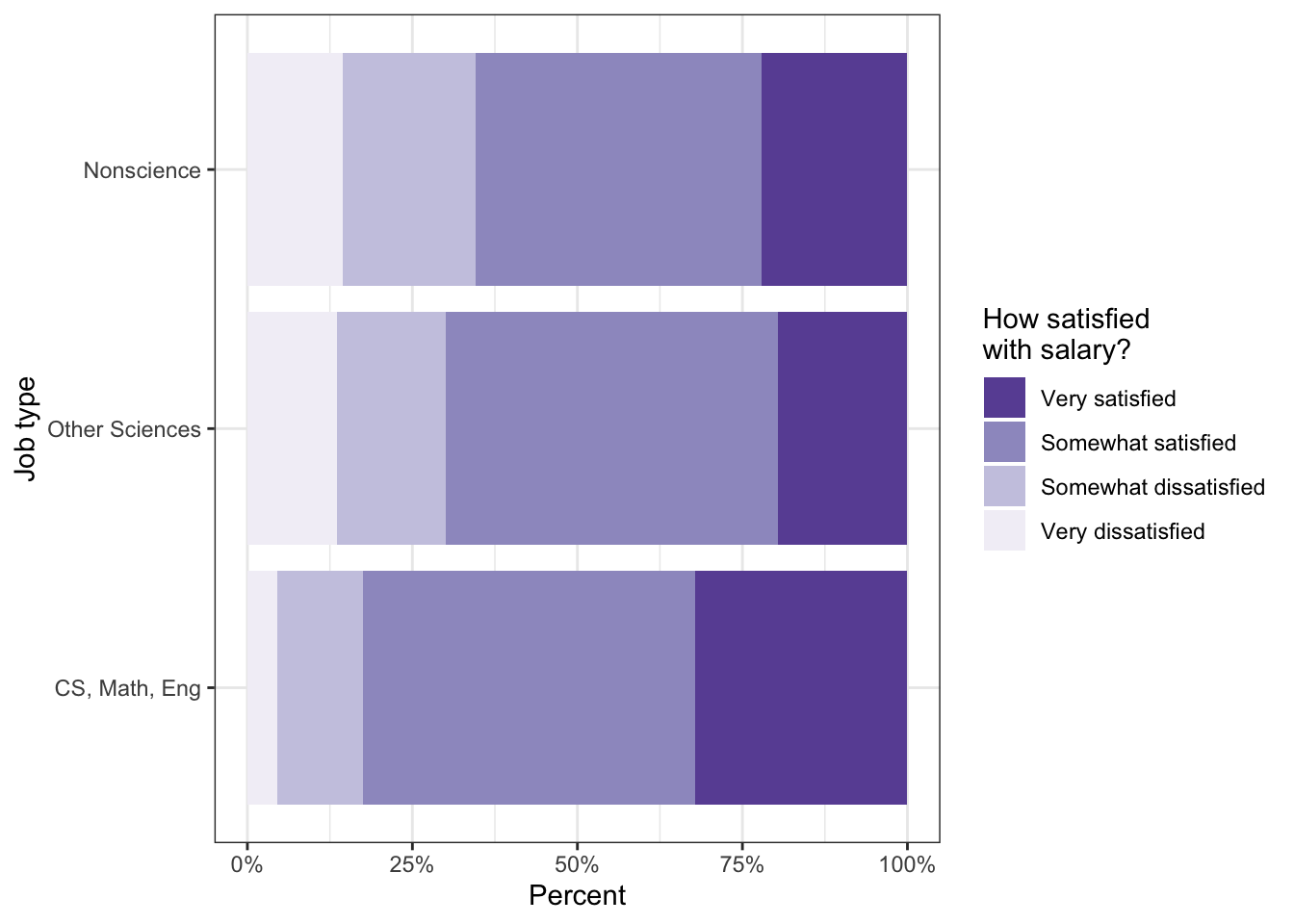
R Code 11.25 : Job satisfaction by salary
Code
# job satisfaction by salary (Figure 11.14)tbl11.3|>ggplot2::ggplot(ggplot2::aes( x =job_cat, fill =satis_salary))+ggplot2::geom_bar(position ="fill")+ggplot2::coord_flip()+ggplot2::labs( x ="Job type", y ="Percent")+ggplot2::scale_fill_brewer( name ="How satisfied\nwith salary?", palette ="Purples", direction =-1)+ggplot2::scale_y_continuous(labels =scales::percent)
Listing / Output 11.25: Job satisfaction by salary
R Code 11.26 : Job satisfaction by advance of science
Code
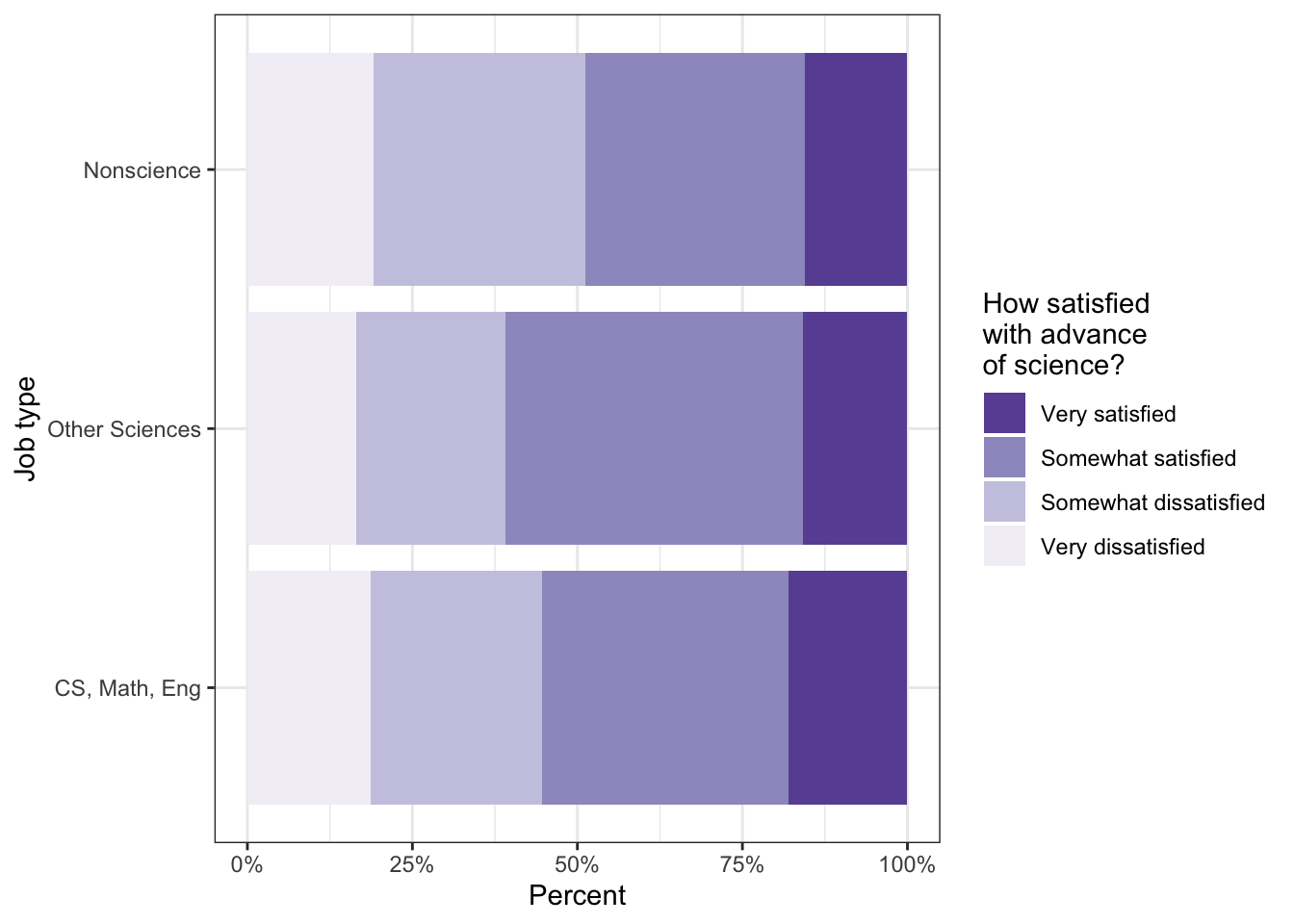
# job satisfaction by advancetbl11.3|>ggplot2::ggplot(ggplot2::aes( x =job_cat, fill =satis_advance))+ggplot2::geom_bar(position ="fill")+ggplot2::coord_flip()+ggplot2::labs( x ="Job type", y ="Percent")+ggplot2::scale_fill_brewer( name ="How satisfied\nwith advance\nof science?", palette ="Purples", direction =-1)+ggplot2::scale_y_continuous(labels =scales::percent)
Listing / Output 11.26: Job satisfaction by advance of science
R Code 11.27 : Job satisfaction with salary by age
Code
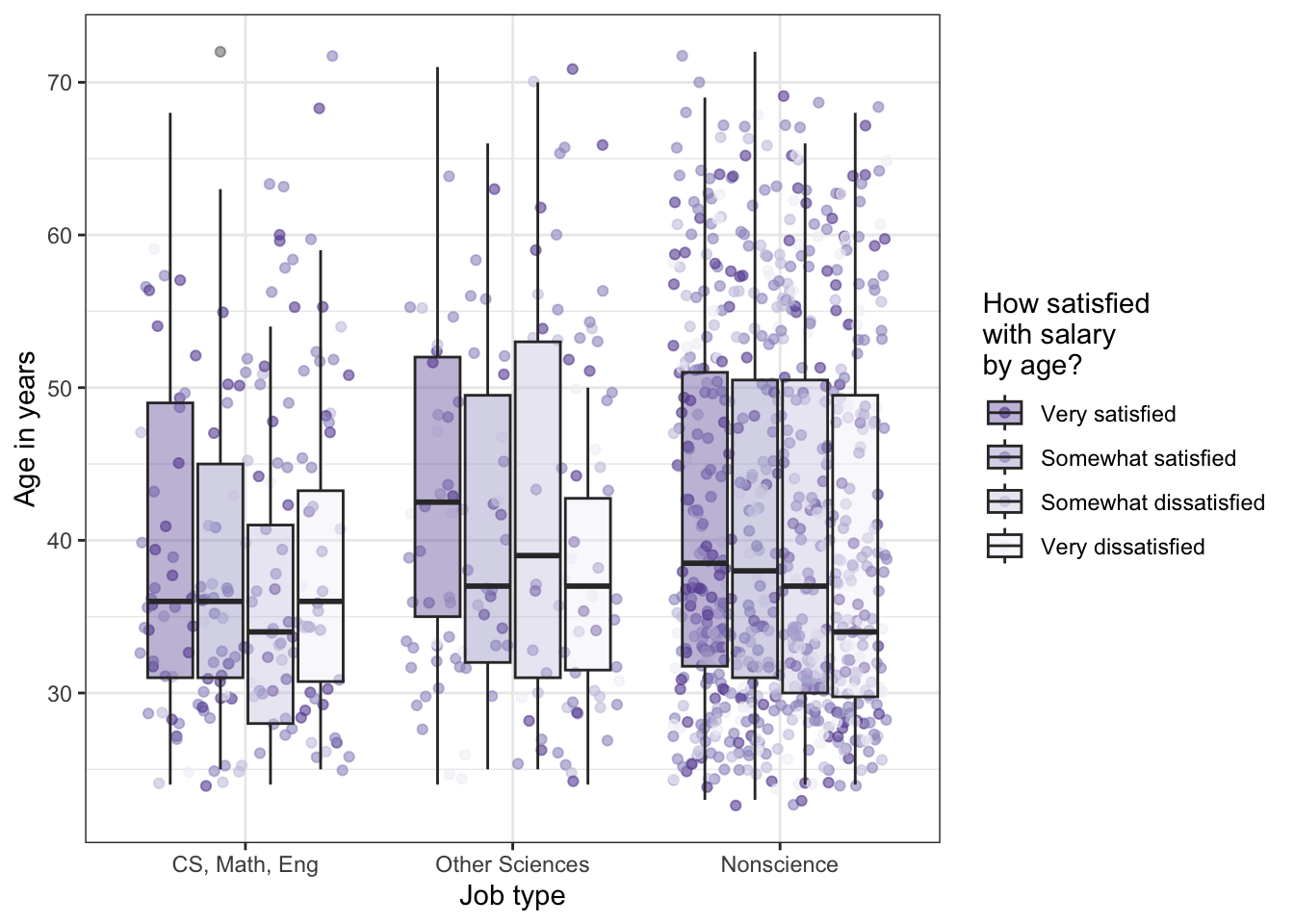
# job satisfaction by age (Figure 11.15)tbl11.3|>ggplot2::ggplot(ggplot2::aes( y =age, x =job_cat, fill =satis_salary))+ggplot2::geom_jitter(ggplot2::aes( color =satis_salary), alpha =.6)+ggplot2::geom_boxplot(ggplot2::aes( fill =satis_salary), alpha =.4)+ggplot2::scale_fill_brewer( name ="How satisfied\nwith salary\nby age?", palette ="Purples", direction =-1)+ggplot2::scale_color_brewer( name ="How satisfied\nwith salary\nby age?", palette ="Purples", direction =-1)+ggplot2::labs( x ="Job type", y ="Age in years")
Listing / Output 11.27: Job satisfaction with salary by age
R Code 11.28 : Create Likert-scale with ordered factors
Code
OrderSatis<-function(x){return(ordered(x, levels =c("Very dissatisfied","Somewhat dissatisfied","Somewhat satisfied","Very satisfied")))}# use function to order 3 satisfaction variablestbl11.4<-tbl11.3|>dplyr::mutate(satis_advance =OrderSatis(x =satis_advance))|>dplyr::mutate(satis_salary =OrderSatis(x =satis_salary))|>dplyr::mutate(satis_contrib =OrderSatis(x =satis_contrib))save_data_file("chap11", tbl11.4, "tbl11.4.rds")# check the dataskimr::skim(tbl11.4)
Data summary
Name
tbl11.4
Number of rows
1000
Number of columns
6
_______________________
Column type frequency:
factor
5
numeric
1
________________________
Group variables
None
Variable type: factor
skim_variable
n_missing
complete_rate
ordered
n_unique
top_counts
job_cat
0
1
FALSE
3
Non: 690, CS,: 177, Oth: 133
satis_advance
0
1
TRUE
4
Som: 356, Som: 297, Ver: 187, Ver: 160
satis_salary
0
1
TRUE
4
Som: 455, Ver: 235, Som: 184, Ver: 126
satis_contrib
0
1
TRUE
4
Ver: 250, Som: 250, Som: 250, Ver: 250
sex
0
1
FALSE
1
Fem: 1000, Mal: 0
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
age
0
1
40.51
11.89
23
31
37
50
72
▇▇▅▃▁
Listing / Output 11.28: {skimr} shows that the satisfaction factors are now ordered factors.
With this change I had some troubles, because I haven’t had any experience how to do and also to check if the levels are ordered or not. The check in the book with base::summary does not reveal if the factors are ordered or not. The summary() reports the sequence of the levels but not if they are ordered.
You can’t use the function base::levels() neither, because it also prints out only the chronological sequence but not if this sequence consists of ordered factor levels.
Important 11.1: No possibility found in {forcats} to create factor with ordered levels
I could manipulate the (chronological) appearance of levels in many ways but I did not find an option to create the class "ordered" "factor".
Therefore I have to use one of the following base R options options:
The following examples uses in the first line with tbl11.1$satis_advance an ordered factor, and with the second line (after the ‘—’ line) with tbl11.1$sex a factor without order.
R Code 11.29 : How to check the order of factor levels?
Code
tbl11.4<-base::readRDS("data/chap11/tbl11.4.rds")glue::glue("##########################################################################")glue::glue("base::levels() does not reveal if theres is an order in the factor levels")base::levels(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::levels(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("If you display a value of an ordered factor, it reveals the order with '<'")head(tbl11.4$satis_advance, 1)glue::glue(" ")glue::glue("To prevent showing one value one can use forcats::fct_unique()")forcats::fct_unique(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")head(tbl11.4$sex, 1)glue::glue("How to check if a factor has ordered levels, but not the order itself?")glue::glue(" ")glue::glue("##########################################################################")glue::glue("utils::str()")utils::str(tbl11.4)glue::glue(" ")glue::glue("##########################################################################")glue::glue("base::class()")base::class(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::class(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("base::is.ordered()")base::is.ordered(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::is.ordered(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("skimr::skim()) has a column 'ordered' about the status of the factor variable")tbl11_temp<-tbl11.4|>dplyr::select(satis_advance, sex)skimr::skim(tbl11_temp)
#> ##########################################################################
#> base::levels() does not reveal if theres is an order in the factor levels
#> [1] "Very dissatisfied" "Somewhat dissatisfied" "Somewhat satisfied"
#> [4] "Very satisfied"
#> --------------------------------------------------------------------------
#> [1] "Male" "Female"
#>
#> ##########################################################################
#> If you display a value of an ordered factor, it reveals the order with '<'
#> [1] Very satisfied
#> 4 Levels: Very dissatisfied < Somewhat dissatisfied < ... < Very satisfied
#>
#> To prevent showing one value one can use forcats::fct_unique()
#> [1] Very dissatisfied Somewhat dissatisfied Somewhat satisfied
#> [4] Very satisfied
#> 4 Levels: Very dissatisfied < Somewhat dissatisfied < ... < Very satisfied
#> --------------------------------------------------------------------------
#> [1] Female
#> Levels: Male Female
#> How to check if a factor has ordered levels, but not the order itself?
#>
#> ##########################################################################
#> utils::str()
#> tibble [1,000 × 6] (S3: tbl_df/tbl/data.frame)
#> $ age : num [1:1000] 35 27 32 64 67 31 56 42 55 53 ...
#> $ job_cat : Factor w/ 3 levels "CS, Math, Eng",..: 3 3 2 3 3 1 2 3 3 3 ...
#> $ satis_advance: Ord.factor w/ 4 levels "Very dissatisfied"<..: 4 4 3 4 4 4 2 3 4 4 ...
#> $ satis_salary : Ord.factor w/ 4 levels "Very dissatisfied"<..: 3 4 3 3 4 4 3 3 4 4 ...
#> $ satis_contrib: Ord.factor w/ 4 levels "Very dissatisfied"<..: 4 4 4 4 4 4 4 4 4 4 ...
#> $ sex : Factor w/ 2 levels "Male","Female": 2 2 2 2 2 2 2 2 2 2 ...
#>
#> ##########################################################################
#> base::class()
#> [1] "ordered" "factor"
#> --------------------------------------------------------------------------
#> [1] "factor"
#>
#> ##########################################################################
#> base::is.ordered()
#> [1] TRUE
#> --------------------------------------------------------------------------
#> [1] FALSE
#>
#> ##########################################################################
#> skimr::skim()) has a column 'ordered' about the status of the factor variable
Data summary
Name
tbl11_temp
Number of rows
1000
Number of columns
2
_______________________
Column type frequency:
factor
2
________________________
Group variables
None
Variable type: factor
skim_variable
n_missing
complete_rate
ordered
n_unique
top_counts
satis_advance
0
1
TRUE
4
Som: 356, Som: 297, Ver: 187, Ver: 160
sex
0
1
FALSE
1
Fem: 1000, Mal: 0
Listing / Output 11.29: Several options to check the order of factor levels
11.7.2 Examine satisfaction by job type for females
Example 11.9 : Examine satisfaction by job type for females with the Kruskal-Wallis test
R Code 11.30 : Examine salary satisfaction by job type for females with the Kruskal-Wallis test
Code
# examine salary satisfaction by job type for femalessat_salary_kw<-stats::kruskal.test( formula =as.integer(x =satis_salary)~job_cat, data =tbl11.4)sat_salary_kw
#>
#> Kruskal-Wallis rank sum test
#>
#> data: as.integer(x = satis_salary) by job_cat
#> Kruskal-Wallis chi-squared = 21.46, df = 2, p-value = 2.187e-05
Code
#examine salary satisfaction by agesat_salary_rho<-cor.test( formula =~as.integer(x =satis_salary)+age, method ="spearman", data =tbl11.4)
#> Warning in cor.test.default(x = mf[[1L]], y = mf[[2L]], ...): Cannot compute
#> exact p-value with ties
Code
sat_salary_rho
#>
#> Spearman's rank correlation rho
#>
#> data: as.integer(x = satis_salary) and age
#> S = 154853493, p-value = 0.025
#> alternative hypothesis: true rho is not equal to 0
#> sample estimates:
#> rho
#> 0.07087811
Listing / Output 11.30: Salary satisfaction by job type for females
I got a warning, that the test cannot compute exact p-values with ties. I didn’t see this warning in the book example.
Remember that I got different figures after the sampling procedure, but all in all the results are the sames: The satisfaction with salary was significantly associated with job type but not with age.
Report 11.6: Salary satisfaction by job type for females
The satisfaction with salary was significantly associated with job type but not with age. Specifically, there was a statistically significant relationship between job type and satisfaction with salary \(\chi^2_{KW}(2)21.46, p< 0.01\). In addition, there was a non-significant and weak positive correlation between age and salary satisfaction (rs = 0.07; p = 0.025).
R Code 11.31 : Examine society contribution satisfaction by job type for females with the Kruskal-Wallis test
Code
# examine society contribution satisfaction by job type for femalessat_contrib_kw<-stats::kruskal.test( formula =as.integer(x =satis_contrib)~job_cat, data =tbl11.4)sat_contrib_kw
#>
#> Kruskal-Wallis rank sum test
#>
#> data: as.integer(x = satis_contrib) by job_cat
#> Kruskal-Wallis chi-squared = 10.523, df = 2, p-value = 0.005187
Code
#examine society contribution satisfaction by agesat_contrib_rho<-cor.test( formula =~as.integer(x =satis_contrib)+age, method ="spearman", data =tbl11.4)
#> Warning in cor.test.default(x = mf[[1L]], y = mf[[2L]], ...): Cannot compute
#> exact p-value with ties
Code
sat_contrib_rho
#>
#> Spearman's rank correlation rho
#>
#> data: as.integer(x = satis_contrib) and age
#> S = 146366521, p-value = 0.0001128
#> alternative hypothesis: true rho is not equal to 0
#> sample estimates:
#> rho
#> 0.1218
Listing / Output 11.31: Society contribution satisfaction by job type for females
Report 11.7: Society contribution satisfaction by job type for females
The satisfaction with society contribution was significantly associated with job type and also with age. Specifically, there was a statistically significant relationship between job type and satisfaction with society contribution \(\chi^2_{KW}(2)10.52, p< 0.01\). In addition, there was also a significant and a weak positive correlation between age and society contribution satisfaction (rs = 0.12; p < .001).
11.8 Avchievement 5: Estimating an ordinal logistic regression model
For ordinal categorical variables, a model is needed that can account for the order of the outcome variable.
11.8.1 NHST Step 1
Write the null and alternate hypotheses:
Wording for H0 and HA
H0: Job type and age are not helpful in explaining satisfaction with salary for female college graduates.
HA: Job type and age are helpful in explaining satisfaction with salary for female college graduates.
11.8.2 NHST Step 2
Compute the test statistic.
The ordinal regression model is estimated using the polr() function from the {MASS} package (see: Section A.47).
R Code 11.32 : Compute the statistics for the ordinal logistic regression model
Code
# ordinal logistic regression for salary satisfaction# model salary satisfaction based on job type and ageolm11.1<-MASS::polr( formula =satis_salary~job_cat+age, data =tbl11.4)save_data_file("chap11", olm11.1, "olm11.1.rds")summary(object =olm11.1)
#>
#> Re-fitting to get Hessian
#> Call:
#> MASS::polr(formula = satis_salary ~ job_cat + age, data = tbl11.4)
#>
#> Coefficients:
#> Value Std. Error t value
#> job_catOther Sciences -0.68030 0.210633 -3.230
#> job_catNonscience -0.73586 0.156240 -4.710
#> age 0.01168 0.004934 2.367
#>
#> Intercepts:
#> Value Std. Error t value
#> Very dissatisfied|Somewhat dissatisfied -2.0899 0.2471 -8.4587
#> Somewhat dissatisfied|Somewhat satisfied -0.9366 0.2377 -3.9398
#> Somewhat satisfied|Very satisfied 1.0842 0.2384 4.5473
#>
#> Residual Deviance: 2515.41
#> AIC: 2527.41
Code
# estimate null modelolm11.0<-MASS::polr( formula =satis_salary~1, data =tbl11.4)# job model chi-squaredsalary_chisq<-olm11.0$deviance-olm11.1$deviance# degrees of freedom for chi-squaredsalary_df<-base::length(x =olm11.1$coefficients)-base::length(x =olm11.0$coefficients)# pvalue for chi-squaredsalary_p<-stats::pchisq( q =salary_chisq, df =salary_df, lower.tail =FALSE)# put together and printmodelsig_salary<-base::round(x =c(salary_chisq, salary_df, salary_p), 3)base::names(x =modelsig_salary)<-c("Chi-squared", "d.f.", "p")modelsig_salary
#> Chi-squared d.f. p
#> 26.785 3.000 0.000
Listing / Output 11.32: Computing the ordinal logistic regression model
Similar to the multinomial model, the model summary includes the residual deviance but not the null deviance to compute the model chi-squared. Following the strategy used for the multinomial model, we had to compute the null deviance by estimating a model with no predictors and computing the chi-squared using the deviance values from the two models.
The model chi-squared is 26.79 with 3 degrees of freedom.
11.8.3 NHST Step 3
Review and interpret the test statistics: Calculate the probability that your test statistic is at least as big as it is if there is no relationship (i.e., the null is true).
The p-value for \(χ^2(3) = 26.79\) is less than .001.
11.8.4 NHST Step 4
Conclude and write report.
We reject the null hypothesis. Job type and age statistically significantly help to predict satisfaction with salary for female college graduates [\(χ2(3) = 26.79; p < .001\)].
R Code 11.33 : Ordinal logistic regression model fit
Code
# observed vs. predicted category for each observationfit_salary_abs<-table( observed =olm11.1$model$satis_salary, predicted =stats::predict(object =olm11.1))fit_salary_abs
#> predicted
#> observed Very dissatisfied Somewhat dissatisfied
#> Very dissatisfied 0 0
#> Somewhat dissatisfied 0 0
#> Somewhat satisfied 0 0
#> Very satisfied 0 0
#> predicted
#> observed Somewhat satisfied Very satisfied
#> Very dissatisfied 126 0
#> Somewhat dissatisfied 184 0
#> Somewhat satisfied 454 1
#> Very satisfied 234 1
Code
# observed vs. predicted category for each observationfit_salary_perc<-prop.table(x =table( observed =olm11.1$model$satis_salary, predicted =predict(object =olm11.1)), margin =1)fit_salary_perc
#> predicted
#> observed Very dissatisfied Somewhat dissatisfied
#> Very dissatisfied 0.000000000 0.000000000
#> Somewhat dissatisfied 0.000000000 0.000000000
#> Somewhat satisfied 0.000000000 0.000000000
#> Very satisfied 0.000000000 0.000000000
#> predicted
#> observed Somewhat satisfied Very satisfied
#> Very dissatisfied 1.000000000 0.000000000
#> Somewhat dissatisfied 1.000000000 0.000000000
#> Somewhat satisfied 0.997802198 0.002197802
#> Very satisfied 0.995744681 0.004255319
Listing / Output 11.33: Ordinal logistic regression model fit
Warning 11.2: Predicted values wrong!
With the exception of two values all predicted values are “Somewhat satisfied”. That seems strange! But the result is that the model predicted 455 (45,5%) of the observations in contrast to 267 (26.7%). That is much better than the figures from the book.
But I still think that there may be something wrong in my computation.
R Code 11.34 : Compute odds ratios and confidence intervals
Code
# odds ratios and confidence intervalsor_sal<-data.frame(OR =exp(x =olm11.1$coefficients), CI =exp(x =confint(object =olm11.1)))
#> Waiting for profiling to be done...
#>
#> Re-fitting to get Hessian
Code
or_sal
#> OR CI.2.5.. CI.97.5..
#> job_catOther Sciences 0.5064636 0.3348739 0.7649294
#> job_catNonscience 0.4790949 0.3522406 0.6500583
#> age 1.0117454 1.0020218 1.0215952
Listing / Output 11.34: Odds ratios and confidence intervals
Besides that I get different numbers because of different case distribution from the sampling procedures, the values here are — in contrast to the predict values — plausible.
For ordinal models, the odds ratios are called proportional odds ratios and are the increases or decreases in odds of being in a higher group or groups versus all the lower groups for each one-unit increase in the predictor.
As an example follows the other sciences predictor:
Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very satisfied compared to the other satisfaction categories (OR = 0.48; 95% CI: 0.35–0.65).
Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very or somewhat satisfied compared to the other satisfaction categories (OR = 0.48; 95% CI: 0.35–0.65).
Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very or somewhat satisfied or somewhat dissatisfied compared to very dissatisfied (OR = 0.48; 95% CI: 0.35–0.65).
11.9 Achievement 6: Checking assumptions
Besides the assumption of independent observations that was already several times met, the proportional odds is another assumption for ordered logistic regression models.
The proportional odds assumption requires that the odds for every shift from category to category of the outcome are the same for each level of the predictors. For example, say the odds of someone being in the very dissatisfied group compared to the somewhat dissatisfied group were 2.5 times higher in the non-science group compared to the computer science, math, or engineering group. The proportional odds assumption would require that the odds of someone being in the somewhat dissatisfied group compared to the somewhat satisfied group would also need to be 2.5 times higher in the non-science compared to computer science, math, and engineering group.
In the {ordinal} package, the nominal_test() function tests the proportional odds assumption. The null hypothesis for this is that the proportional odds assumption is met; the alternate hypothesis is that the proportional odds assumption is not met. The assumption is checked for each predictor in the model.
Unfortunately, nominal_test() does not like polr objects, so the model has to be re-estimated using clm() from the ordinal package.
R Code 11.35 : Checking proportional odds assumption for an ordered logistic regression model
Code
# check proportional odds assumptionordinal::nominal_test( object =ordinal::clm( formula =satis_salary~job_cat+age, data =tbl11.4))
The p-values are .16 and .93, so the null hypothesis is retained for the job type predictor and for the age predictor. The proportional odds assumption is met for this model.
11.9.1 Summary
Report 11.8
An ordinal logistic regression using job type and age was better at predicting satisfaction with salary among female college graduates than a baseline model including no predictors [χ2(3) = 28.89; p < .001]. - The model met its assumptions and correctly predicted 455 of the 1,000 (45,5%) observations. - Female college graduates in non-science careers have 49% lower odds than those in computer science, math, or engineering of being very satisfied with their salary compared to being in another satisfaction group. - Likewise, female college graduates in other sciences had 52% lower odds than those in computer science, math, or engineering of being very satisfied with their salary compared to being in another satisfaction group. - There was no significant relationship between age and salary satisfaction.
11.10 Exercises (empty)
11.11 Glossary
term
definition
Chi-squared
Chi-squared is the test statistic following the chi-squared probability distribution; the chi-squared test statistic is used in inferential tests, including examining the association between two categorical variables and determining statistical significance for a logistic regression model. (SwR, Glossary)
Hausman-McFadden
The Hausman-McFadden test is a consistency test for multinomial logit models. If the independance of irrelevant alternatives applies, the probability ratio of every two alternatives depends only on the characteristics of these alternatives. (help page hfmtest() in the {mlogit} package)
IIA
Independence of irrelevant alternatives (IIA) is an assumption of multinomial logistic regression that requires the categories of the outcome to be independent of one another; for a three-category outcome variable with Categories A, B, and C, the probability of being in Category A compared to Category B cannot change because Category C exists. (SwR, Glossary)
Kruskal-Wallis
Kruskal-Wallis test is used to compare ranks across three or more groups when the normal distribution assumption fails for analysis of variance (ANOVA) (SwR, Glossary)
Null Hypothesis
The null hypothesis (H0, or simply the Null) is a statement of no difference or no association that is used to guide statistical inference testing (SwR, Glossary)
p-value
The p-value is the probability that the test statistic is at least as big as it is under the null hypothesis (SwR, Glossary)
Proportional-Odds-Ratios
Proportional odds ratios are odds ratios resulting from ordinal regression that represent the odds of being in a higher group or groups compared to being in all the lower groups with each one-unit increase in the predictor. (SwR, Glossary)
SwR
SwR is my abbreviation of: Harris, J. K. (2020). Statistics With R: Solving Problems Using Real-World Data (Illustrated Edition). SAGE Publications, Inc.
# Multinomial and ordinal logistic regression {#sec-chap11}```{r}#| label: setup#| include: falseoptions(warn =0) # default value: change for debugging. See: ?warningbase::source(file ="R/helper.R")ggplot2::theme_set(ggplot2::theme_bw()) ```## Achievements to unlock::: {#obj-chap11}::: my-objectives::: my-objectives-headerObjectives for chapter 11:::::: my-objectives-container**SwR Achievements**- **Achievement 1**: Using exploratory data analysis for multinomial logistic regression (@sec-chap11-achievement1)- **Achievement 2**: Estimating and interpreting a multinomial logistic regression model (@sec-chap11-achievement2)- **Achievement 3**: Checking assumptions for multinomial logistic regression (@sec-chap11-achievement3)- **Achievement 4**: Using exploratory data analysis for ordinal logistic regression (@sec-chap11-achievement4)- **Achievement 5**: Estimating and interpreting an ordinal logistic regression models (@sec-chap11-achievement5)- **Achievement 6**: Checking assumptions for ordinal logistic regression (@sec-chap11-achievement6)::::::Achievements for chapter 11:::## The diversity dilemma in STEMThere is a lack of diversity in the science, technology, engineering,and math (STEM) fields and specifically about the lack of women. Thereare fewer women college graduates in computer science and math jobs nowcompared to 15 years ago.There are three main reasons cited for fewer women in STEM:- beliefs about natural ability,- societal and cultural norms,- and institutional barriers.One thing that appeared to encourage women in STEM is the visibility ofother women in STEM careers.## Resources & Chapter Outline### Data, codebook, and R packages {#sec-chap04-data-codebook-packages}::: my-resource::: my-resource-headerData, codebook, and R packages for learning about descriptive statistics:::::: my-resource-container**Data**Three options for accessing the data:1. Download and save the original SAS file `stem-nsf-2017-ch11.xpt` from <https://edge.sagepub.com/harris1e> and run the code in the first code chunk to clean the data.2. Download and save the original SAS file `stem-nsf-2017-ch11.xpt` from <https://edge.sagepub.com/harris1e> and follow the steps in Box 11.1 to clean the data.3. Download and save the original 2017 National Survey of College Graduates data from the National Science Foundation’s SESTAT Data Tool (https://ncsesdata.nsf.gov/datadownload/) and follow Box 11.1 to clean the data.As there is nothing new for me in the recoding procedures I will go forthe first option.**Codebook**Two options for accessing the codebook:- Download the `stem-nsf-2017-ch11-codebook.pdf` from<https://edge.sagepub.com/harris1e>- Use the version that comes when downloading the raw data file from the National Science Foundation’s SESTAT Data Tool (https://ncsesdata.nsf.gov/datadownload/)**Packages**1. Packages used with the book (sorted alphabetically)- {**Hmsic**}: @sec-Hmisc (Frank Harrell)- {**MASS**}: @sec-MASS (Brian Ripley)- {**mlogit**}: @sec-mlogit (Yves Croissant)- {**nnet**}: @sec-nnet (Brian Ripley)- {**ordinal**} @sec-ordinal (Rune Haubo Bojesen Christensen)- {**scales**} @sec-scales (Thomas Lin Pedersen) (not mentioned in the book)- {**tableone**} @sec-tableone (Kazuki Yoshida)- {**tidyverse**}: @sec-tidyverse (Hadley Wickham)2. My additional packages (sorted alphabetically)- {**dfidx**}: @sec-dfidx (Yves Croissant)- {**glue**}: @sec-glue (Jennifer Bryan)- {**haven**}: @sec-haven (Hadley Wickham)- {**skimr**}: @sec-skimr (Elin Waring)::::::### Get & recode data::: my-r-code::: my-r-code-header::: {#cnj-chap11-get-data}: Get and recode data for chapter 11::::::::: my-r-code-container::: {#lst-chap11-get-data}```{r}#| label: get-data#| eval: false## using zip file because of GitHub file limit of 100 MBtbl11 <- utils::unzip(zipfile ="data/chap11/stem-nsf-2017-ch11.xpt.zip", files ="stem-nsf-2017-ch11.xpt" ) |> Hmisc::sasxport.get()# function to recode the satisfaction variablesRecSatis <-function(x){return(forcats::fct_recode(x,"Very satisfied"="1" ,"Somewhat satisfied"="2","Somewhat dissatisfied"="3","Very dissatisfied"="4",NULL ="L") )}# recode and renametbl11.1<- tbl11 |> dplyr::select(n2ocprmg, satadv, satsal, satsoc, gender, age) |> dplyr::mutate(job_cat = forcats::as_factor( forcats::fct_recode(.f = n2ocprmg,"CS, Math, Eng"="1","Other Sciences"="2","Other Sciences"="3","Other Sciences"="4","CS, Math, Eng"="5",NULL ="6","Nonscience"="7",NULL ="8" ) ) ) |> dplyr::mutate(satis_advance =RecSatis(x = satadv)) |> dplyr::mutate(satis_salary =RecSatis(x = satsal)) |> dplyr::mutate(satis_contrib =RecSatis(x = satsoc)) |> dplyr::mutate(sex = dplyr::recode(.x = gender, "M"="Male", "F"="Female")) |> dplyr::mutate(sex = forcats::fct_relevel(.f = sex, c("Male", "Female"))) |> dplyr::mutate(age =as.numeric(x = age)) |> dplyr::select(-n2ocprmg, -satadv, -satsal, -satsoc, -gender) |> haven::zap_label()# # make sure the reordering worked# # re-order to have male first for ref group# print(levels(x = tbl11.1$sex))save_data_file("chap11", tbl11.1, "tbl11.1.rds")```Get and recode data for chapter 11:::(*For this R code chunk is no output available*)::::::------------------------------------------------------------------------At first I thought that there are no new things in recoding the data forchapter 11. But it turned out that there are some issues to report:1. **Using `haven::read_xpt()` instead of `Hmisc::sasxport.get()`**This was an error in two respects:- The variable names were not converted to lower case. So I had to change all variable names in the following recoding.- The {**haven**} function was *extremely* slow! In contrast to`sasxport.get()` with 3.94 seconds the file export took 104.12 second, e.g. more than 26 times longer!I therefore returned to the much fast solution with`Hmisc::sasxport.get()`.------------------------------------------------------------------------2. **Labelled data**I got with the export of a SAS transport file a labelled data frame withvery long labels. After the recoding I lost many of these labels exceptof two columns. Therefore I used `haven::zap_label()` to remove allvariable labels.------------------------------------------------------------------------3. **The original data file is too big for GitHub**After I committed to GitHub I got an error, because the file`stem-nsf-2017-ch11.xpt` was too large. I compressed it as `.zip`-fileand changed the import code slightly to adapt this change. After testingthat it worked I deleted the uncompressed file.------------------------------------------------------------------------4. **Using the {forcats} package**I changed the factor levels in the `RecSatis()` function with the{**forcats**} package. ### Show raw data::: my-example::: my-example-header::: {#exm-chap11-show-data}: Show summary of recoded data for chapter 11::::::::: my-example-container::: panel-tabset###### tbl11.1::: my-r-code::: my-r-code-header::: {#cnj-chap11-show-tbl11.1}: Show recoded data for chapter 11 (`tbl11.1`)::::::::: my-r-code-container::: {#lst-chap11-show-tbl11.1}```{r}#| label: show-tbl11.1#| results: holdtbl11.1<- base::readRDS("data/chap11/tbl11.1.rds")glue::glue("********** Summarizing with base:summary() **************")base::summary(tbl11.1)glue::glue(" ")glue::glue(" ")glue::glue("********** Summarizing with skimr::skim() **************")glue::glue(" ")skimr::skim(tbl11.1)```Show recoded data for chapter 11 (`tbl11.1`):::------------------------------------------------------------------------- **job_cat**: Job caktegory of current job. `n2ocprmg` was the original variable name. Recoded into three categories: - CS, Math, Eng = Computer science, math, and engineering fields - Other sciences = Other science fields - Nonscience = Not a science field- **satis_advance**: Satisfaction with advancement opportunity.`satadv` was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied.- `satis_salary`: Satisfaction with salary. `satsal` was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied.- **satis.contrib**: Satisfaction with contribution to society.`satsoc` was the original variable name. 4-point Likert scale from 4 = very dissatisfied to 1 = very satisfied- **sex**: gender was the original variable name. Two categories: Female, Male- **age**: Age in years, not recoded or renamed::::::###### sample::: my-r-code::: my-r-code-header::: {#cnj-chap11-sample-by-group}: Sample 1500 cases: 500 from each job category::::::::: my-r-code-container::: {#lst-chap11-sample-by-group}```{r}#| label: sample-by-group#| results: holdtbl11.1<- base::readRDS("data/chap11/tbl11.1.rds")base::set.seed(seed =143)# take a sample of 1500 cases# 500 from each job.cat categorytbl11.2<- tbl11.1|> tidyr::drop_na(job_cat) |> dplyr::group_by(job_cat) |> dplyr::slice_sample(n =500)save_data_file("chap11", tbl11.2, "tbl11.2.rds")glue::glue("********** Summarizing with base:summary() **************")base::summary(tbl11.2)glue::glue(" ")glue::glue(" ")glue::glue("********** Summarizing with skimr::skim() **************")glue::glue(" ")skimr::skim(tbl11.2)```Show sampled data: 500 from each job category::::::::::::::::::## Achievement 1: EDA for multinomial logistic regression {#sec-chap11-achievement1}### Visualizing employment:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-eda-employment}: Visualizing employment in computer science, math, and engineering by sex and age:::::::::::::{.my-example-container}::: {.panel-tabset}###### sex-jobs:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-sex-wihtin-jobtype}: Plotting distribution of sex within job type:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-sex-wihtin-jobtype}```{r}#| label: eda-sex-wihtin-jobtypetbl11.2<- base::readRDS("data/chap11/tbl11.2.rds")# plotting distribution of sex within job type (Figure 11.3)tbl11.2|> ggplot2::ggplot( ggplot2::aes(x = sex, group = job_cat,y = ggplot2::after_stat(prop) ) ) + ggplot2::geom_bar(fill ="#7463AC") + ggplot2::labs(y ="Percent within job category", x ="Sex" ) +# ggplot2::facet_grid(cols = ggplot2::vars(job_cat)) +# using another, more simple facet_grid() function: ggplot2::facet_grid(~ job_cat) + ggplot2::scale_y_continuous(labels = scales::percent)```Distribution of sex within job type among 1,500 college graduates in 2017:::***`ggplot2::after_stat()` replaces the old approach surrounding the variable names with .., e.g. `..prop..`. {**ggplot2**} throws a warning:> #> Warning: The dot-dot notation (`..prop..`) was deprecated in ggplot2 3.4.0.>> #> ℹ Please use `after_stat(prop)` instead.At first I had problems, because I used `y = ggplot2::after_stat(count/sum(count))` inside the `ggplot2::aes()` function. This calculated the percentage over all different categories and not within each job category. The I learned with **The 'computed variables' section in each stat lists which variables are available to access.** that {**ggplot2**} computes with the `ggplot2::stat_count()` function for bar charts also groupwise proportion with `ggplot2::after_stat(prop)`.::::::::::::::{.my-resource}:::{.my-resource-header}:::::: {#lem-chap11-using-ggplot2-after-stat}: How to use ggplot2::after_stat()?:::::::::::::{.my-resource-container}To learn how to use the `ggplot2::after_stat()` function:- Read the help page to understand the differences between the different stages of mapping (direct input, `after_stat()` and `after_scale()`). Very important is the sentence: **The 'computed variables' section in each stat lists which variables are available to access.**- Read the short article [Using after_stat() in {**ggplot2**}](https://rstudio-pubs-static.s3.amazonaws.com/789869_e4500f2be0ba45279290b1753d8358bc.html) to use `after_stat()` to show percentages in the bar chart. - The first article of the very extensive series of articles going into many technical detail working --- at least for me --- as an eye opener how {**ggplot2**} works [Demystifying delayed aesthetic evaluation: Part 1](https://yjunechoe.github.io/posts/2022-03-10-ggplot2-delayed-aes-1/).- Hadley Wickham is currently preparing online the third edition of [ggplot2: Elegant Graphics for Data Analysis](https://ggplot2-book.org/) which also has many details about the `after_stat()` function, for instance in [13 Build a plot layer by layer](https://ggplot2-book.org/layers.html#sec-stat). :::::::::###### jobs by sex:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-jobtype-sex}: Distribution of job type by sex:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-jobtype-sex} ```{r}#| label: eda-jobtype-sex# plotting distribution of job type by sex (Figure 11.4)tbl11.2|> ggplot2::ggplot( ggplot2::aes(x = job_cat, group = sex,y = ggplot2::after_stat(prop) ) ) + ggplot2::geom_bar(fill ="#7463AC") + ggplot2::labs(y ="Percent within sex category", x ="Job category" ) + ggplot2::facet_grid(cols = ggplot2::vars(sex)) + ggplot2::scale_y_continuous(labels = scales::percent)```Distribution of job type by sex ::::::::::::###### jobs by age:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-jobtype-age}: Distribution of job type and age:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-jobtype-age}```{r}#| label: eda-jobtype-age# plotting distribution of job type and age (Figure 11.5)tbl11.2|> ggplot2::ggplot( ggplot2::aes(y = age, x = job_cat ) ) + ggplot2::geom_jitter( ggplot2::aes(color = job_cat ), alpha = .6 ) + ggplot2::geom_boxplot( ggplot2::aes(fill = job_cat ), alpha = .4 ) + ggplot2::scale_fill_manual(values =c("dodgerblue2","#7463AC", "gray40"), guide ="none") + ggplot2::scale_color_manual(values =c("dodgerblue2","#7463AC", "gray40"), guide ="none") + ggplot2::labs(x ="Job type", y ="Age in years" )```Distribution of job type and age::::::::::::###### jobs, age & sex:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-jobtype-age-sex}: Distribution of jobtype by age and sex:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-jobtype-age-sex}```{r}#| label: eda-jobtype-age-sex# plotting distribution of job type, age, and sex (Figure 11.6)tbl11.2|> ggplot2::ggplot( ggplot2::aes(y = age, x = job_cat, fill = sex) ) + ggplot2::geom_jitter( ggplot2::aes(color = sex ), alpha = .6 ) + ggplot2::geom_boxplot( ggplot2::aes(fill = sex ), alpha = .4) + ggplot2::scale_fill_manual(values =c("gray", "#7463AC"), name ="Sex" ) + ggplot2::scale_color_manual(values =c("gray", "#7463AC"), guide ="none") + ggplot2::labs(x ="Job type", y ="Age in years" )```Distribution of job type by age and sex::::::::::::###### jobs by sex & age:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-jobtype-sex-age}: Distribution by job type sex and age:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-jobtype-sex-age}```{r}#| label: eda-jobtype-sex-age# plotting distribution of job type, sex, and age (Figure 11.7)tbl11.2|> ggplot2::ggplot( ggplot2::aes(y = age, x = job_cat) ) + ggplot2::geom_jitter( ggplot2::aes(color = sex ), alpha = .6 ) + ggplot2::geom_boxplot( ggplot2::aes(fill = sex ), alpha = .4 ) + ggplot2::scale_fill_manual(values =c("gray", "#7463AC"), guide ="none" ) + ggplot2::scale_color_manual(values =c("gray", "#7463AC"), guide ="none" ) + ggplot2::labs(x ="Job type", y ="Age in years" ) + ggplot2::facet_grid(cols = ggplot2::vars(sex))```Distribution by job type sex and age::::::::::::::::::::::::***::: {.callout #rep-chap11-visualizing-employment}##### Summary of the several plots about employment1. @lst-chap11-eda-sex-wihtin-jobtype: Computer science, math, and engineering have about a third as many females as males, other sciences and non-science were slightly more male than female.2. @lst-chap11-eda-jobtype-sex: Computer science, math, and engineering jobs were the least common for females while this category was the largest for males.3. @lst-chap11-eda-jobtype-age: While the age range for all the data appeared similar across the three job types, the computer science, math, and engineering field employed the youngest people on average.4. @lst-chap11-eda-jobtype-age-sex: In all three fields, the distribution of age showed that males have an older median age than females, and in the two science fields, the range of age is wider for males than females.5. @lst-chap11-eda-jobtype-sex-age: The lowest median age for females is in computer science, math, and engineering and higher in other sciences and non-science. The age distribution for males showed a similar pattern across the three job types. Computer science, math, and engineering has the youngest median age for both sexes.:::### Checking bivariate statistical associations:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-eda-bivariate-associations}: Checking bivariate statistical associations between job type, sex, and age:::::::::::::{.my-example-container}::: {.panel-tabset}###### age distribution:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-age-distribution}: Age distribution by job type among 1,500 college graduates in 2017:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-age-distribution}```{r}#| label: eda-age-distribution# plotting distribution of age (Figure 11.8)tbl11.2|> ggplot2::ggplot( ggplot2::aes(x = age) ) + ggplot2::geom_histogram(bins =30,fill ="#7463AC", color ="white" ) + ggplot2::labs(x ="Age in years", y ="Number of observations" ) + ggplot2::facet_grid(cols = ggplot2::vars(job_cat))```Age distribution by job type among 1,500 college graduates in 2017:::***The histograms were not normally distributed for any of the three groups.:::::::::###### statistics:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-eda-statistics}: Table of statistics to examine `job_cat`:::::::::::::{.my-r-code-container}::: {#lst-chap11-eda-statistics}```{r}#| label: eda-statistics# make a table of statistics to examine job.cattable_desc <- tableone::CreateTableOne(data = tbl11.2, strata ='job_cat',vars =c('sex', 'age') )base::print(table_desc, showAllLevels =TRUE, nonnormal ='age' )```Table of statistics to examine `job_cat`:::***The visual differences in the graphs corresponded to statistically significant differences from the `r glossary("chi-squared")` and `r glossary("Kruskal-Wallis")` tests. The median age for college graduates in computer science, math, or engineering was 3 years lower than the median age in other sciences and 6 years younger than the median age in non-science careers. Computer science, math, and engineering has more than three times as many males as females.:::::::::::::::::::::## Achievement 2: Estimating a multinomial logistic regression model {#sec-chap11-achievement2}### Introduction:::{.my-bulletbox}:::: {.my-bulletbox-header}::::: {.my-bulletbox-icon}::::::::::: {#bul-chapp1-model-reporting}::::::: Important to report with every model:::::::: {.my-bulletbox-body}- **Model significance**: Is the model significantly better than some baseline at explaining the outcome? - **Model fit:** How well does the model capture the relationships in the underlying data? - **Predictor values and significance**: What is the size, direction, and significance of the relationship between each predictor and the outcome?- **Checking model assumptions**: Are the model assumptions met?:::::::### Check reference groupsBefore starting with the computation for the multinomial logistic regression it is practicable to check the reference groups with `base::levels()`. The results are easier to interpret if the reference groups (= the first level) is consistent with what one is interested in. Otherwise use `stats::relevel()` or one of the many functions in {**forcats**}, for instance `fct_recode()` or `fct_relevel()`.:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-check-levels}: Check reference groups for regression:::::::::::::{.my-r-code-container}::: {#lst-chap11-check-levels}```{r}#| label: check-levels#| results: holdbase::levels(tbl11.2$job_cat)base::levels(tbl11.2$sex)```Reference group for `job_cat` (= "CS, Math, Eng") and `sex` (= "Male"):::***The reference group are fine; no change is necessary.:::::::::### NHST Step 1Write the null and alternate hypotheses:::: {.callout-note}- **H0**: A multinomial model including sex and age is not useful in explaining or predicting job type for college graduates.- **HA**: A multinomial model including sex and age is useful in explaining or predicting job type for college graduates.:::### NHST Step 2A Google search revealed the most of the R tutorials use the {**nnet**} package recommended also by `r glossary("SwR")`. A newer approach uses the meta-package {**tidymodel**} (similar to **tidyverse**) which collects 22 packages for modeling, containing {**parsnip**} with the `multinom_reg()` function that ca fit different classification models, including {**nnet**} as default package.:::::: {#tdo-chap11-learn-tidymodels}:::::{.my-checklist}:::{.my-checklist-header}TODO: Learn {**tidymodels**}:::::::{.my-checklist-container}I already learned from the {**tidymodels**} approach three-four years ago. But at that time I thought that it is too advanced for my skill level. This has changed now. I have worked through all of the three pre-requisites mentioned on the [start page of tidymodels](https://www.tidymodels.org/start/). And now --- coming to the end of `r glossary("SwR")` --- I understand why this unification project is important.:::::::::Learn [{**tidymodels**}](https://www.tidymodels.org/)::::::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-multinom-computation}: Computing a multinomial logical regression:::::::::::::{.my-example-container}::: {.panel-tabset}###### model:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-estimate-multinomial-model}: Estimate model and print summary:::::::::::::{.my-r-code-container}::: {#lst-chap11-estimate-multinomial-model}```{r}#| label: estimate-multinomial-model# estimate the model and print its summarymnm11.1<- nnet::multinom(formula = job_cat ~ age + sex + age*sex,data = tbl11.2,model =TRUE)save_data_file("chap11", mnm11.1, "mnm11.1.rds")summary(object = mnm11.1)```Computing a multinomial regression model for job types by age and sex with interaction ::::::::::::###### null model:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-estimate-multinomial-null-model}: Estimate null model:::::::::::::{.my-r-code-container}::: {#lst-chap11-estimate-multinomial-null-model} ```{r}#| label: estimate-multinomial-null-model# multinomial null modelmnm11.0<- nnet::multinom(formula = job_cat ~1,data = tbl11.2,model =TRUE)summary(object = mnm11.0)```Multinomial null model::::::::::::###### test statistics:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-mnm-test-statistics}: Compute test statistics for the multinomial model `mnm11.1`:::::::::::::{.my-r-code-container}::: {#lst-chap11-mnm-test-statistics}```{r}#| label: mnm-test-statistics# get the job model chi-squaredjob_chisq <- mnm11.0$deviance - mnm11.1$deviance# get the degrees of freedom for chi-squaredjob_df <-length(x =summary(object = mnm11.1)$coefficients) -length(x =summary(object = mnm11.0)$coefficients)# get the p-value for chi-squaredjob_p <- stats::pchisq(q = job_chisq, df = job_df, lower.tail =FALSE )# put together into a vector and round to 3 decimal placesmodel_sig <- base::round(x =c(job_chisq, job_df, job_p), 3)# add names to the vectorbase::names(x = model_sig) <-c("Chi-squared", "df", "p")# print the vectormodel_sig```Test statistics for the multinomial model::::::::::::::::::::::::**Finishing step 2 of the NHST procedure:**Compute the test statistics.The test statistic is a chi-squared of 124.77 with 6 degrees of freedom.### NHST Step 3Review and interpret the test statistics: Calculate the probability that your test statistic is at least as big as it is if there is no relationship (i.e., the null is true).The probability computed for the chi-squared was < .001.### NHST Step 4Conclude and write report.::: {.callout #rep-chap11-mnm11.1}##### Report the conclusion of the interpretation of the multinomial model `mnm11.1`We have to reject the null hypothesis and conclude that a model including age, sex, and age*sex explained job type statistically significantly better [$χ^2(6) = 124.77; p < .001$] than a null model with no predictors.:::### Multinomial model fit:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-mnm-fit}: Multinomial model fit:::::::::::::{.my-example-container}::: {.panel-tabset}###### fit & predict:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-show-fit-predict-values}: Show `fitted.values` and `predict()` results:::::::::::::{.my-r-code-container}::: {#lst-chap11-show-fit-predict-values}```{r}#| label: show-fit-predict-values#| results: holddf1 <-my_glance_data(data.frame(mnm11.1$fitted.values))df2 <-my_glance_data(data.frame(predicted = stats::predict(mnm11.1)))dplyr::full_join(df1, df2, by = dplyr::join_by(obs))```Random example rows of `fitted.values` to compare with the results from the `predict()` function:::***- `obs` column: Number of row taken from the sample data `tbl11.2`.- The next column are the predicted probability for each person to be in each of the three job type groups. The data are taken from the `fitted-values` result of the multinomial model `mnm11.1`.- The last column predict the job category for each randomly chosen person. This is always the highest probability from the `fitted.values` categories.:::::::::###### observed & predicted:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-compare-observed-predicted}: Compare observed job category with the predicted value:::::::::::::{.my-r-code-container}::: {#lst-chap11-compare-observed-predicted} ```{r}#| label: compare-observed-predicted#| results: hold# observed vs. predicted category for each observationfit_abs <- base::table(observed = mnm11.1$model$job_cat,predicted = stats::predict(object = mnm11.1))glue::glue("Absolute values: observed vs. predicted category for each observation")fit_abs# observed vs. predicted category for each observationfit_perc <- base::proportions( base::table(observed = mnm11.1$model$job_cat,predicted =predict(object = mnm11.1) ),margin =1)glue::glue(" ")glue::glue(" ")glue::glue("Percentages: observed vs. predicted category for each observation")fit_perc```Observed job category versus the predicted value of the model (absolute and percentages):::***:::::::::::::::::::::The model was best at predicting the computer science, math, or engineering job type, with 68.4% of the observations in this category correctly predicted. The nonscience job type was predicted with 37.4% accuracy, and other sciences was predicted with 25.8% accuracy. Overall, the model predicted job type correctly for 658 out of 1,500 observations (43.9%). Given that the sample included 500 people from each job type, without any other information, we would guess that everyone was in a single category and would be right for 500, or 33.3%, of the observations. Although the overall correctness was low, it was higher than this baseline probability of correctly classifying observations by job type.### Multinomial model predictor interpretationWe know that the model is statistically significantly better than baseline at explaining job type and that the predictions from the model were better than a baseline percentage would be. We also know that the prediction was best for computer science, math, and engineering. The next thing we want to examine is the predictor fit and significance.#### Predictor significance@lst-chap11-estimate-multinomial-model does not include any indication of whether or not each predictor (age, sex, age*sex) is statistically significantly associated with job type. To get statistical significance and more interpretable values, we need to compute odds ratios and 95% confidence intervals around the odds ratios.:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-predictor-significance}: Predictor significance:::::::::::::{.my-example-container}::: {.panel-tabset}###### Odds ratios:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-odds-ratios}: Get odds ratios:::::::::::::{.my-r-code-container}::: {#lst-chap11-odds-ratios}```{r}#| label: odds-ratios# get odds ratios and transpose to get 'standard' formatbase::t(x = base::exp(x = stats::coef(object = mnm11.1)))```Odds ratios:::::: {.callout-caution #cau-chap11-reference-groups}##### Watch out for the correct reference groupIt gets more complicated with this type of regression. Not only do the predictors have reference groups, but the outcome variable also has a reference group.:::The reference group for the outcome variable is computer science, math, or engineering. This was not only our result with @lst-chap11-check-levels but it is confirmed by missing this group in the result. (The missing group is always the reference group.):::::::::::: {.callout #rep-chap11-example-jobtype-age}##### Example of an interpretation of the odds ratiosFor every year older a person gets, the odds of having a career in other sciences is 1.02 times higher compared to the odds of being in computer science, math, or engineering.:::###### confidence intervals:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-confidence-intervals}: Compute confidence intervals:::::::::::::{.my-r-code-container}::: {#lst-chap11-confidence-intervals} ```{r}#| label: confidence-intervals# confidence intervals for odds ratiosbase::exp(x = stats::confint(object = mnm11.1))```Confidence intervals for odds ratios:::***Remember: A confidence interval of odds ratio is statistically significant if it does not include `1`. This is the case for `age` and `Female sex` but not for the interaction term `age:sexFemale`.:::::::::###### togehter:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-odds-ratio-confidence-intervals-table}: Put odd ratios and confidence interval together into the same data table:::::::::::::{.my-r-code-container}::: {#lst-chap11-odds-ratio-confidence-intervals-table}```{r}#| label: odds-ratio-confidence-intervals-table# get odds ratios for other sciences from the model objectoddsratio_other_sci <- base::t(x = base::exp(x = stats::coef(object = mnm11.1)))[ , 1]# get CI for other sciencesconfint_other_sci <- base::exp(x = stats::confint(object = mnm11.1))[ , 1:2, 1]# put into a data frame other_sci <- base::data.frame(oddsratio_other = oddsratio_other_sci,ci_other = confint_other_sci)# get odds ratios for non-scienceoddsratio_non_sci <- base::t(x = base::exp(x = stats::coef(object = mnm11.1)))[ , 2]# get CI for non-scienceconfint_non_sci <- base::exp(x = stats::confint(object = mnm11.1))[ , 1:2, 2]# put into a data framenon_sci <- base::data.frame(oddsratio_non = oddsratio_non_sci,ci_non = confint_non_sci)# all togetherdata.frame(other_sci, non_sci)```Odd ratios and confidence intervals of the multinomial model `mnm11.1`:::***The first three columns of numbers are the odds ratios and confidence intervals for the job type of other sciences, while columns 4 through 6 are for the non-science job type.:::::::::::::::::::::#### Predictor interpretationThe outcome variable with multiple categories now had a reference group. In this case, the reference group is computer science, math, or engineering job type. The odds ratios are interpreted with respect to this reference group. This works OK for the continuous variable of age but gets a little tricky for the categorical variable of sex, where there are now two reference groups to consider.::: {.callout #rep-chap11-predictor-interpretation}##### Predictor interpretation of the multinomial logistic regression model `mnm11.1`The age row starts with the odds ratio of 1.02 with confidence interval 1.00–1.03. For every 1-year increase in age, the odds of being in an other sciences job are 1.02 times higher than being in a computer science, math, or engineering job ($95% CI: 1.00–1.03$). Likewise, for every 1-year increase in age, the odds of being in a non-science job are 1.03 times higher than being in a computer science, math, or engineering job ($95% CI: 1.02–1.04$). Compared to males, the odds of females being in an other sciences job are 3.29 times higher than being in a computer science, math, or engineering job ($95% CI: 1.24–8.71$). Also, compared to males, females have 4.58 times higher odds of being in non-science jobs compared to computer science, math, or engineering jobs ($95% CI: 1.71–12.22$). The interaction between age and sex was not statistically significant for either other sciences jobs or non-science jobs compared to computer science, math, or engineering jobs.Overall, it seems that females had higher odds than males of being in other sciences or nonscience compared to being in computer science, math, or engineering. Likewise, the older someone gets, the more likely they are to work in other sciences or non-science compared to computer science, math, or engineering. It seems that, overall, computer science, math, or engineering job types are most likely to be held by males and people who are younger.:::## Achievement 3: Checking assumptions for multinomial logistic regression {#sec-chap11-achievement3}Besides the assumption of independence of observations (which is met), there is the `r glossary("IIA")` assumption. The independence of irrelevant alternatives assumption requires that the categories of the outcome be independent of one another. For example, the relative probability of having a job in the computer science, math, or engineering field compared to the other science field cannot depend on the existence of non-science jobs.This assumption can be tested by taking a subset of the data that includes two of the outcome categories and estimating binary logistic regression models with the same predictors. These model results can then be compared with the multinomial model results to see if the relationship is consistent. The test used for this assumption is the `r glossary("Hausman-McFadden")` test.:::::{.my-remark}:::{.my-remark-header}:::::: {#rem-chap11-iia}: What is the independence of irrelevant alternatives (IIA) assumption?:::::::::::::{.my-remark-container}The above explanation of `r glossary("IIA")` in `r glossary("SwR")` is easy to misunderstand. The important clarification is that the third alternative (C) is not an alternative of the choice between A and B. Therefore we are talking of *irrelevant* alternatives. So what we state is that the probability of choosing A or B is independent of C. The following quote from [Statistical Horizons](https://statisticalhorizons.com/iia/) brings an example that helped my understanding more than the example in SwR:> In discrete choice theory, the IIA assumption says that when people are asked to choose among a set of alternatives, their odds of choosing A over B should not depend on whether some other alternative C is present or absent. As an example, consider the 1992 U.S. presidential election. The two major party candidates were Bill Clinton and George H. W. Bush. But H. Ross Perot was also on the ballot in all 50 states. The IIA assumption says that, for each voter, the odds of choosing Clinton over Bush was not affected by Perot’s presence on the ballot. [@allison2012]The test strategy is the following: for each alternative, delete individuals who chose that alternative and re-estimate the model for the remaining alternatives; then construct a test comparing the new estimates with the original estimates.> In our voting example, for instance, we could exclude the people who voted for Perot, and estimate a binary logit model predicting Clinton vs. Bush. We could then test whether the binary coefficients were the same as the multinomial coefficients. We could also exclude the people who voted for Clinton and re-estimate the second equation by binary logit. Again, we could compare the binary coefficients with the multinomial coefficients. And, finally, we could redo the test with Bush as the excluded category.::::::::::::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-hausman-mcfadden}: Compute the Hausman-McFadden test for independence of irrelevant alternatives:::::::::::::{.my-example-container}::: {.panel-tabset}###### model (re-)estimate:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-model-re-estimate}: Re-estimate the model with {**mlogit**}:::::::::::::{.my-r-code-container}::: {#lst-chap11-model-re-estimate}```{r}#| label: model-re-estimate# reshape data to use with the dfidx function from {dfidx}tbl11.2<- base::readRDS("data/chap11/tbl11.2.rds")tbl11.2_wide <- dfidx::dfidx(data = tbl11.2,choice ="job_cat",shape ="wide")# estimate the model and print its summarymnm3 <- mlogit::mlogit(formula = job_cat ~0| age + sex + age*sex,data = tbl11.2_wide)summary(object = mnm3)```Model re-estimated with the {**mlogit**} package.:::***The function `mlogit::mlogit.data()` used in the book is deprecated and should be replaced with `dfidx()` from the {**dfidx**} package (see: @sec-dfidx).:::::::::###### two categories:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-estimate-two-categories}: Estimate the model with two outcome categories:::::::::::::{.my-r-code-container}::: {#lst-chap11-estimate-two-categories} ```{r}#| label: estimate-two-categories# estimate the model with two outcome categories and print its summarymnm3_alt <- mlogit::mlogit(formula = job_cat ~0| age + sex + age*sex,data = tbl11.2_wide,alt.subset =c("CS, Math, Eng", "Nonscience"))summary(object = mnm3_alt)```Model estimated with two outcome categories::::::::::::###### hfmtest():::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-hausman-mcfadden-test}: Hausman-McFadden test:::::::::::::{.my-r-code-container}::: {#lst-chap11-hausman-mcfadden-test}```{r}#| label: hausman-mcfadden-testmlogit::hmftest(x = mnm3, z = mnm3_alt)```Hausman-McFadden test:::The `r glossary("p-value")` was .97, which is much higher than .05, so the `r glossary("null hypothesis")` is retained and the `r glossary("IIA")` assumption is met.:::::::::::::::::::::### Conclusion of the multinomial logistic regression::: {.callout #rep-chap11-multinomial-logistic-regression-final}##### Report of the multinomial logistic regression of job types versus age and sex (final version)A multinomial logistic regression including age, sex, and the interaction between age and sex was statistically significantly better at predicting job type than a null model with no predictors [$χ^2(6) = 124.77; p < .001$]. The model met its assumptions and correctly predicted the job type for 43.9% of observations. - For every 1-year increase in age, the odds of being in an other sciences job are 1.02 times higher than being in a computer science, math, or engineering job (95% CI: 1.00–1.03). - Likewise, for every 1-year increase in age, the odds of being in a nonscience job are 1.03 times higher than being in a computer science, math, or engineering job (95% CI: 1.02–1.04). - Compared to males, the odds of females being in an other sciences job are 3.29 times higher than being in a computer science, math, or engineering job (95% CI: 1.24–8.71). - Also, compared to males, females have 4.58 times higher odds of being in nonscience jobs compared to computer science, math, or engineering jobs (95% CI: 1.71–12.22). - The interaction between age and sex was not a statistically significant indicator of job type.:::## Achievement 4: EDA for ordinal logistic regression {#sec-chap11-achievement4}### IntroductionWe are not going to compare satisfaction of women to the satisfaction of men with computer science, math, or engineering. Out interest is in understanding whether job satisfaction differs for women across the three job types.We will take a sample of female participants from the original data frame so that we would have a larger number in the sample than using the females from the subset of 1,500. Since there were very few people (relatively speaking) in the dissatisfied categories (see @lst-chap11-sample-by-group), we will take 250 people from each category of one of the satisfaction variables to ensure to get enough people in the dissatisfied categories.:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-eda-ordinal-logistic-regression}: Exploratory data analysis for a ordinal logistic regression models:::::::::::::{.my-example-container}::: {.panel-tabset}###### sample:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-get-sample-females}: Sample of 1,000 females:::::::::::::{.my-r-code-container}::: {#lst-chap11-get-sample-females}```{r}#| label: get-sample-femalestbl11.1<- base::readRDS("data/chap11/tbl11.1.rds")base::RNGkind(sample.kind ="Rejection")set.seed(seed =143)tbl11.3<- tbl11.1|> tidyr::drop_na(job_cat) |> dplyr::filter(sex =="Female") |> dplyr::group_by(satis_contrib) |> dplyr::slice_sample(n =250) |> dplyr::ungroup()save_data_file("chap11", tbl11.3, "tbl11.3.rds")# check worksummary(object = tbl11.3)```Sample of 1,000 females:::::: {.callout-warning #wrn-chap11-different-sample-values}##### Different sample figures with the same `set.seed()` commandI got different figures after data sampling. I do not know from where the difference comes from. I had tried exactly the same code (e.g., using the deprecated function `sample_n()`), also I changed the `set.seed()` command to `base::RNGkind(sample.kind = "Rounding")` to meet the randomized sampling before version R 3.6.0. But in every case I got different figures than in the book example.::::::::::::###### job-society:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-job-satisfaction-society}: Job satisfaction by society contribution:::::::::::::{.my-r-code-container}::: {#lst-chap11-job-satisfaction} ```{r}#| label: job-satisfaction-society# job satisfaction in job typetbl11.3|> ggplot2::ggplot( ggplot2::aes(x = job_cat, fill = satis_contrib ) ) + ggplot2::geom_bar(position ="fill") + ggplot2::coord_flip() + ggplot2::labs(x ="Job type", y ="Percent" ) + ggplot2::scale_fill_brewer(name ="How satisfied\nwith contribution\nto society?",palette ="Purples",direction =-1) + ggplot2::scale_y_continuous(labels = scales::percent)```Job satisfaction by society contribution::::::::::::###### job-salary:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-job-satisfaction-salary}: Job satisfaction by salary:::::::::::::{.my-r-code-container}::: {#lst-chap11-job-satisfaction-salary} ```{r}#| label: job-satisfaction-salary# job satisfaction by salary (Figure 11.14)tbl11.3|> ggplot2::ggplot( ggplot2::aes(x = job_cat, fill = satis_salary ) ) + ggplot2::geom_bar(position ="fill") + ggplot2::coord_flip() + ggplot2::labs(x ="Job type", y ="Percent" ) + ggplot2::scale_fill_brewer(name ="How satisfied\nwith salary?",palette ="Purples",direction =-1) + ggplot2::scale_y_continuous(labels = scales::percent)```Job satisfaction by salary::::::::::::###### job-advance:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-job-satisfaction-advance}: Job satisfaction by advance of science:::::::::::::{.my-r-code-container}::: {#lst-chap11-job-satisfaction-advance} ```{r}#| label: job-satisfaction-advance# job satisfaction by advancetbl11.3|> ggplot2::ggplot( ggplot2::aes(x = job_cat, fill = satis_advance ) ) + ggplot2::geom_bar(position ="fill") + ggplot2::coord_flip() + ggplot2::labs(x ="Job type", y ="Percent" ) + ggplot2::scale_fill_brewer(name ="How satisfied\nwith advance\nof science?",palette ="Purples",direction =-1) + ggplot2::scale_y_continuous(labels = scales::percent)```Job satisfaction by advance of science::::::::::::###### job-salary-age:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-job-satisfaction-salary-age}: Job satisfaction with salary by age:::::::::::::{.my-r-code-container}::: {#lst-chap11-job-satisfaction-salary-age}```{r}#| label: job-satisfaction-salary-age# job satisfaction by age (Figure 11.15)tbl11.3|> ggplot2::ggplot( ggplot2::aes(y = age, x = job_cat, fill = satis_salary ) ) + ggplot2::geom_jitter( ggplot2::aes(color = satis_salary ), alpha = .6 ) + ggplot2::geom_boxplot( ggplot2::aes (fill = satis_salary), alpha = .4 ) + ggplot2::scale_fill_brewer(name ="How satisfied\nwith salary\nby age?",palette ="Purples",direction =-1) + ggplot2::scale_color_brewer(name ="How satisfied\nwith salary\nby age?",palette ="Purples",direction =-1 ) + ggplot2::labs(x ="Job type", y ="Age in years" )```Job satisfaction with salary by age::::::::::::###### ordered:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-ordered-factors}: Create Likert-scale with ordered factors:::::::::::::{.my-r-code-container}::: {#lst-chap11-ordered-factors}```{r}#| label: ordered-factorsOrderSatis <-function(x){return(ordered(x, levels =c("Very dissatisfied","Somewhat dissatisfied","Somewhat satisfied","Very satisfied") ) )}# use function to order 3 satisfaction variablestbl11.4<- tbl11.3|> dplyr::mutate(satis_advance =OrderSatis(x = satis_advance)) |> dplyr::mutate(satis_salary =OrderSatis(x = satis_salary)) |> dplyr::mutate(satis_contrib =OrderSatis(x = satis_contrib))save_data_file("chap11", tbl11.4, "tbl11.4.rds")# check the dataskimr::skim(tbl11.4)```{**skimr**} shows that the satisfaction factors are now ordered factors.:::***With this change I had some troubles, because I haven't had anyexperience how to do and also to check if the levels are ordered or not. The check in the book with `base::summary` does not reveal if the factors are ordered or not. The `summary()` reports the sequence of the levels but not if they are ordered.You can't use the function `base::levels()` neither, because it also prints out only the chronological sequence but not if this sequence consists of ordered factor levels.::: {#imp-chap11-ordered-factor-levels .callout-important}##### No possibility found in {forcats} to create factor with ordered levelsI could manipulate the (chronological) *appearance* of levels in manyways but I did not find an option to create the class`"ordered" "factor"`.Therefore I have to use one of the following base R options options:- `base::as.ordered()`- `base::factor(x = c("A", "Z", "M"), levels = c("A", "B", "M", "Z"), ordered = TRUE)`- `base::ordered(c("A", "Z", "M"), level = c("Z", "M", "A"))`:::The following examples uses in the first line with`tbl11.1$satis_advance` an ordered factor, and with the second line(after the '---' line) with `tbl11.1$sex` a factor without order.::: my-r-code::: my-r-code-header::: {#cnj-chap11-checking-levels-order}: How to check the order of factor levels?::::::::: my-r-code-container::: {#lst-chap11-checking-levels-orderD}```{r}#| label: checking-levels-order#| results: holdtbl11.4<- base::readRDS("data/chap11/tbl11.4.rds")glue::glue("##########################################################################")glue::glue("base::levels() does not reveal if theres is an order in the factor levels")base::levels(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::levels(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("If you display a value of an ordered factor, it reveals the order with '<'")head(tbl11.4$satis_advance, 1)glue::glue(" ")glue::glue("To prevent showing one value one can use forcats::fct_unique()")forcats::fct_unique(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")head(tbl11.4$sex, 1)glue::glue("How to check if a factor has ordered levels, but not the order itself?")glue::glue(" ")glue::glue("##########################################################################")glue::glue("utils::str()")utils::str(tbl11.4)glue::glue(" ")glue::glue("##########################################################################")glue::glue("base::class()")base::class(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::class(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("base::is.ordered()")base::is.ordered(tbl11.4$satis_advance)glue::glue("--------------------------------------------------------------------------")base::is.ordered(tbl11.4$sex)glue::glue(" ")glue::glue("##########################################################################")glue::glue("skimr::skim()) has a column 'ordered' about the status of the factor variable")tbl11_temp <- tbl11.4|> dplyr::select(satis_advance, sex)skimr::skim(tbl11_temp)```Several options to check the order of factor levels::::::::::::::::::::::::::::::### Examine satisfaction by job type for females:::::{.my-example}:::{.my-example-header}:::::: {#exm-chap11-satisfaction-jobtype}: Examine satisfaction by job type for females with the Kruskal-Wallis test:::::::::::::{.my-example-container}::: {.panel-tabset}###### salary:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-kruskal-wallis}: Examine salary satisfaction by job type for females with the `r glossary("Kruskal-Wallis")` test:::::::::::::{.my-r-code-container}::: {#lst-chap11-kruskal-wallis}```{r}#| label: kruskal-wallis# examine salary satisfaction by job type for femalessat_salary_kw <- stats::kruskal.test(formula =as.integer(x = satis_salary) ~ job_cat,data = tbl11.4 )sat_salary_kw#examine salary satisfaction by agesat_salary_rho <-cor.test(formula =~as.integer(x = satis_salary) + age,method ="spearman",data = tbl11.4)sat_salary_rho```Salary satisfaction by job type for females:::***I got a warning, that the test cannot compute exact p-values with ties. I didn't see this warning in the book example.Remember that I got different figures after the sampling procedure, but all in all the results are the sames: **The satisfaction with salary was significantly associated with job type but not with age.**::: {.callout #rep-chap11-salary-satisfaction-jobtype}##### Salary satisfaction by job type for femalesThe satisfaction with salary was significantly associated with job type but not with age. Specifically, there was a statistically significant relationship between job type and satisfaction with salary $\chi^2_{KW}(2)21.46, p< 0.01$. In addition, there was a non-significant and weak positive correlation between age and salary satisfaction (rs = 0.07; p = 0.025).::::::::::::###### society contribution:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-satisfaction-contribution}: Examine society contribution satisfaction by job type for females with the `r glossary("Kruskal-Wallis")` test:::::::::::::{.my-r-code-container}::: {#lst-chap11-satisfaction-contribution} ```{r}#| label: satisfaction-contribution# examine society contribution satisfaction by job type for femalessat_contrib_kw <- stats::kruskal.test(formula =as.integer(x = satis_contrib) ~ job_cat,data = tbl11.4 )sat_contrib_kw#examine society contribution satisfaction by agesat_contrib_rho <-cor.test(formula =~as.integer(x = satis_contrib) + age,method ="spearman",data = tbl11.4)sat_contrib_rho```Society contribution satisfaction by job type for females:::::: {.callout #rep-chap11-salary-satisfaction-jobtype}##### Society contribution satisfaction by job type for femalesThe satisfaction with society contribution was significantly associated with job type and also with age. Specifically, there was a statistically significant relationship between job type and satisfaction with society contribution $\chi^2_{KW}(2)10.52, p< 0.01$. In addition, there was also a significant and a weak positive correlation between age and society contribution satisfaction (rs = 0.12; p < .001).::::::::::::::::::::::::## Avchievement 5: Estimating an ordinal logistic regression model {#sec-chap11-achievement5}For ordinal categorical variables, a model is needed that can account for the order of the outcome variable.### NHST Step 1Write the null and alternate hypotheses:::: {.callout-note}- **H0**: Job type and age are not helpful in explaining satisfaction with salary for female college graduates.- **HA**: Job type and age are helpful in explaining satisfaction with salary for female college graduates.:::### NHST Step 2Compute the test statistic. The ordinal regression model is estimated using the `polr()` function from the {**MASS**} package (see: @sec-MASS).:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-statistics-ordinal-regression}: Compute the statistics for the ordinal logistic regression model:::::::::::::{.my-r-code-container}::: {#lst-chap11-statistics-ordinal-regression}```{r}#| label: statistics-ordinal-regression# ordinal logistic regression for salary satisfaction# model salary satisfaction based on job type and ageolm11.1<- MASS::polr(formula = satis_salary ~ job_cat + age,data = tbl11.4)save_data_file("chap11", olm11.1, "olm11.1.rds")summary(object = olm11.1)# estimate null modelolm11.0<- MASS::polr(formula = satis_salary ~1,data = tbl11.4)# job model chi-squaredsalary_chisq <- olm11.0$deviance - olm11.1$deviance# degrees of freedom for chi-squaredsalary_df <- base::length(x = olm11.1$coefficients) - base::length(x = olm11.0$coefficients)# pvalue for chi-squaredsalary_p <- stats::pchisq(q = salary_chisq, df = salary_df, lower.tail =FALSE )# put together and printmodelsig_salary <- base::round(x =c(salary_chisq, salary_df, salary_p), 3)base::names(x = modelsig_salary) <-c("Chi-squared", "d.f.", "p")modelsig_salary```Computing the ordinal logistic regression model:::***Similar to the multinomial model, the model summary includes the residual deviance but not the null deviance to compute the model `r glossary("chi-squared")`. Following the strategy used for the multinomial model, we had to compute the null deviance by estimating a model with no predictors and computing the chi-squared using the deviance values from the two models.:::::::::The model chi-squared is 26.79 with 3 degrees of freedom.### NHST Step 3Review and interpret the test statistics: Calculate the probability that your test statistic is at least as big as it is if there is no relationship (i.e., the null is true).The p-value for $χ^2(3) = 26.79$ is less than .001.### NHST Step 4Conclude and write report.We reject the null hypothesis. Job type and age statistically significantly help to predict satisfaction with salary for female college graduates [$χ2(3) = 26.79; p < .001$].### Ordinal logistic regression model fit:::::{.my-example}:::{.my-example-header}:::::: {#exm-ID-text}: Numbered Example Title:::::::::::::{.my-example-container}::: {.panel-tabset}###### fit model:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-olm-model-fit}: Ordinal logistic regression model fit:::::::::::::{.my-r-code-container}::: {#lst-chap11-olm-model-fit}```{r}#| label: olm-model-fit# observed vs. predicted category for each observationfit_salary_abs <-table(observed = olm11.1$model$satis_salary,predicted = stats::predict(object = olm11.1) )fit_salary_abs# observed vs. predicted category for each observationfit_salary_perc <-prop.table(x =table(observed = olm11.1$model$satis_salary,predicted =predict(object = olm11.1) ),margin =1 )fit_salary_perc```Ordinal logistic regression model fit:::***::: {.callout-warning #wrn-chap11-wrong-predict-calculation}##### Predicted values wrong!With the exception of two values all predicted values are "Somewhat satisfied". That seems strange! But the result is that the model predicted 455 (45,5%) of the observations in contrast to 267 (26.7%). That is much better than the figures from the book.But I still think that there may be something wrong in my computation.::::::::::::###### odds & confint:::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-odds-ratio-confint}: Compute odds ratios and confidence intervals:::::::::::::{.my-r-code-container}::: {#lst-chap11-odds-ratio-confint} ```{r}#| label: odds-ratio-confint# odds ratios and confidence intervalsor_sal <-data.frame(OR =exp(x = olm11.1$coefficients),CI =exp(x =confint(object = olm11.1)))or_sal```Odds ratios and confidence intervals:::***Besides that I get different numbers because of different case distribution from the sampling procedures, the values here are --- in contrast to the predict values --- plausible.For ordinal models, the odds ratios are called `r glossary("proportional-odds-ratios", "proportional odds ratios")` and are the increases or decreases in odds of being in a higher group or groups versus all the lower groups for each one-unit increase in the predictor. As an example follows the other sciences predictor: - Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very satisfied compared to the other satisfaction categories (OR = 0.48; 95% CI: 0.35–0.65). - Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very or somewhat satisfied compared to the other satisfaction categories (OR = 0.48; 95% CI: 0.35–0.65). - Compared to females with computer science, math, or engineering jobs, females with non-science jobs have 52% lower odds of being very or somewhat satisfied or somewhat dissatisfied compared to very dissatisfied (OR = 0.48; 95% CI: 0.35–0.65).:::::::::::::::::::::## Achievement 6: Checking assumptions {#sec-chap11-achievement6}Besides the assumption of independent observations that was already several times met, the proportional odds is another assumption for ordered logistic regression models.The proportional odds assumption requires that the odds for every shift from category to category of the outcome are the same for each level of the predictors. For example, say the odds of someone being in the very dissatisfied group compared to the somewhat dissatisfied group were 2.5 times higher in the non-science group compared to the computer science, math, or engineering group. The proportional odds assumption would require that the odds of someone being in the somewhat dissatisfied group compared to the somewhat satisfied group would also need to be 2.5 times higher in the non-science compared to computer science, math, and engineering group.In the {**ordinal**} package, the `nominal_test()` function tests the proportional odds assumption. The null hypothesis for this is that the proportional odds assumption is met; the alternate hypothesis is that the proportional odds assumption is not met. The assumption is checked for each predictor in the model. Unfortunately, `nominal_test()` does not like `polr` objects, so the model has to be re-estimated using `clm()` from the ordinal package. :::::{.my-r-code}:::{.my-r-code-header}:::::: {#cnj-chap11-proportional-odds-test}: Checking proportional odds assumption for an ordered logistic regression model:::::::::::::{.my-r-code-container}::: {#lst-chap11-proportional-odds-test}```{r}#| label: proportional-odds-test# check proportional odds assumptionordinal::nominal_test(object = ordinal::clm(formula = satis_salary ~ job_cat + age,data = tbl11.4 ) )```Test proportional odds assumption with `ordinal::nominal_test()`:::***The p-values are .16 and .93, so the null hypothesis is retained for the job type predictor and for the age predictor. The proportional odds assumption is met for this model.:::::::::### Summary::: {.callout #rep-chap11-olm11.1-report}An ordinal logistic regression using job type and age was better at predicting satisfaction with salary among female college graduates than a baseline model including no predictors [χ2(3) = 28.89; p < .001]. - The model met its assumptions and correctly predicted 455 of the 1,000 (45,5%) observations.- Female college graduates in non-science careers have 49% lower odds than those in computer science, math, or engineering of being very satisfied with their salary compared to being in another satisfaction group. - Likewise, female college graduates in other sciences had 52% lower odds than those in computer science, math, or engineering of being very satisfied with their salary compared to being in another satisfaction group. - There was no significant relationship between age and salary satisfaction.:::## Exercises (empty)## Glossary```{r}#| label: glossary-table#| echo: falseglossary_table()```------------------------------------------------------------------------## Session Info {.unnumbered}::: my-r-code::: my-r-code-headerSession Info:::::: my-r-code-container```{r}#| label: session-infosessioninfo::session_info()```::::::