4.7 Deviance and model fit
The deviance is a key concept in logistic regression. Intuitively, it measures the deviance of the fitted logistic model with respect to a perfect model for \(\mathbb{P}[Y=1|X_1=x_1,\ldots,X_k=x_k]\). This perfect model, known as the saturated model, denotes an abstract model that fits perfectly the sample, this is, the model such that \[ \hat{\mathbb{P}}[Y=1|X_1=X_{i1},\ldots,X_k=X_{ik}]=Y_i,\quad i=1,\ldots,n. \] This model assigns probability \(0\) or \(1\) to \(Y\) depending on the actual value of \(Y_i\). To clarify this concept, Figure 4.10 shows a saturated model and a fitted logistic regression.
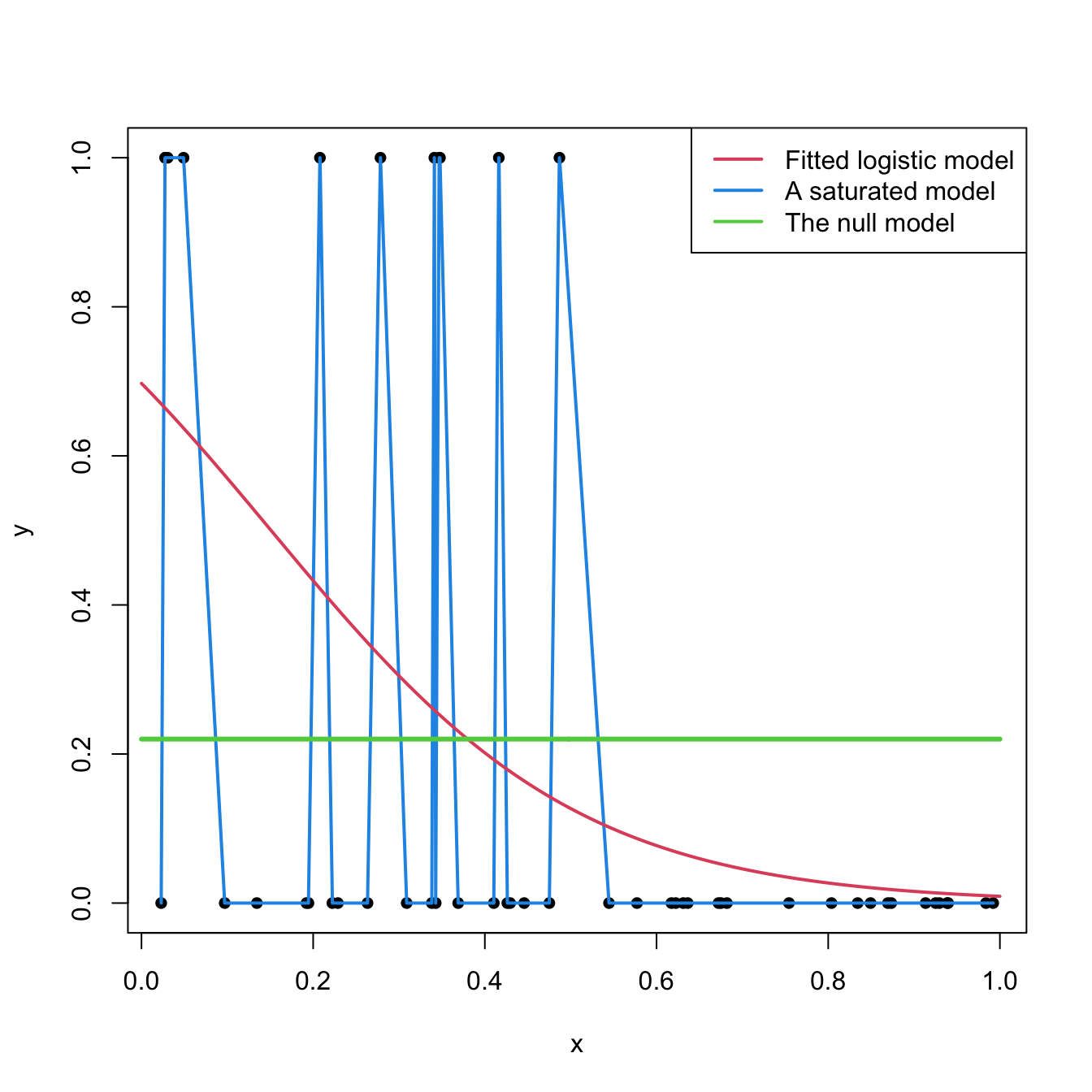
Figure 4.10: Fitted logistic regression versus a saturated model (several are possible depending on the interpolation between points) and the null model.
More precisely, the deviance is defined as the difference of likelihoods between the fitted model and the saturated model: \[ D=-2\log\text{lik}(\hat{\boldsymbol{\beta}})+2\log\text{lik}(\text{saturated model}). \] Since the likelihood of the saturated model is exactly one31, then the deviance is simply another expression of the likelihood: \[ D=-2\log\text{lik}(\hat{\boldsymbol{\beta}}). \] As a consequence, the deviance is always larger or equal than zero, being zero only if the fit is perfect.
A benchmark for evaluating the magnitude of the deviance is the null deviance, \[ D_0=-2\log\text{lik}(\hat{\beta}_0), \] which is the deviance of the worst model, the one fitted without any predictor, to the perfect model: \[ Y|(X_1=x_1,\ldots,X_k=x_k)\sim \mathrm{Ber}(\mathrm{logistic}(\beta_0)). \] In this case, \(\hat\beta_0=\mathrm{logit}(\frac{m}{n})=\log\frac{\frac{m}{n}}{1-\frac{m}{n}}\) where \(m\) is the number of \(1\)’s in \(Y_1,\ldots,Y_n\) (see Figure 4.10).
The null deviance serves for comparing how much the model has improved by adding the predictors \(X_1,\ldots,X_k\). This can be done by means of the \(R^2\) statistic, which is a generalization of the determination coefficient in multiple linear regression: \[\begin{align} R^2=1-\frac{D}{D_0}=1-\frac{\text{deviance(fitted logistic, saturated model)}}{\text{deviance(null model, saturated model)}}.\tag{4.14} \end{align}\] This global measure of fit shares some important properties with the determination coefficient in linear regression:
- It is a quantity between \(0\) and \(1\).
- If the fit is perfect, then \(D=0\) and \(R^2=1\). If the predictors do not add anything to the regression, then \(D=D_0\) and \(R^2=0\).
In logistic regression, \(R^2\) does not have the same interpretation as in linear regression:
- Is not the percentage of variance explained by the logistic model, but rather a ratio indicating how close is the fit to being perfect or the worst.
- It is not related to any correlation coefficient.
Let’s see how these concepts are given by the summary function:
# Summary of model
nasa <- glm(fail.field ~ temp, family = "binomial", data = challenger)
summaryLog <- summary(nasa)
summaryLog # 'Residual deviance' is the deviance; 'Null deviance' is the null deviance
##
## Call:
## glm(formula = fail.field ~ temp, family = "binomial", data = challenger)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -1.0566 -0.7575 -0.3818 0.4571 2.2195
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 7.5837 3.9146 1.937 0.0527 .
## temp -0.4166 0.1940 -2.147 0.0318 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 28.267 on 22 degrees of freedom
## Residual deviance: 20.335 on 21 degrees of freedom
## AIC: 24.335
##
## Number of Fisher Scoring iterations: 5
# Null model - only intercept
null <- glm(fail.field ~ 1, family = "binomial", data = challenger)
summaryNull <- summary(null)
summaryNull
##
## Call:
## glm(formula = fail.field ~ 1, family = "binomial", data = challenger)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -0.852 -0.852 -0.852 1.542 1.542
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -0.8267 0.4532 -1.824 0.0681 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 28.267 on 22 degrees of freedom
## Residual deviance: 28.267 on 22 degrees of freedom
## AIC: 30.267
##
## Number of Fisher Scoring iterations: 4
# Computation of the R^2 with a function - useful for repetitive computations
r2Log <- function(model) {
summaryLog <- summary(model)
1 - summaryLog$deviance / summaryLog$null.deviance
}
# R^2
r2Log(nasa)
## [1] 0.280619
r2Log(null)
## [1] -4.440892e-16Another way of evaluating the model fit is its predictive accuracy. The motivation is that most of the times we are interested simply in classifying, for an observation of the predictors, the value of \(Y\) as either \(0\) or \(1\), but not in predicting the value of \(p(x_1,\ldots,x_k)=\mathbb{P}[Y=1|X_1=x_1,\ldots,X_k=x_k]\). The classification in prediction is simply done by the rule \[ \hat{Y}=\left\{\begin{array}{ll} 1,&\hat{p}(x_1,\ldots,x_k)>\frac{1}{2},\\ 0,&\hat{p}(x_1,\ldots,x_k)<\frac{1}{2}. \end{array}\right. \] The overall predictive accuracy can be summarized with the hit matrix
| Reality vs. classified | \(\hat Y=0\) | \(\hat Y=1\) |
|---|---|---|
| \(Y=0\) | Correct\(_{0}\) | Incorrect\(_{01}\) |
| \(Y=1\) | Incorrect\(_{10}\) | Correct\(_{1}\) |
and with the hit ratio \(\frac{\text{Correct}_0+\text{Correct}_1}{n}\). The hit matrix is easily computed with the table function. The function, whenever called with two vectors, computes the cross-table between the two vectors.
# Fitted probabilities for Y = 1
nasa$fitted.values
## 1 2 3 4 5 6 7
## 0.42778935 0.23014393 0.26910358 0.32099837 0.37772880 0.15898364 0.12833090
## 8 9 10 11 12 13 14
## 0.23014393 0.85721594 0.60286639 0.23014393 0.04383877 0.37772880 0.93755439
## 15 16 17 18 19 20 21
## 0.37772880 0.08516844 0.23014393 0.02299887 0.07027765 0.03589053 0.08516844
## 22 23
## 0.07027765 0.82977495
# Classified Y's
yHat <- nasa$fitted.values > 0.5
# Hit matrix:
# - 16 correctly classified as 0
# - 4 correctly classified as 1
# - 3 incorrectly classified as 0
tab <- table(challenger$fail.field, yHat)
tab
## yHat
## FALSE TRUE
## 0 16 0
## 1 3 4
# Hit ratio (ratio of correct classification)
(16 + 4) / 23 # Manually
## [1] 0.8695652
sum(diag(tab)) / sum(tab) # Automatically
## [1] 0.8695652It is important to recall that the hit matrix will be always biased towards unrealistic good classification rates if it is computed in the same sample used for fitting the logistic model. A familiar analogy is asking to your mother (data) whether you (model) are a good-looking human being (good predictive accuracy) – the answer will be highly positively biased. To get a fair hit matrix, the right approach is to split randomly the sample into two: a training dataset, used for fitting the model, and a test dataset, used for evaluating the predictive accuracy.