Capítulo 3 Importando dados para o R
O primeiro passo para importarmos um arquivo para o R é fazer com que o mesmo “enxergue” a sua pasta de trabalho.
Como perguntar qual a pasta que o R está “enxergando” no momento?
#Descobrindo qual o diretório de trabalho que o R está "enxergando" no momento
getwd()Caso não seja a pasta onde localiza-se o seu arquivo, podemos mudar essa pasta com a função setwd.
#Modificando o diretório de trabalho que o R está "enxergando" neste momento
setwd("PASSAR AQUI O CAMINHO DA SUA PASTA SEMPRE ENTRE ASPAS")O caminho deve estar SEMPRE entre aspas e as barras devem ser invertidas (caso deseje usar a barra sem ser invertida é preciso duplicá-las).
Uma outra forma de modificarmos o diretório de trabalho é acessarmos o menu Session → Set Working Directory → Choose Directory.
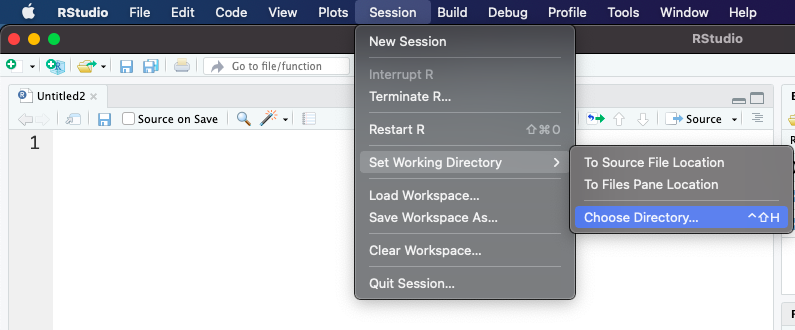
Esse problema de mudanças de diretórios de trabalho serão pequenos, uma vez que adotaremos a prática de criação de projetos.
A seguir serão apresentados alguns pacotes para a importação de dados para o R.
3.1 Pacote readr

Um pacote cujo objetivo é propiciar de modo rápido e amigável a importação de dados retangulares (como .txt, .csv, .tsv, .fwd).
As principais funções deste pacote para importação de dados são:
read_table- importa arquivos em que as colunas são separadas por um ou mais espaços em branco.read_csv- importa aquivos delimitados por vírgula.read_csv2- importa arquivos separados por semicolunas (comum em países que usam a “,” como separador decimal)read_tsv- importa arquivos separados por tabs.read_delim-read_csveread_tsvsão casos particulares desta função. Ela te permite mais flexibilidade na importação de arquivos.
3.1.1 Importando arquivos .txt
Vamos usar a função read_delim para importarmos arquivos com extensão .txt. Os principais argumentos da função são:
file- o arquivo a ser importado;delim- o caracter usado para separar as variáveis;col_names- um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);na- qual a codificação usada para dado faltante (default = NA);skip- número de linhas a serem puladas no momento da importação (default = 0);locale- controla vários aspectos como decimal, enconding, entre outros.
Crie um projeto chamado Analise Seguro! Crie um script no projeto com o nome Script Analise.
Após especificarmos a pasta de trabalho, precisamos ativar o pacote readr e utilizarmos a função read_delim como a seguir.
#Ativando o pacote readr
library(readr)
#Importando o arquivo seguro saude.txt
base = read_delim(file = "seguro saude.txt")## Rows: 1338 Columns: 7
## ── Column specification ───────────────────────────────────
## Delimiter: " "
## chr (1): fumante
## dbl (4): idade, sexo, num_dep, regiao
## num (2): imc, cobrancas
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base## # A tibble: 1,338 × 7
## idade sexo imc num_dep fumante regiao cobrancas
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 19 1 99999 0 Sim 4 16884924
## 2 18 2 3377 1 Não 3 17255523
## 3 28 2 33 3 Não 3 4449462
## 4 33 2 22705 0 Não 2 2198447061
## 5 32 2 2888 0 Não 2 38668552
## 6 31 1 2574 0 Não 3 37566216
## 7 46 1 3344 1 Não 3 82405896
## 8 37 1 2774 3 Não 2 72815056
## 9 37 2 2983 2 Não 1 64064107
## 10 60 1 2584 0 Não 2 2892313692
## # … with 1,328 more rowsAo usarmos as funções do pacote readr para importarmos um arquivo, a primeira coisa que percebemos é que são apresentadas a forma como cada variável foi coletada. Ao pedirmos para visualizarmos o objeto, percebemos que sua classe é um tibble.
A importação foi realizada de maneira correta?
Avaliem a variável imc e cobrancas no arquivo original. O que tem de diferente dos valores apresentados na tela do R?
Claramente o arquivo acima apresenta problemas na importação, pois o indivíduo 1 apresenta IMC de 99999 e o indivíduo 2 de 3377.
Precisamos alimentar a função com toda informação necesária para que ela faça a importação de forma adequada. O arquivo possui as seguintes características:
- possui extensão .txt,
- 99999 foi usado como código para dado faltante,
- , é o indicador de decimal.
#Importando o arquivo seguro saude.txt
base = read_delim(file = "seguro saude.txt", #nome do arquivo com extensão entre aspas
na = "99999", #código usado para indicar dado faltante
locale = locale(decimal_mark = ",")) #função que controla aspectos do arquivo como o decimal## Rows: 1338 Columns: 7
## ── Column specification ───────────────────────────────────
## Delimiter: " "
## chr (1): fumante
## dbl (6): idade, sexo, imc, num_dep, regiao, cobrancas
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base## # A tibble: 1,338 × 7
## idade sexo imc num_dep fumante regiao cobrancas
## <dbl> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 19 1 NA 0 Sim 4 16885.
## 2 18 2 33.8 1 Não 3 1726.
## 3 28 2 33 3 Não 3 4449.
## 4 33 2 22.7 0 Não 2 21984.
## 5 32 2 28.9 0 Não 2 3867.
## 6 31 1 25.7 0 Não 3 3757.
## 7 46 1 33.4 1 Não 3 8241.
## 8 37 1 27.7 3 Não 2 7282.
## 9 37 2 29.8 2 Não 1 6406.
## 10 60 1 25.8 0 Não 2 28923.
## # … with 1,328 more rows#Obtendo medidas descritivas de todas as variáveis
summary(base)## idade sexo imc num_dep
## Min. :18.00 Min. :1.000 Min. :15.96 Min. :0.000
## 1st Qu.:27.00 1st Qu.:1.000 1st Qu.:26.29 1st Qu.:0.000
## Median :39.00 Median :2.000 Median :30.40 Median :1.000
## Mean :39.22 Mean :1.505 Mean :30.67 Mean :1.095
## 3rd Qu.:51.00 3rd Qu.:2.000 3rd Qu.:34.70 3rd Qu.:2.000
## Max. :64.00 Max. :2.000 Max. :53.13 Max. :5.000
## NA's :1 NA's :1 NA's :2
## fumante regiao cobrancas
## Length:1338 Min. :1.000 Min. : 1122
## Class :character 1st Qu.:2.000 1st Qu.: 4738
## Mode :character Median :3.000 Median : 9378
## Mean :2.518 Mean :13268
## 3rd Qu.:3.000 3rd Qu.:16658
## Max. :4.000 Max. :63770
## NA's :13 NA's :1- Qual o problema das medidas resumos apresentadas acima?
- Avalie o arquivo Dicionário da base de dados.
- Percebemos que o r está tratando várias variáveis que são qualitativas como variáveis numéricas, pois tem calculado medidas resumos como média e quartis.
- É preciso trasformar as variáveis em fatores, vamos fazer esta transformação seguindo o dicionário, como indicado abaixo.
#Transformando a variável sexo em factor
base$sexo = factor(x = base$sexo, #vetor com os valores a serem rotulados
levels = c(1,2), #os valores distintos que aparecem
labels = c("Mulher", "Homem")) #os rótulos dos valores
#Transformando a variável fumante em factor
base$fumante = factor(x = base$fumante)
#Transformando a variável regiao em factor
base$regiao = factor(x = base$regiao,
levels = c(1,2,3,4),
labels = c("Nordeste", "Noroeste", "Sudeste", "Sudoeste"))
#Visualizando o objeto
base## # A tibble: 1,338 × 7
## idade sexo imc num_dep fumante regiao cobrancas
## <dbl> <fct> <dbl> <dbl> <fct> <fct> <dbl>
## 1 19 Mulher NA 0 Sim Sudoeste 16885.
## 2 18 Homem 33.8 1 Não Sudeste 1726.
## 3 28 Homem 33 3 Não Sudeste 4449.
## 4 33 Homem 22.7 0 Não Noroeste 21984.
## 5 32 Homem 28.9 0 Não Noroeste 3867.
## 6 31 Mulher 25.7 0 Não Sudeste 3757.
## 7 46 Mulher 33.4 1 Não Sudeste 8241.
## 8 37 Mulher 27.7 3 Não Noroeste 7282.
## 9 37 Homem 29.8 2 Não Nordeste 6406.
## 10 60 Mulher 25.8 0 Não Noroeste 28923.
## # … with 1,328 more rows#Obtendo medidas descritivas de todas as variáveis
summary(base)## idade sexo imc num_dep fumante
## Min. :18.00 Mulher:662 Min. :15.96 Min. :0.000 Não:1064
## 1st Qu.:27.00 Homem :675 1st Qu.:26.29 1st Qu.:0.000 Sim: 274
## Median :39.00 NA's : 1 Median :30.40 Median :1.000
## Mean :39.22 Mean :30.67 Mean :1.095
## 3rd Qu.:51.00 3rd Qu.:34.70 3rd Qu.:2.000
## Max. :64.00 Max. :53.13 Max. :5.000
## NA's :1 NA's :2
## regiao cobrancas
## Nordeste:319 Min. : 1122
## Noroeste:322 1st Qu.: 4738
## Sudeste :362 Median : 9378
## Sudoeste:322 Mean :13268
## NA's : 13 3rd Qu.:16658
## Max. :63770
## NA's :13.1.2 Importando arquivos .csv
Se o nosso interesse é importar arquivos com extensão .csv, podemos usar a função read_delim, mas existem opções melhores, pois não nos preocuparemos em definir o delimitador.
As funções read_csv e read_csv2 leem dados em arquivos .csv.
CSV (comma separeted values)
Principais argumentos da função read_csv2:
file- o arquivo a ser importado;col_names- um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);na- qual a codificação usada para dado faltante (default =c(““, NA));skip- número de linhas a serem puladas no momento da importação (default = 0);locale- controla vários aspectos como decimal, enconding, entre outros.
Vamos importar a base PNUD.csv que contém variáveis como idh, indíce de gini e tamanho da população, entre outras, para três períodos distintos (1991, 2000 e 2010) dos municípios brasileiros.
#Importando o arquivo PNUD.csv
basePNUD = read_csv(file = "PNUD.csv")## Rows: 16694 Columns: 14
## ── Column specification ───────────────────────────────────
## Delimiter: ","
## chr (3): muni, uf, regiao
## dbl (11): ano, idhm, idhm_e, idhm_l, idhm_r, espvida, rdpc, gini, pop, lat, lon
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
basePNUD## # A tibble: 16,694 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
## 2 1991 ARIQ… RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018
## 3 1991 CABI… RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
## 4 1991 CACO… RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
## 5 1991 CERE… RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
## 6 1991 COLO… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
## 7 1991 CORU… RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737
## 8 1991 COST… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902
## 9 1991 ESPI… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505
## 10 1991 GUAJ… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240
## # … with 16,684 more rows, and 2 more variables: lat <dbl>, lon <dbl>As diferenças entre as duas funções para importação de arquivos .csv são o separador e o decimal. Quando forem importar um arquivo de extensão .csv, testem uma das funções e caso a exportação não esteja ocorrendo de forma correta, tente a outra função.
3.2 Pacote readxl

O pacote readxl fornece diversas funções, dentre elas a função read_excel que importa dados em arquivos .xls e .xlsx.
Os principais argumentos da função read_excel:
path- o arquivo a ser importado;sheet- a planilha a ser importada;col_names- um argumento lógico indicando se o arquivo possui ou não os nomes das variáveis (default = TRUE);skip- número de linhas a serem puladas no momento da importação (default = 0);na- qual a codificação usada para dado faltante (default = NA).
# Carregando o pacote readxl
library(readxl)
#Importando o arquivo PNUD ano.xlsx
basePNUD2000 = read_excel(path = "PNUD ano.xlsx", #nome do arquivo com extensão entre aspas
sheet = "2000") #nome ou posição da planilha no arquivo#Visualizando o objeto
basePNUD2000## # A tibble: 5,562 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
## <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 2000 ALTA… RO Norte 0.483 0.262 0.698 0.617 66.9 371.… 0.58 24888
## 2 2000 ARIQ… RO Norte 0.556 0.343 0.742 0.674 69.52 530.… 0.59 69829
## 3 2000 CABI… RO Norte 0.488 0.284 0.677 0.604 65.62 342.… 0.58 7076
## 4 2000 CACO… RO Norte 0.567 0.377 0.745 0.65 69.7 456.… 0.55 71703
## 5 2000 CERE… RO Norte 0.542 0.338 0.704 0.668 67.22 511.… 0.69 17283
## 6 2000 COLO… RO Norte 0.545 0.362 0.71 0.629 67.61 401.… 0.57 21014
## 7 2000 CORU… RO Norte 0.401 0.185 0.649 0.539 63.94 229 0.55 9401
## 8 2000 COST… RO Norte 0.486 0.295 0.65 0.598 64.01 331.… 0.58 8816
## 9 2000 ESPI… RO Norte 0.501 0.276 0.71 0.64 67.61 429.… 0.63 23970
## 10 2000 GUAJ… RO Norte 0.573 0.398 0.742 0.638 69.52 422.… 0.6 35373
## # … with 5,552 more rows, and 2 more variables: lat <chr>, lon <chr>3.3 Pacote haven

É possível ler dados diretamente de outros formatos que não seja texto (ASCII). Isto em geral é mais eficiente e requer menos memória do que converter para formato texto. Há funções para importar dados diretamente do SAS, SPSS e Stata.
A seguir serão listadas algumas destas funções
read_savpara arquivos do SPSS;read_statapara arquivos do Stata;read_saspara arquivos do SAS;
A seguir vamos importar o arquivo survey.sav.
# Carregando o pacote haven
library(haven)
#Importando o arquivo survey.sav
basespss = read_spss(file = "survey.sav")#Visualizando o objeto
basespss## # A tibble: 439 × 134
## id sex age marital child educ source smoke smoke…¹ op1
## <dbl> <dbl+lbl> <dbl> <dbl+l> <dbl+l> <dbl+l> <dbl+lb> <dbl+l> <dbl> <dbl>
## 1 415 2 [FEMALE… 24 4 [MAR… 1 [YES] 5 [COM… 7 [LIF… 2 [NO] NA 3
## 2 9 1 [MALES] 39 3 [LIV… 1 [YES] 5 [COM… 1 [WOR… 1 [YES] 2 2
## 3 425 2 [FEMALE… 48 4 [MAR… 1 [YES] 2 [SOM… 4 [CHI… 2 [NO] NA 3
## 4 307 1 [MALES] 41 5 [REM… 1 [YES] 2 [SOM… 1 [WOR… 2 [NO] 0 3
## 5 440 1 [MALES] 23 1 [SIN… 2 [NO] 5 [COM… 1 [WOR… 2 [NO] 0 3
## 6 484 2 [FEMALE… 31 4 [MAR… 1 [YES] 5 [COM… 7 [LIF… 2 [NO] NA 2
## 7 341 2 [FEMALE… 30 6 [SEP… 2 [NO] 4 [SOM… 8 [MON… 2 [NO] 0 3
## 8 300 1 [MALES] 23 2 [STE… 2 [NO] 5 [COM… 1 [WOR… 1 [YES] 100 4
## 9 61 2 [FEMALE… 18 2 [STE… 2 [NO] 2 [SOM… 2 [SPO… 1 [YES] 40 3
## 10 24 1 [MALES] 23 1 [SIN… 2 [NO] 6 [POS… NA 2 [NO] 0 1
## # … with 429 more rows, 124 more variables: op2 <dbl>, op3 <dbl>, op4 <dbl>,
## # op5 <dbl>, op6 <dbl>, mast1 <dbl>, mast2 <dbl>, mast3 <dbl>, mast4 <dbl>,
## # mast5 <dbl>, mast6 <dbl>, mast7 <dbl>, pn1 <dbl>, pn2 <dbl>, pn3 <dbl>,
## # pn4 <dbl>, pn5 <dbl>, pn6 <dbl>, pn7 <dbl>, pn8 <dbl>, pn9 <dbl>,
## # pn10 <dbl>, pn11 <dbl>, pn12 <dbl>, pn13 <dbl>, pn14 <dbl>, pn15 <dbl>,
## # pn16 <dbl>, pn17 <dbl>, pn18 <dbl>, pn19 <dbl>, pn20 <dbl>, lifsat1 <dbl>,
## # lifsat2 <dbl>, lifsat3 <dbl>, lifsat4 <dbl>, lifsat5 <dbl>, pss1 <dbl>, …A seguir vamos importar o arquivo salary.sas7bdat.
#Importando o arquivo salary.sas7bdat
basesas = read_sas(data_file = "salary.sas7bdat")#Visualizando o objeto
basesas## # A tibble: 93 × 4
## E T X Y
## <dbl> <dbl> <dbl> <dbl>
## 1 0 1 12 3900
## 2 44 7 10 4020
## 3 5 30 12 4290
## 4 6.20 7 8 4380
## 5 7.5 6 8 4380
## 6 0 7 12 4380
## 7 0 10 12 4380
## 8 4.5 6 12 4380
## 9 75 2 15 4440
## 10 52 3 8 4500
## # … with 83 more rows3.4 Exportando dados no R
Após realizarmos as modificações desejadas na base de dados, podemos salvar a mesma no disco rígido do computador. A escolha da função está atrelada a extensão com a qual queremos salvar o arquivo.
Principais argumentos da família de funções write_:
x- o arquivo a ser exportado;file- nome com o qual o arquivo será salvo (não esquecer a extensão .xxx);
#Exportando o arquivo em .csv
write_excel_csv2(x = base, #objeto que você deseja exportar
file = "Base seguro modificada.csv") #nome do arquivo com extensão entre aspas
#Exportando o arquivo em .txt
write_delim(x = base,
file = "Base seguro modificada.txt")
#Exportando o arquivo em .sav
write_sav(data = base,
path = "Base seguro modificada.sav")Para exportarmos um arquivo com extensão .xlsx precisaremos do pacote writexl.
#Ativando pacote
library(writexl)
#Exportando o arquivo em .xlsx
write_xlsx(x = base,
path = "Base seguro modificada.xlsx")3.5 Extensão RDS
Ao salvarmos o arquivo como uma extensão .rds, ele cria uma versão serializada do conjunto de dados e, em seguida, salva-o com uma compressão, o que diminui o tamanho e o tempo necessário para a leitura do mesmo.
Principais argumentos da função write_rds:
x- o arquivo a ser exportado;file- nome com o qual o arquivo será salvo (não esquecer a extensão .rds);compress- escolher o tipo de compressão a ser aplicada (default = none);
#Exportando o arquivo em .rds
write_rds(x = base,
file = "Base seguro modificada.rds",
compress = "gz")#Importando um arquivo .rds
baserds = read_rds(file = "Base seguro modificada.rds")#Visualizando o objeto
baserds## # A tibble: 1,338 × 7
## idade sexo imc num_dep fumante regiao cobrancas
## <dbl> <fct> <dbl> <dbl> <fct> <fct> <dbl>
## 1 19 Mulher NA 0 Sim Sudoeste 16885.
## 2 18 Homem 33.8 1 Não Sudeste 1726.
## 3 28 Homem 33 3 Não Sudeste 4449.
## 4 33 Homem 22.7 0 Não Noroeste 21984.
## 5 32 Homem 28.9 0 Não Noroeste 3867.
## 6 31 Mulher 25.7 0 Não Sudeste 3757.
## 7 46 Mulher 33.4 1 Não Sudeste 8241.
## 8 37 Mulher 27.7 3 Não Noroeste 7282.
## 9 37 Homem 29.8 2 Não Nordeste 6406.
## 10 60 Mulher 25.8 0 Não Noroeste 28923.
## # … with 1,328 more rows3.6 Desafio
- Crie um projeto chamado Spotify.
- Importe o arquivo Spotify files.txt.
- Crie um novo projeto chamado Analise saude.
- Importe o arquivo Base saude.csv.
- Transforme em fatores as variáveis qualitativas de acordo com o dicionário.
- Obtenha medidas descritivas apropriadas para as variáveis da base de saúde.
- Exporte a base de saúde com o menor tamanho possível.