Capítulo 5 Manipulando bases de dados com o dplyr
O pacote dplyr é um dos pacotes mais poderosos e populares do R, desenvolvido por Hadley Wickham.
O dplyr é um poderoso pacote do R para manipular, limpar e resumir dados. Podemos enxergar o pacote como uma gramática de manipulação de dados, fornecendo um conjunto consistente de verbos que ajudam a resolver os desafios mais comuns de manipulação de dados encontrados por um cientista de dados. Ele utiliza C e C++ por trás da maioria das funções, o que geralmente torna o código mais eficiente. Em suma, faz a exploração de dados e manipulação de dados de forma fácil e rápida no R.

As principais funções do dplyr são:
distinct- remove linhas repetidas,rename- renomeia variáveis,select- seleciona colunas,filter- filtra linhas,mutate/transmute- cria/modifica colunas,arrange- ordena a base,group_by- agrupa a base,summarise/summarize- sumariza a base.across- aplica uma mesma operação em diversas colunas da base.
Vamos importar o arquivo PNUD.csv que contém variáveis como idh, indíce de gini e tamanho da população, entre outras, para três períodos distintos (1991, 2000 e 2010) dos municípios brasileiros.
Crie um projeto chamado Dplyr e salve a base em um objeto chamado basePNUD.
#Visualizando o objeto
basePNUD## # A tibble: 16,694 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
## 2 1991 ARIQ… RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018
## 3 1991 CABI… RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
## 4 1991 CACO… RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
## 5 1991 CERE… RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
## 6 1991 COLO… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
## 7 1991 CORU… RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737
## 8 1991 COST… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902
## 9 1991 ESPI… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505
## 10 1991 GUAJ… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240
## # … with 16,684 more rows, and 2 more variables: lat <dbl>, lon <dbl>5.1 Função distinct
Existem linhas duplicadas na base?
Vamos supor, que o conjunto de variáveis existentes no objeto basePNUD identificam de forma única um município em um determinado ano.
#Checando a dimensão de basePNUD
dim(basePNUD)## [1] 16694 14#Ativando o pacote dplyr
library(dplyr)
#Eliminando as linhas repetidas considerando toda a base de dados
basePNUD = basePNUD |>
distinct()
#Checando a dimensão de basePNUD
dim(basePNUD)## [1] 16686 14Vejam que 8 linhas foram removidas do objeto.
Se aplicarmos a função distinct em uma variável específica, ele retorna um tibble que contém todos os valores distintos daquela variável.
#verificando todos os valores distintos da coluna ano
basePNUD |>
distinct(ano)## # A tibble: 3 × 1
## ano
## <dbl>
## 1 1991
## 2 2000
## 3 2010Se aplicarmos a função distinct em mais de uma variável, ela retorna um tibble que contém todas as combinações distintas observadas daquelas variáveis.
#verificando todos os valores distintos da coluna ano
basePNUD |>
distinct(ano,uf)## # A tibble: 81 × 2
## ano uf
## <dbl> <chr>
## 1 1991 RO
## 2 1991 AC
## 3 1991 AM
## 4 1991 RR
## 5 1991 PA
## 6 1991 AP
## 7 1991 TO
## 8 1991 MA
## 9 1991 PI
## 10 1991 CE
## # … with 71 more rows5.2 Função rename
Conseguimos modificar o nome da variável pop para população?
A função rename é usada para renomear nomes de colunas (variáveis).
#renomeando a variável pop por populacao e guardando tudo no objeto basePNUD
basePNUD = basePNUD |>
rename(populacao = pop) #trocando o nome da variável pop por populacao
#visualizando o objeto
basePNUD## # A tibble: 16,686 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA FLORE… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63
## 2 1991 ARIQUEMES RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57
## 3 1991 CABIXI RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7
## 4 1991 CACOAL RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66
## 5 1991 CEREJEIRAS RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6
## 6 1991 COLORADO D… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62
## 7 1991 CORUMBIARA RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59
## 8 1991 COSTA MARQ… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65
## 9 1991 ESPIGÃO D'… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63
## 10 1991 GUAJARÁ-MI… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6
## # … with 16,676 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Percebemos que no objeto basePNUD a coluna que anteriormente estava nomeada como pop, agora está nomeada como populacao.
5.3 Função select
Conseguimos criar uma sub-base que contenha somente as variáveis ano, nome do município e população?
A função select é usada para selecionar determinadas colunas (variáveis) de um objeto.
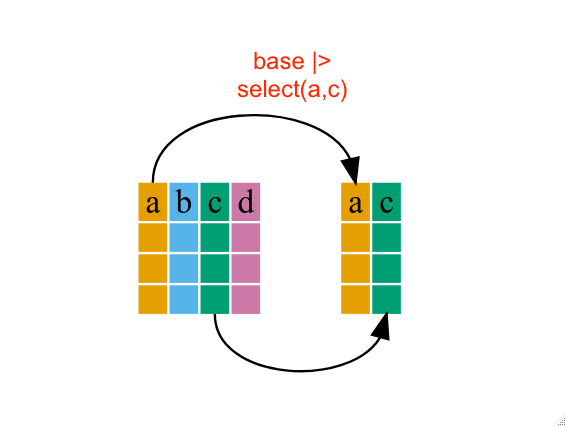
Para selecionarmos somente as variáveis solicitadas acima, basta fazermos o seguinte:
#Selecionando as variáveis ano, nome do município e população e guardando em um objeto chamado sub1
sub1 = basePNUD|>
select(ano, muni, populacao) #selecionando as variáveis ano, muni e populacao
#Visualizando o objeto
sub1## # A tibble: 16,686 × 3
## ano muni populacao
## <dbl> <chr> <dbl>
## 1 1991 ALTA FLORESTA D'OESTE 22835
## 2 1991 ARIQUEMES 55018
## 3 1991 CABIXI 5846
## 4 1991 CACOAL 66534
## 5 1991 CEREJEIRAS 19030
## 6 1991 COLORADO DO OESTE 25070
## 7 1991 CORUMBIARA 10737
## 8 1991 COSTA MARQUES 6902
## 9 1991 ESPIGÃO D'OESTE 22505
## 10 1991 GUAJARÁ-MIRIM 31240
## # … with 16,676 more rowsPercebemos que o objeto sub1 possui a mesma quantidade de linhas que o objeto original basePNUD, mas somente 3 colunas, referentes as variáveis selecionadas.
É possível fazermos seleção de colunas com a função select utilizando:
- os nomes das colunas,
- os índices das colunas,
- intervalos de colunas
- algumas funções como
starts_with,ends_with,contains,matches,one_of,wherepara selecionar um subconjunto de variáveis de forma esperta.
Vejamos algumas aplicações a seguir:
#Selecionando todas as variáveis entre ano e região e a variável rdpc e guardando em um objeto chamado sub2
sub2 = basePNUD |>
select(ano:regiao, rdpc) #selecionando todas as variáveis entre ano e região e a variável rdpc
#Visualizando o objeto
sub2## # A tibble: 16,686 × 5
## ano muni uf regiao rdpc
## <dbl> <chr> <chr> <chr> <dbl>
## 1 1991 ALTA FLORESTA D'OESTE RO Norte 198.
## 2 1991 ARIQUEMES RO Norte 319.
## 3 1991 CABIXI RO Norte 116.
## 4 1991 CACOAL RO Norte 320.
## 5 1991 CEREJEIRAS RO Norte 240.
## 6 1991 COLORADO DO OESTE RO Norte 225.
## 7 1991 CORUMBIARA RO Norte 81.4
## 8 1991 COSTA MARQUES RO Norte 250.
## 9 1991 ESPIGÃO D'OESTE RO Norte 263.
## 10 1991 GUAJARÁ-MIRIM RO Norte 391.
## # … with 16,676 more rows#Selecionando todas as variáveis com excessão de rdpc e regiao e guardando em um objeto chamado sub3
sub3 = basePNUD |>
select(-regiao, -rdpc) #retirando somente as variáveis regiao e rdpc
#Visualizando o objeto
sub3## # A tibble: 16,686 × 12
## ano muni uf idhm idhm_e idhm_l idhm_r espvida gini popul…¹ lat
## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA FLO… RO 0.329 0.112 0.617 0.516 62.0 0.63 22835 -11.9
## 2 1991 ARIQUEMES RO 0.432 0.199 0.684 0.593 66.0 0.57 55018 -9.91
## 3 1991 CABIXI RO 0.309 0.108 0.636 0.43 63.2 0.7 5846 -13.5
## 4 1991 CACOAL RO 0.407 0.171 0.667 0.593 65.0 0.66 66534 -11.4
## 5 1991 CEREJEIR… RO 0.386 0.167 0.629 0.547 62.7 0.6 19030 -13.2
## 6 1991 COLORADO… RO 0.376 0.151 0.658 0.536 64.5 0.62 25070 -13.1
## 7 1991 CORUMBIA… RO 0.203 0.039 0.572 0.373 59.3 0.59 10737 -13.0
## 8 1991 COSTA MA… RO 0.425 0.22 0.629 0.553 62.8 0.65 6902 -12.4
## 9 1991 ESPIGÃO … RO 0.388 0.159 0.653 0.561 64.2 0.63 22505 -11.5
## 10 1991 GUAJARÁ-… RO 0.468 0.247 0.662 0.625 64.7 0.6 31240 -10.8
## # … with 16,676 more rows, 1 more variable: lon <dbl>, and abbreviated variable
## # name ¹populacao#Selecionando a variável ano e todas as variáveis que comecem com idhm e salvando no objeto baseIDH e guardando em um objeto chamado sub4
sub4 = basePNUD |>
select(ano, starts_with('idhm')) #selecionando a variável ano e todas que começam com idhm
#Visualizando o objeto
sub4## # A tibble: 16,686 × 5
## ano idhm idhm_e idhm_l idhm_r
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 0.329 0.112 0.617 0.516
## 2 1991 0.432 0.199 0.684 0.593
## 3 1991 0.309 0.108 0.636 0.43
## 4 1991 0.407 0.171 0.667 0.593
## 5 1991 0.386 0.167 0.629 0.547
## 6 1991 0.376 0.151 0.658 0.536
## 7 1991 0.203 0.039 0.572 0.373
## 8 1991 0.425 0.22 0.629 0.553
## 9 1991 0.388 0.159 0.653 0.561
## 10 1991 0.468 0.247 0.662 0.625
## # … with 16,676 more rowsA função select também serve para ordenar as variáveis na base, uma vez que ela monta a nova base em função do ordenamento das variáveis selecionadas. Aqui a função everything usada em select permite com que não seja digitada o nome das demais variáveis.
#É possível ordenar as variáveis na base com a função select
sub5 = basePNUD |>
select(muni, ano, everything()) #modificando a ordem das colunas na base
#Visualizando o objeto
sub5## # A tibble: 16,686 × 14
## muni ano uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ALTA FLORE… 1991 RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63
## 2 ARIQUEMES 1991 RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57
## 3 CABIXI 1991 RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7
## 4 CACOAL 1991 RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66
## 5 CEREJEIRAS 1991 RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6
## 6 COLORADO D… 1991 RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62
## 7 CORUMBIARA 1991 RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59
## 8 COSTA MARQ… 1991 RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65
## 9 ESPIGÃO D'… 1991 RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63
## 10 GUAJARÁ-MI… 1991 RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6
## # … with 16,676 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Deste modo, o comando acima, serviu para fazer com que as variáveis muni e ano fossem as primeiras variáveis da base e em seguida as demais viesem na ordem que já se encontravam no objeto basePNUD.
Já a função where pode ser combinada com as funções is.numeric e is.character para selecionar as variáveis de uma classe específica, por exemplo.
#Selecionando somente as variáveis numéricas
sub6 = basePNUD |>
select(where(is.numeric)) #selecionando somente as variáveis numéricas
#Visualizando o objeto
sub6## # A tibble: 16,686 × 11
## ano idhm idhm_e idhm_l idhm_r espvida rdpc gini populacao lat lon
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835 -11.9 -62.0
## 2 1991 0.432 0.199 0.684 0.593 66.0 319. 0.57 55018 -9.91 -63.0
## 3 1991 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846 -13.5 -60.5
## 4 1991 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534 -11.4 -61.4
## 5 1991 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030 -13.2 -60.8
## 6 1991 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070 -13.1 -60.5
## 7 1991 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737 -13.0 -60.9
## 8 1991 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902 -12.4 -64.2
## 9 1991 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505 -11.5 -61.0
## 10 1991 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240 -10.8 -65.3
## # … with 16,676 more rows#Selecionando somente as variáveis que são characteres
sub7 = basePNUD |>
select(where(is.character)) #selecionando somente as variáveis character
#Visualizando o objeto
sub7## # A tibble: 16,686 × 3
## muni uf regiao
## <chr> <chr> <chr>
## 1 ALTA FLORESTA D'OESTE RO Norte
## 2 ARIQUEMES RO Norte
## 3 CABIXI RO Norte
## 4 CACOAL RO Norte
## 5 CEREJEIRAS RO Norte
## 6 COLORADO DO OESTE RO Norte
## 7 CORUMBIARA RO Norte
## 8 COSTA MARQUES RO Norte
## 9 ESPIGÃO D'OESTE RO Norte
## 10 GUAJARÁ-MIRIM RO Norte
## # … with 16,676 more rows5.4 Função filter
Conseguimos selecionar os dados de todos os municípios referentes somente ao ano de 2000?
A função filter é usada para selecionar linhas da base que satisfaçam um critério (ou um conjunto de critérios). Este processo também é chamado de filtragem.
#Filtrando somente as linhas cujo ano está preenchido com 2000
sub8 = basePNUD |>
filter(ano == 2000) #filtrando as linhas em que ano está preenchido com 2000
#visualizando o objeto
sub8## # A tibble: 5,562 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2000 ALTA FLORE… RO Norte 0.483 0.262 0.698 0.617 66.9 371. 0.58
## 2 2000 ARIQUEMES RO Norte 0.556 0.343 0.742 0.674 69.5 531. 0.59
## 3 2000 CABIXI RO Norte 0.488 0.284 0.677 0.604 65.6 342. 0.58
## 4 2000 CACOAL RO Norte 0.567 0.377 0.745 0.65 69.7 457. 0.55
## 5 2000 CEREJEIRAS RO Norte 0.542 0.338 0.704 0.668 67.2 511. 0.69
## 6 2000 COLORADO D… RO Norte 0.545 0.362 0.71 0.629 67.6 401. 0.57
## 7 2000 CORUMBIARA RO Norte 0.401 0.185 0.649 0.539 63.9 229 0.55
## 8 2000 COSTA MARQ… RO Norte 0.486 0.295 0.65 0.598 64.0 331. 0.58
## 9 2000 ESPIGÃO D'… RO Norte 0.501 0.276 0.71 0.64 67.6 430. 0.63
## 10 2000 GUAJARÁ-MI… RO Norte 0.573 0.398 0.742 0.638 69.5 423. 0.6
## # … with 5,552 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Vale resslatar que o símbolo == significa igual e = significa recebe no R.
Selecionando linhas que satisfazem mais de um critério.
#Filtrando linhas em que ano está preenchido com 2000 e uf com RJ
sub9 = basePNUD |>
filter(ano == 2000, uf == "RJ") #filtrando as linhas em que ano está preenchido com 2000 e uf como RJ
#visualizando o objeto
sub9## # A tibble: 91 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2000 ANGRA DOS … RJ Sudes… 0.599 0.427 0.736 0.684 69.1 564. 0.53
## 2 2000 APERIBÉ RJ Sudes… 0.62 0.487 0.741 0.661 69.5 489. 0.55
## 3 2000 ARARUAMA RJ Sudes… 0.579 0.393 0.736 0.67 69.1 519. 0.56
## 4 2000 AREAL RJ Sudes… 0.611 0.454 0.751 0.668 70.1 512. 0.53
## 5 2000 ARMAÇÃO DO… RJ Sudes… 0.604 0.41 0.736 0.732 69.1 762. 0.58
## 6 2000 ARRAIAL DO… RJ Sudes… 0.632 0.496 0.731 0.695 68.9 603. 0.5
## 7 2000 BARRA DO P… RJ Sudes… 0.626 0.497 0.727 0.678 68.6 543. 0.52
## 8 2000 BARRA MANSA RJ Sudes… 0.641 0.504 0.763 0.685 70.8 569. 0.54
## 9 2000 BELFORD RO… RJ Sudes… 0.57 0.417 0.717 0.62 68.0 379. 0.45
## 10 2000 BOM JARDIM RJ Sudes… 0.561 0.373 0.722 0.657 68.3 478. 0.54
## # … with 81 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Para incluir mais de um critério, basta separarmos os mesmso usando uma ,, isto é, a , equivale a um e. Percebemos que no resultado final foram apresentadas todas as variáveis da base e as linhas que satisfaziam a condição especificada: ser um município do estado do RJ no ano 2000.
Vamos entender qual filtragem está sendo realizada abaixo.
#Filtrando linhas em que ano está preenchido com 2000 ou idhm > 0,7
sub10 = basePNUD |>
filter(ano == 2000 | idhm > 0.7) #filtrando as linhas em que ano está preenchido com 2000 ou idhm é maior do que 0,7
#visualizando o objeto
sub10## # A tibble: 7,463 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2000 ALTA FLORE… RO Norte 0.483 0.262 0.698 0.617 66.9 371. 0.58
## 2 2000 ARIQUEMES RO Norte 0.556 0.343 0.742 0.674 69.5 531. 0.59
## 3 2000 CABIXI RO Norte 0.488 0.284 0.677 0.604 65.6 342. 0.58
## 4 2000 CACOAL RO Norte 0.567 0.377 0.745 0.65 69.7 457. 0.55
## 5 2000 CEREJEIRAS RO Norte 0.542 0.338 0.704 0.668 67.2 511. 0.69
## 6 2000 COLORADO D… RO Norte 0.545 0.362 0.71 0.629 67.6 401. 0.57
## 7 2000 CORUMBIARA RO Norte 0.401 0.185 0.649 0.539 63.9 229 0.55
## 8 2000 COSTA MARQ… RO Norte 0.486 0.295 0.65 0.598 64.0 331. 0.58
## 9 2000 ESPIGÃO D'… RO Norte 0.501 0.276 0.71 0.64 67.6 430. 0.63
## 10 2000 GUAJARÁ-MI… RO Norte 0.573 0.398 0.742 0.638 69.5 423. 0.6
## # … with 7,453 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Percebemos que no resultado final foram apresentadas todas as variáveis da base e as linhas que satisfaziam a condição especificada: ano está preenchido com 2000 ou o idhm > 0,7. O símbolo |significa ou no R.
Suponha que queremos selecionar os municípios dos estados do Rio de Janeiro e São Paulo com idhm > 0,8 no ano de 2010.
#Selecionando as linhas em que uf está preenchido com RJ ou SP e idhm > 0,8 no ano de 2010
sub11 = basePNUD |>
filter(uf %in% c("RJ","SP"), idhm > 0.8, ano == 2010) #filtrando as linhas em que uf está preendhida como RJ ou SP e idhm é maior do que 0,8 e ano está preenchido com 2010
#visualizando o objeto
sub11## # A tibble: 22 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010 NITERÓI RJ Sudes… 0.837 0.773 0.854 0.887 76.2 2000. 0.59
## 2 2010 ÁGUAS DE S… SP Sudes… 0.854 0.825 0.89 0.849 78.4 1581. 0.54
## 3 2010 AMERICANA SP Sudes… 0.811 0.76 0.876 0.8 77.6 1162. 0.47
## 4 2010 ARARAQUARA SP Sudes… 0.815 0.782 0.877 0.788 77.6 1081. 0.5
## 5 2010 ASSIS SP Sudes… 0.805 0.781 0.865 0.771 76.9 967. 0.5
## 6 2010 BAURU SP Sudes… 0.801 0.752 0.854 0.8 76.3 1164. 0.55
## 7 2010 CAMPINAS SP Sudes… 0.805 0.731 0.86 0.829 76.6 1391. 0.56
## 8 2010 ILHA SOLTE… SP Sudes… 0.812 0.782 0.871 0.786 77.2 1063. 0.48
## 9 2010 JUNDIAÍ SP Sudes… 0.822 0.768 0.866 0.834 76.9 1432. 0.53
## 10 2010 PIRASSUNUN… SP Sudes… 0.801 0.736 0.884 0.789 78.0 1086. 0.51
## # … with 12 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>Suponha agora que queremos selecionar linhas com dados do municípios do estado do Rio de Janeiro com idhm entre 0,75 e 0,9 no ano de 2010.
#Selecionando as linhas em que uf está preenchido com RJ e idhm varia entre 0,75 e 0,9 no ano de 2010
sub12 = basePNUD |>
filter(uf == "RJ", idhm > 0.75, idhm < 0.9, ano == 2010) #filtrando as linhas em que uf está preendhida como RJ e idhm é maior do que 0,75 e menor do que 0,9 e ano está preenchido com 2010
#visualizando o objeto
sub12## # A tibble: 10 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010 IGUABA GRA… RJ Sudes… 0.761 0.704 0.841 0.744 75.4 818. 0.56
## 2 2010 MACAÉ RJ Sudes… 0.764 0.681 0.828 0.792 74.7 1103. 0.56
## 3 2010 MANGARATIBA RJ Sudes… 0.753 0.676 0.845 0.746 75.7 832. 0.51
## 4 2010 MARICÁ RJ Sudes… 0.765 0.692 0.85 0.761 76.0 910. 0.49
## 5 2010 NILÓPOLIS RJ Sudes… 0.753 0.716 0.817 0.731 74.0 755. 0.45
## 6 2010 NITERÓI RJ Sudes… 0.837 0.773 0.854 0.887 76.2 2000. 0.59
## 7 2010 RESENDE RJ Sudes… 0.768 0.709 0.839 0.762 75.3 915. 0.52
## 8 2010 RIO DAS OS… RJ Sudes… 0.773 0.689 0.854 0.784 76.3 1051. 0.53
## 9 2010 RIO DE JAN… RJ Sudes… 0.799 0.719 0.845 0.84 75.7 1493. 0.62
## 10 2010 VOLTA REDO… RJ Sudes… 0.771 0.72 0.833 0.763 75.0 921. 0.5
## # … with 3 more variables: populacao <dbl>, lat <dbl>, lon <dbl>É possível combinarmos as funções do dplyr. Por exemplo, suponha que queremos selecionar somente as variáveis ano e aquelas que contenham idhm no seu nome. Além disso, gostaríamos de filtrar a base para que tenhamos somente os dados dos municípios do estado do Ceará no ano de 2010.
#Filtrando as linhas em que uf estão preenchidas com CE e ano 2010 e além disso selevionando as variáveis ano e aquelas que contém idhm no seu nome
sub13 = basePNUD |>
select(ano, contains("idhm"), uf) |> #selecionando as colunas ano, todas que contém idhm nos nomes e uf
filter(uf == "CE", ano == 2010) |> #filtrando as linhas em que uf está preendhida como CE e ano está preenchido com 2010
select(-uf) #retirando a coluna uf
#visualizando o objeto
sub13## # A tibble: 184 × 5
## ano idhm idhm_e idhm_l idhm_r
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010 0.628 0.612 0.748 0.54
## 2 2010 0.606 0.562 0.709 0.559
## 3 2010 0.601 0.517 0.758 0.554
## 4 2010 0.595 0.517 0.724 0.563
## 5 2010 0.569 0.474 0.749 0.518
## 6 2010 0.6 0.524 0.751 0.549
## 7 2010 0.602 0.515 0.774 0.547
## 8 2010 0.601 0.499 0.774 0.563
## 9 2010 0.606 0.582 0.761 0.503
## 10 2010 0.599 0.506 0.772 0.55
## # … with 174 more rowsA seguir, mostramos como o uso da função str_detect pode ser de grande ajuda quando queremos selecionar linhas que são characteres.
library(stringr)
#Selecionando as linhas em que o nome do município contém Rio e ano é igual a 2010
sub14 = basePNUD |>
filter(str_detect(string = muni,
pattern = "Rio"), ano == 2010) #filtrando todas as linhas em que a coluna muni tem a palavra Rio e ano está como 2010
#visualizando o objeto
sub14## # A tibble: 26 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010 Alto Rio D… MG Sudes… 0.62 0.483 0.828 0.595 74.7 324. 0.46
## 2 2010 Carmo do R… MG Sudes… 0.733 0.649 0.85 0.715 76.0 685. 0.52
## 3 2010 Conceição … MG Sudes… 0.665 0.522 0.834 0.675 75.0 533. 0.53
## 4 2010 Desterro d… MG Sudes… 0.639 0.536 0.802 0.607 73.1 349. 0.41
## 5 2010 Entre Rios… MG Sudes… 0.672 0.563 0.802 0.673 73.1 527. 0.5
## 6 2010 São Gonçal… MG Sudes… 0.64 0.542 0.815 0.593 73.9 321. 0.44
## 7 2010 Piedade do… MG Sudes… 0.678 0.593 0.82 0.64 74.2 429. 0.45
## 8 2010 Rio Acima MG Sudes… 0.673 0.508 0.87 0.689 77.2 583. 0.47
## 9 2010 Rio Casca MG Sudes… 0.65 0.519 0.813 0.651 73.8 460. 0.47
## 10 2010 Rio Doce MG Sudes… 0.664 0.567 0.801 0.644 73.1 440. 0.44
## # … with 16 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>5.5 Desafio 1
- Importe o arquivo Base saude.txt e guarde em um objeto chamado base_saude. O número 9 foi usado como código para dado faltante.
- Use o código abaixo para fazer o tratamento das variáveis
#Transformando a variável Sexo em um factor
base_saude$Sexo = factor(x = base_saude$Sexo,
levels = c(0,1),
labels = c("Feminino","Masculino"))
#Transformando a variável HIV em um factor
base_saude$HIV = factor(x = base_saude$HIV,
levels = c(0,1),
labels = c("Não","Sim"))
#Transformando a variável Escolaridade em um factor
base_saude$Escol = factor(x = base_saude$Escol,
levels = c(0,1,2,3,4,5),
labels = c("Analfabeto","Fundamental Incompleto","Fundamental Completo","Medio Incompleto", "Medio Completo","Superior"))
#Transformando a variável DST em um factor
base_saude$DST = factor(x = base_saude$DST,
levels = c(0,1),
labels = c("Não","Sim"))
#Transformando a variável Tipo de DST em um factor
base_saude$Tipo = factor(x = base_saude$Tipo,
levels = c(1,2,3),
labels = c("Sifilis","Hepatite","Outros"))
#Transformando a variável Codigo em um fator
base_saude$Codigo = factor(x = base_saude$Codigo)
#Visualizando a base tratada
base_saude- Exporte com extensão .txt um tibble contendo somente as variáveis que se iniciam com E e os indivíduos com mais de 30 anos.
- Modifique o nome da variável Datacol para Dt_coleta.
- Crie uma sub-base contendo somente os indivíduos que possuem HIV com menos de 50 anos do sexo masculino.
5.6 Função mutate
Função que permite criar/modificar variáveis na base de dados existente.
#Criando o objeto sub15
sub15 = basePNUD |>
mutate(idhm_eNOVA = idhm_e*100,
idhm_lNOVA = idhm_l*100,
idhm_rNOVA = idhm_r*100,
idhmSOMA = idhm_eNOVA + idhm_lNOVA + idhm_rNOVA,
idhm_clas = cut(x = idhm,
breaks = c(0,0.25,0.5,0.75,1),
labels = c("Muito Baixo", "Baixo", "Intermediario","Alto")))
#visualizando o objeto
sub15## # A tibble: 16,686 × 19
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA FLORE… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63
## 2 1991 ARIQUEMES RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.57
## 3 1991 CABIXI RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7
## 4 1991 CACOAL RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66
## 5 1991 CEREJEIRAS RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6
## 6 1991 COLORADO D… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62
## 7 1991 CORUMBIARA RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59
## 8 1991 COSTA MARQ… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65
## 9 1991 ESPIGÃO D'… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63
## 10 1991 GUAJARÁ-MI… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6
## # … with 16,676 more rows, and 8 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>, idhm_eNOVA <dbl>, idhm_lNOVA <dbl>, idhm_rNOVA <dbl>,
## # idhmSOMA <dbl>, idhm_clas <fct>A função mutate nos permite criar novas variáveis na base de dados ao mesmo tempo, inclusive nos permite usar uma das variáveis que estão sendo criadas para a criação de uma outra nova variável. Na construção da variável idhm_clas, utilizamos a função cut. Principais argumentos desta função:
x- a variável que será categorizada;breaks- um vetor com os limites inferiores e superiores das categorias;labels- os rótulos associadas as categorias formadas pelos breaks.
5.7 Função transmute
Função que permite criar um novo objeto com as variáveis criadas de uma base de dados existente. A diferença para a função mutate é que o resultado final irá conter somente as variáveis criadas.
#Criando o objeto sub16
sub16 = basePNUD |>
transmute(idhm_eNOVA = idhm_e*100,
idhm_lNOVA = idhm_l*100,
idhm_rNOVA = idhm_r*100,
idhmSOMA = idhm_eNOVA + idhm_lNOVA + idhm_rNOVA,
idhm_clas = cut(x = idhm,
breaks = c(0,0.25,0.5,0.75,1),
labels = c("Muito Baixo", "Baixo", "Intermediario","Alto")))
#visualizando o objeto
sub16## # A tibble: 16,686 × 5
## idhm_eNOVA idhm_lNOVA idhm_rNOVA idhmSOMA idhm_clas
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 11.2 61.7 51.6 124. Baixo
## 2 19.9 68.4 59.3 148. Baixo
## 3 10.8 63.6 43 117. Baixo
## 4 17.1 66.7 59.3 143. Baixo
## 5 16.7 62.9 54.7 134. Baixo
## 6 15.1 65.8 53.6 134. Baixo
## 7 3.9 57.2 37.3 98.4 Muito Baixo
## 8 22 62.9 55.3 140. Baixo
## 9 15.9 65.3 56.1 137. Baixo
## 10 24.7 66.2 62.5 153. Baixo
## # … with 16,676 more rows5.8 Função arrange
Conseguimos criar uma sub-base, contendo somente os dados de 2010 e as variáveis cujos nomes iniciam com idhm e o nome do municipio, ordenadas de forma crescente por idhm_r?
A função arrange é usada para ordenar as linhas de um objeto tibble.
#Criando o objeto sub17
sub17 = basePNUD |>
select(muni,ano,starts_with("idhm")) |> #selecionando as variáveis muni, ano e aquelas que começam com idhm
filter(ano == 2010) |> #filtrando somente as linhas em que ano está preenchido com 2010
select(-ano) |> #descartando a variável ano
arrange(idhm_r) #ordenando as linhas de forma crescente para a variável idhm_r
#visualizando o objeto
sub17## # A tibble: 5,562 × 5
## muni idhm idhm_e idhm_l idhm_r
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 MARAJÁ DO SENA 0.452 0.299 0.774 0.4
## 2 BELÁGUA 0.512 0.455 0.707 0.417
## 3 FERNANDO FALCÃO 0.443 0.286 0.728 0.417
## 4 CACHOEIRA GRANDE 0.537 0.476 0.773 0.422
## 5 AMAJARI 0.484 0.319 0.815 0.437
## 6 SANTO ANTÔNIO DO IÇÁ 0.49 0.353 0.759 0.438
## 7 UIRAMUTÃ 0.453 0.276 0.766 0.439
## 8 SERRANO DO MARANHÃO 0.519 0.433 0.735 0.44
## 9 HUMBERTO DE CAMPOS 0.535 0.455 0.759 0.443
## 10 JENIPAPO DOS VIEIRAS 0.49 0.346 0.766 0.445
## # … with 5,552 more rowsSe quisermos apresentar em ordem decrescente, precisamos usar a função desc na variável idhm_r dentro da função arrange.
#Criando o objeto sub17
sub17 = basePNUD |>
select(muni,ano,starts_with("idhm")) |> #selecionando as variáveis muni, ano e aquelas que começam com idhm
filter(ano == 2010) |> #filtrando somente as linhas em que ano está preenchido com 2010
select(-ano) |> #descartando a variável ano
arrange(desc(idhm_r)) #ordenando as linhas de forma decrescente para a variável idhm_r
#visualizando o objeto
sub17## # A tibble: 5,562 × 5
## muni idhm idhm_e idhm_l idhm_r
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 SÃO CAETANO DO SUL 0.862 0.811 0.887 0.891
## 2 NITERÓI 0.837 0.773 0.854 0.887
## 3 VITÓRIA 0.845 0.805 0.855 0.876
## 4 SANTANA DE PARNAÍBA 0.814 0.725 0.849 0.876
## 5 FLORIANÓPOLIS 0.847 0.8 0.873 0.87
## 6 PORTO ALEGRE 0.805 0.702 0.857 0.867
## 7 Nova Lima 0.813 0.704 0.885 0.864
## 8 BRASÍLIA 0.824 0.742 0.873 0.863
## 9 SANTOS 0.84 0.807 0.852 0.861
## 10 BALNEÁRIO CAMBORIÚ 0.845 0.789 0.894 0.854
## # … with 5,552 more rows5.9 Função group_by e summarise
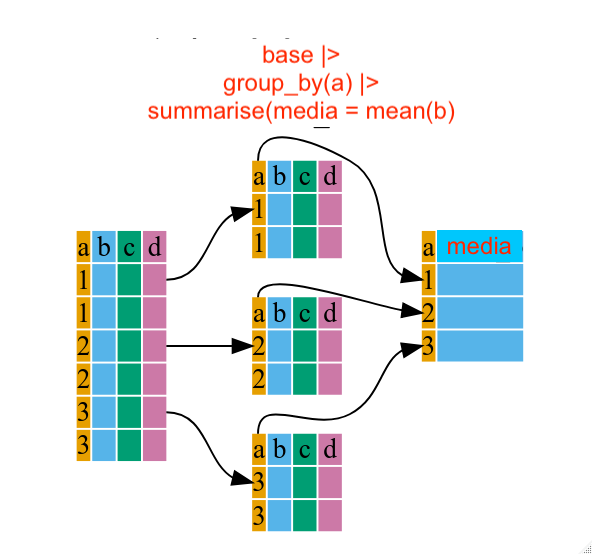
É muito comum usarmos estas funções de forma conjunta. As figuras abaixo ilustram o que a funçào group_by faz sozinha e quando aliada a função summarize.
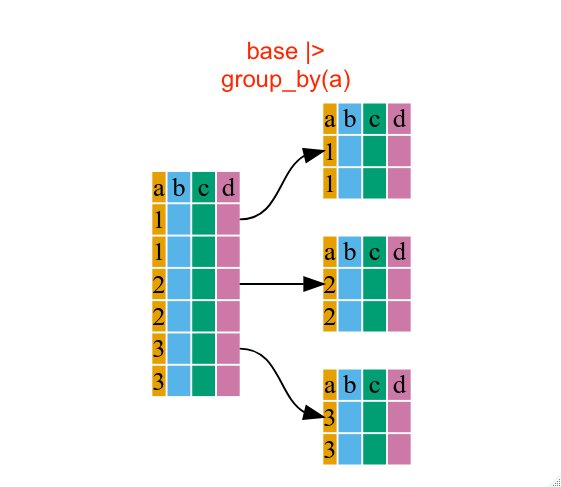
Basicamente a função group_by reorganiza o tibble em sub-bases de acordo com a variável indicada na função sem que haja uma separação em objetos diferentes, isto é, ele cria uma espécie de indicador para cada linha, que funciona como uma filtragem da base de acordo com os valores distintos da variável utilizada para o agrupamento, mas sem modificar o objeto original. No exemplo acima, a base é dividiva em 3 sub-bases, de acordo com os valores distintos da variável a.
Quando o objeto se encontra agrupado, qualquer ação futura executada nele, será realizada em cada uma das sub-bases criadas. Por exemplo, veja na figura abaixo, que após o agrupamento é pedido para se calcular a média da variável b. O objeto final tem a mesma quantidade de linhas que o número de sub-bases identificadas na fase de agrupamento. Para cada sub-base, foi calculado o valor da média da variável b. Por exemplo, o primeiro valor da coluna media do objeto final se refere a média dos valores de b para todas as linhas que tinha a variável a preenchida como 1.
Vamos calcular a expectativa de vida média dos municípios por regiões no ano de 2010 e o número de municípios em cada uma das regiões.
#Criando o objeto resumo1
resumo1 = basePNUD |>
filter(ano == 2010) |> #filtrando somente os dados de 2010
group_by(regiao) |> #agrupando por regiao
summarise(num_muni = n(), #calculando o número de municípios por regiao
med_espvida = mean(x = espvida, na.rm = TRUE)) #calculando a expectativa de vida média dos municípios por regiao
#visualizando o objeto
resumo1## # A tibble: 5 × 3
## regiao num_muni med_espvida
## <chr> <int> <dbl>
## 1 Centro-Oeste 465 74.3
## 2 Nordeste 1794 70.3
## 3 Norte 449 71.8
## 4 Sudeste 1667 74.7
## 5 Sul 1187 75.1A função n() seria equivalente a função length. Pelo resultado final, percebemos que no ano de 2010 existiam 465 municípios na região Centro-oeste e a expectativa de vida média dos municípios era de 74,3 anos.
A função summarise será extremamente útil para calcularmos medidas resumos de interesse para subgrupos da base de dados.
#Criando o objeto resumo2
resumo2 = basePNUD |>
filter(ano == 2000) |> #filtrando somente os dados de 2000
group_by(uf) |> #agrupando por UF
summarise(idhm_minimo = min(x = idhm, na.rm = TRUE), #calculando a idhm minimo dos municípios por UF
idhm_maximo = max(x = idhm, na.rm = TRUE), #calculando a idhm maximo dos municípios por UF
idhm_medio = mean(x = idhm, na.rm = TRUE), #calculando a idhm medio dos municípios por UF
)
#visualizando o objeto
resumo2## # A tibble: 27 × 4
## uf idhm_minimo idhm_maximo idhm_medio
## <chr> <dbl> <dbl> <dbl>
## 1 AC 0.222 0.591 0.416
## 2 AL 0.281 0.584 0.391
## 3 AM 0.287 0.601 0.399
## 4 AP 0.415 0.622 0.494
## 5 BA 0.283 0.654 0.427
## 6 CE 0.326 0.652 0.449
## 7 DF 0.725 0.725 0.725
## 8 ES 0.468 0.759 0.578
## 9 GO 0.396 0.715 0.558
## 10 MA 0.261 0.658 0.392
## # … with 17 more rows5.10 Função across
Função que permite aplicar uma mesma ação a diversas colunas de um tibble.
Suponha que queiramos calcular a média de todas as variáveis numéricas relacionadas com o idhm, para cada regiao em todos os anos observados.
#Criando o objeto resumo3
resumo3 = basePNUD |>
group_by(regiao, ano) |> #agrupando a base por regiao e ano
summarise(across(.cols = where(is.numeric) & contains("idhm"), #indicando que somente sobre as colunas numericas que contem no nome idhm a acao abaixo será realizada
.fns = ~mean(.x, na.rm = TRUE))) #indicando que a media sera calculada para as colunas indicadas acima
#visualizando o objeto
resumo3## # A tibble: 15 × 6
## # Groups: regiao [5]
## regiao ano idhm idhm_e idhm_l idhm_r
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Centro-Oeste 1991 0.404 0.182 0.668 0.569
## 2 Centro-Oeste 2000 0.551 0.363 0.750 0.624
## 3 Centro-Oeste 2010 0.690 0.584 0.822 0.684
## 4 Nordeste 1991 0.294 0.117 0.559 0.420
## 5 Nordeste 2000 0.422 0.246 0.653 0.481
## 6 Nordeste 2010 0.591 0.488 0.754 0.562
## 7 Norte 1991 0.307 0.108 0.609 0.481
## 8 Norte 2000 0.444 0.247 0.690 0.533
## 9 Norte 2010 0.608 0.490 0.780 0.593
## 10 Sudeste 1991 0.438 0.223 0.693 0.570
## 11 Sudeste 2000 0.590 0.433 0.763 0.629
## 12 Sudeste 2010 0.699 0.608 0.828 0.681
## 13 Sul 1991 0.453 0.235 0.715 0.571
## 14 Sul 2000 0.603 0.444 0.777 0.642
## 15 Sul 2010 0.714 0.613 0.835 0.713Suponha que queiramos que todas as variáveis numéricas possuam duas casas decimais na base de dados.
#Criando o objeto resumo3
sub18 = basePNUD |>
mutate(across(.cols = where(is.numeric), #indicando que somente sobre as colunas numericas a acao abaixo será realizada
.fns = ~round(.x, digits = 2))) #indicando que um arredondamento com duas casas decimais sera obtido para as colunas indicadas acima
#visualizando o objeto
sub18## # A tibble: 16,686 × 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1991 ALTA FLORE… RO Norte 0.33 0.11 0.62 0.52 62.0 198. 0.63
## 2 1991 ARIQUEMES RO Norte 0.43 0.2 0.68 0.59 66.0 319. 0.57
## 3 1991 CABIXI RO Norte 0.31 0.11 0.64 0.43 63.2 116. 0.7
## 4 1991 CACOAL RO Norte 0.41 0.17 0.67 0.59 65.0 320. 0.66
## 5 1991 CEREJEIRAS RO Norte 0.39 0.17 0.63 0.55 62.7 240. 0.6
## 6 1991 COLORADO D… RO Norte 0.38 0.15 0.66 0.54 64.5 225. 0.62
## 7 1991 CORUMBIARA RO Norte 0.2 0.04 0.57 0.37 59.3 81.4 0.59
## 8 1991 COSTA MARQ… RO Norte 0.42 0.22 0.63 0.55 62.8 250. 0.65
## 9 1991 ESPIGÃO D'… RO Norte 0.39 0.16 0.65 0.56 64.2 263. 0.63
## 10 1991 GUAJARÁ-MI… RO Norte 0.47 0.25 0.66 0.62 64.7 391. 0.6
## # … with 16,676 more rows, and 3 more variables: populacao <dbl>, lat <dbl>,
## # lon <dbl>O argumento .cols pode receber um vetor com os nomes das variáveis ou com as posições das variáveis ou funções que indiquem uma condição a ser satisfeita.
5.11 Desafio 2
- Considerando o objeto base_saude. Inclua a variável IMC no objeto. O IMC é calculado dividindo o peso pela altura ao quadrado.
- Usando o arquivo PNUD.csv, obtenha a renda per capta média por município para cada UF brasileira nos anos de 1991, 2000 e 2010.
- Usando o arquivo PNUD.csv, crie uma base que contenha somente a variável nome do município, todas as variáveis numéricas e uma variável que classifica o índice de gini [0;0,3] - baixa, (0,3;0,7] - moderada e (0,7;1] - alta.
5.12 Combinando duas bases de dados no R
Muitas vezes ao trabalharmos com dados, precisamos combinar fontes de dados (arquivos distintos) em uma única fonte para realizarmos nossas análises.
O pacote dplyr possui um conjunto de funções que nos auxiliam a combinar bases do nosso interesse. Trata-se da família de funções join.
Para discutirmos essas funções, trabalharemos com bases pequenas, para visualizarmos o que cada uma das funções da família join faz. Qualquer dúvida, não deixe de acessar o help destas funções.
Para iniciar, vamos importar os objeto Socio.csv e Socio casamento.txt. Eles contém informações sociodemográficas de alguns indivíduos. A variável ID identifica de forma única cada indivíduo na base de dados.
#Importando o arquivo Socio.csv
base_socio = read_csv(file = "Socio.csv")## Rows: 12 Columns: 4
## ── Column specification ───────────────────────────────────
## Delimiter: ","
## chr (1): Sexo
## dbl (3): ID, Idade, Casado
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_socio## # A tibble: 12 × 4
## ID Sexo Idade Casado
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 20 0
## 2 2010 F 21 0
## 3 3010 F 30 1
## 4 4010 M 28 1
## 5 5010 M 21 1
## 6 3040 M 30 0
## 7 2020 F 31 0
## 8 1030 F 10 0
## 9 3021 M 18 0
## 10 9087 M 21 0
## 11 2432 F 35 1
## 12 3456 F 65 1#Importando o arquivo Socio casamento.txt
base_casamento = read_delim(file = "Socio casamento.txt",
delim = "L")## Rows: 6 Columns: 4
## ── Column specification ───────────────────────────────────
## Delimiter: "L"
## chr (1): Sexo_companheiro
## dbl (3): ID, Tempo_casado, Primeiro_casamento
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_casamento## # A tibble: 6 × 4
## ID Tempo_casado Primeiro_casamento Sexo_companheiro
## <dbl> <dbl> <dbl> <chr>
## 1 3010 8 0 F
## 2 4010 2 1 F
## 3 5010 1 1 F
## 4 2432 10 0 M
## 5 3456 32 0 M
## 6 1456 32 0 FComo combinar as bases base_socio e base_casamento para termos somente os indivíduos comuns nas duas bases e todas as variáveis em um único objeto???
Nossa resposta para esses questionamentos sempre será: TIDYVERSE neles.
A função que será usada para alcançarmos o objetivo desejado é a função inner_join. O objetivo da função é retornar um objeto com todas as linhas da base x que tem uma correspondência com a base y (correspondência que será avaliada por meio de uma chave), e todas as colunas de x e y. A animação abaixo exemplifica a função (todas as animações foram retiradas do material de Garrick Aden‑Buie).

Principais argumentos da função inner_join (e das demais funções da família join):
x- um dos tibbles a serem fundidos (o tibble da esquerda);y- um dos tibbles a serem fundidos (o tibble da direita);by- a variável (as variáveis) que utilizaremos para juntar os tibbles.
# Função inner_join: Combina as duas bases incluindo todas as variáveis
# de ambas as bases e todas as linhas comuns as duas bases
merge1 = inner_join(x = base_socio, #primeira base
y = base_casamento, #segunda base
by = "ID") #chave comum as duas bases
#Visualizando o objeto
merge1## # A tibble: 5 × 7
## ID Sexo Idade Casado Tempo_casado Primeiro_casamento Sexo_companheiro
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 3010 F 30 1 8 0 F
## 2 4010 M 28 1 2 1 F
## 3 5010 M 21 1 1 1 F
## 4 2432 F 35 1 10 0 M
## 5 3456 F 65 1 32 0 MPodemos notar que o comando retorna somente os indivíduos casados (presentes nas duas bases) e as variáveis de ambas as bases.
Já a função left_join tem por objetivo retornar um objeto com todas as linhas da base x e todas as colunas de x e y. Linhas em x que não possuem correspondência em y terão valores NA nas novas colunas criadas.

# Função left_join: Combina as duas bases incluindo todas as variáveis
# de ambas as bases e todas as linhas da base a esquerda
merge2 = left_join(x = base_socio, #primeira base
y = base_casamento, #segunda base
by = "ID") #chave comum as duas bases
#Visualizando o objeto
merge2## # A tibble: 12 × 7
## ID Sexo Idade Casado Tempo_casado Primeiro_casamento Sexo_companheiro
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1010 M 20 0 NA NA <NA>
## 2 2010 F 21 0 NA NA <NA>
## 3 3010 F 30 1 8 0 F
## 4 4010 M 28 1 2 1 F
## 5 5010 M 21 1 1 1 F
## 6 3040 M 30 0 NA NA <NA>
## 7 2020 F 31 0 NA NA <NA>
## 8 1030 F 10 0 NA NA <NA>
## 9 3021 M 18 0 NA NA <NA>
## 10 9087 M 21 0 NA NA <NA>
## 11 2432 F 35 1 10 0 M
## 12 3456 F 65 1 32 0 MPodemos notar que o comando retorna todos os indivíduos da base a esquerda (a base_socio) e as variáveis de ambas as bases. Como a base_casamento não possui as informações para os solteiros, as variáveis referentes a base base_casamento são preenchidas com NA na base combinada.
A seguir, vamos utilizar outros dois tibbles contendo informações sobre municípios. O arquivo Inf muni.dta possui dados de alguns municípios nos anos de 2000 e 2010. Já o arquivo Info capitais.xlsx possui dados para algumas capitais. Desejamos unir as duas bases, de modo que o resultado seja uma base com todos os munícipios e todas as variáveis. As variáveis IDmun e ID são códigos para identificar os municípios nas bases Inf muni.dta e Info capitais.xlsx, respectivamente.
#Ativando pacote
library(haven)
#Importando o arquivo Inf muni.dta
base_muni = read_dta(file = "Inf muni.dta")#Visualizando o objeto
base_muni## # A tibble: 12 × 4
## IDmun ano Capital popjovem
## <dbl> <dbl> <chr> <dbl>
## 1 101010 2000 S 1228
## 2 101010 2010 S 2221
## 3 201010 2000 N 1230
## 4 201010 2010 N 2228
## 5 301010 2000 S 1225
## 6 301010 2010 S 2225
## 7 401010 2000 N 731
## 8 401010 2010 N 1225
## 9 501010 2000 S 828
## 10 501010 2010 S 3421
## 11 601010 2000 N 1235
## 12 601010 2010 N 5429#Ativando pacote
library(readxl)
#Importando o arquivo Info capitais.xlsx
base_capi = read_excel(path = "Info capitais.xlsx",
sheet = 1)#Visualizando o objeto
base_capi## # A tibble: 6 × 4
## ID ano IDH Capital
## <dbl> <dbl> <dbl> <chr>
## 1 901010 2000 0.65 S
## 2 901010 2010 0.7 S
## 3 101010 2000 0.55 S
## 4 101010 2010 0.72 S
## 5 501010 2000 0.7 S
## 6 501010 2010 0.78 SA função full_join tem por objetivo retornar um objeto com todas as linhas e todas as colunas das bases x e y. Quando não houver correspondência ns duas bases, serão retornado valores NA.

# Função full_join: Combina as duas bases incluindo todas as variáveis
# e todas as linhas de ambas as bases
merge3 = full_join(x = base_muni, #primeira base
y = base_capi, #segunda base
by = c("IDmun" = "ID")) #chave comum as duas bases## Warning in full_join(x = base_muni, y = base_capi, by = c(IDmun = "ID")): Each row in `x` is expected to match at most 1 row in `y`.
## ℹ Row 1 of `x` matches multiple rows.
## ℹ If multiple matches are expected, set `multiple = "all"`
## to silence this warning.#Visualizando o objeto
merge3## # A tibble: 18 × 7
## IDmun ano.x Capital.x popjovem ano.y IDH Capital.y
## <dbl> <dbl> <chr> <dbl> <dbl> <dbl> <chr>
## 1 101010 2000 S 1228 2000 0.55 S
## 2 101010 2000 S 1228 2010 0.72 S
## 3 101010 2010 S 2221 2000 0.55 S
## 4 101010 2010 S 2221 2010 0.72 S
## 5 201010 2000 N 1230 NA NA <NA>
## 6 201010 2010 N 2228 NA NA <NA>
## 7 301010 2000 S 1225 NA NA <NA>
## 8 301010 2010 S 2225 NA NA <NA>
## 9 401010 2000 N 731 NA NA <NA>
## 10 401010 2010 N 1225 NA NA <NA>
## 11 501010 2000 S 828 2000 0.7 S
## 12 501010 2000 S 828 2010 0.78 S
## 13 501010 2010 S 3421 2000 0.7 S
## 14 501010 2010 S 3421 2010 0.78 S
## 15 601010 2000 N 1235 NA NA <NA>
## 16 601010 2010 N 5429 NA NA <NA>
## 17 901010 NA <NA> NA 2000 0.65 S
## 18 901010 NA <NA> NA 2010 0.7 SUm ponto que precisamos mencionar aqui é que a variável usada para fundir as bases possuem nomes diferentes nas suas bases, logo, foi preciso informar isso no argumento by, passamos primeiro o nome da chave na base a esquerda e depois o nome da chave na base a direita.
Claramente não atingimos o nosso objetivo com o código acima. O resultado está ERRADO!!! Uma vez que alguns municípios estão aparecendo 4 vezes na base e só temos informações referentes a 2 anos destes municípios. Qual seria o nosso problema?
A chave usada, não identifica de forma única cada linha da base, uma vez que os municípios se repetem, para identificar de forma única, precisaremos usar uma chave secundária (o ano). A função usada está correta, mas seus argumentos precisam ser manipulados de forma adequada.
# Função full_join: Combina as duas bases incluindo todas as variáveis
# e todas as linhas de ambas as bases
merge3 = full_join(x = base_muni, #primeira base
y = base_capi, #segunda base
by = c("IDmun" = "ID", "ano")) #chaves comum as duas bases, primeiro foi passado a chave primária e depois a chave secundária
#Visualizando o objeto
merge3## # A tibble: 14 × 6
## IDmun ano Capital.x popjovem IDH Capital.y
## <dbl> <dbl> <chr> <dbl> <dbl> <chr>
## 1 101010 2000 S 1228 0.55 S
## 2 101010 2010 S 2221 0.72 S
## 3 201010 2000 N 1230 NA <NA>
## 4 201010 2010 N 2228 NA <NA>
## 5 301010 2000 S 1225 NA <NA>
## 6 301010 2010 S 2225 NA <NA>
## 7 401010 2000 N 731 NA <NA>
## 8 401010 2010 N 1225 NA <NA>
## 9 501010 2000 S 828 0.7 S
## 10 501010 2010 S 3421 0.78 S
## 11 601010 2000 N 1235 NA <NA>
## 12 601010 2010 N 5429 NA <NA>
## 13 901010 2000 <NA> NA 0.65 S
## 14 901010 2010 <NA> NA 0.7 SPodemos ver que a modificação realizada, isto é, a inclusão da segunda chave, permite que a junção das base seja feita de forma correta. Temos como resultado final uma base com todos os municípios, incluindo as linhas comuns as duas bases, as que só se encontravam em base_muni e os que só se encontravam em base_capi e as variáveis das duas bases.
Podemos perceber também que em base_muni e base_capi possuem variáveis com o mesmo nome. O objeto resultante possui as duas variáveis Capital, o sufixo .x indica que a variável é proveniente da base a esquerda e o .y indica que a variável proveniente da base a direita.
No argumento by, como o nome da variável código estava diferente nas duas bases foi preciso informar o nome em cada base, para a variável ano já não foi necessário.
Ainda podemos citar as funções:
anti_join: retorna as linhas de x sem correspondentes em y, mantendo apenas as colunas de x,right_join: retorna todas as linhas de y, e todas as colunas de x e y.
5.13 Combinando dados verticalmente
Os objetos Socio familia.rds, Socio familia2.txt e Socio familia3.sas7bdat contém informações sobre sociodemográficas de alguns indivíduos. Todas as base contém exatamente as mesmas variáveis. Vamos iniciar importando os arquivos.
#Importando o arquivo Socio familia.rds
base_socio1 = read_rds(file = "Socio familia.rds")#Visualizando o objeto
base_socio1## # A tibble: 5 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0
## 3 3010 M 18 3
## 4 4010 F 15 5
## 5 5010 F 19 0#Importando o arquivo Socio familia2.txt
base_socio2 = read_delim(file = "Socio familia2.txt")## Rows: 3 Columns: 4
## ── Column specification ───────────────────────────────────
## Delimiter: " "
## chr (1): Sexo
## dbl (3): ID, Idade, irmaos
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_socio2## # A tibble: 3 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0
## 3 5010 F 17 0#Importando o arquivo Socio familia3.sas7bdat
base_socio3 = read_sas(data_file = "Socio familia3.sas7bdat")#Visualizando o objeto
base_socio3## # A tibble: 3 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 4010 F 15 5
## 2 2011 F 20 1
## 3 1017 F 19 1Suponha que desejamos criar um objeto somente com as linhas comuns as bases base_socio1 e base_socio2 Podemos realizar esta tarefa usando a função intersect.
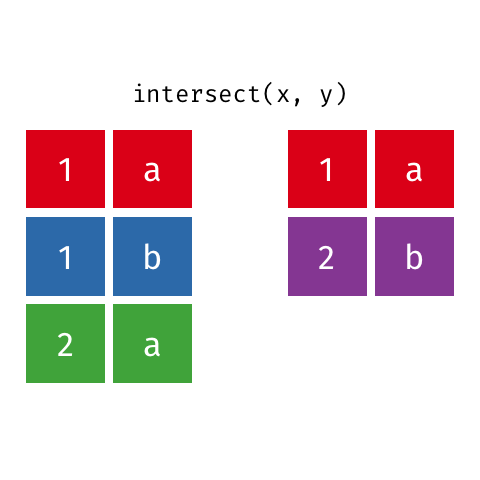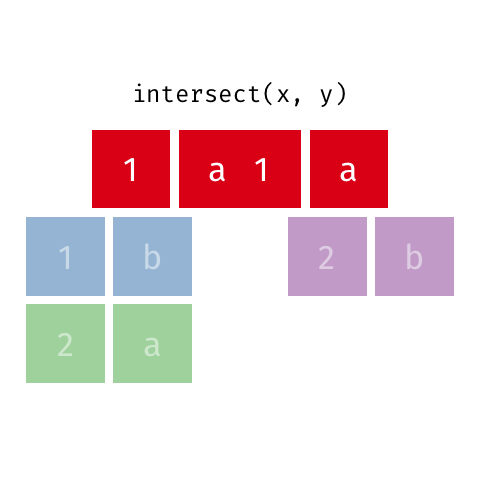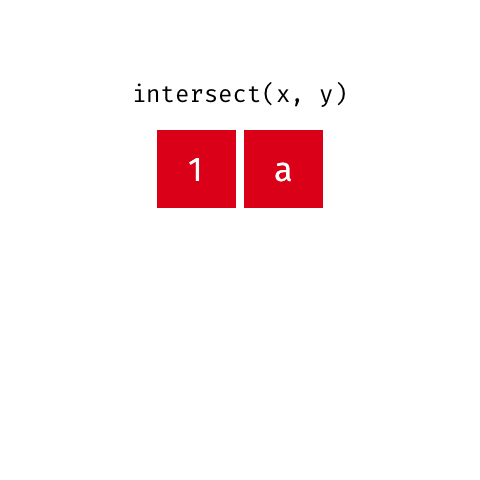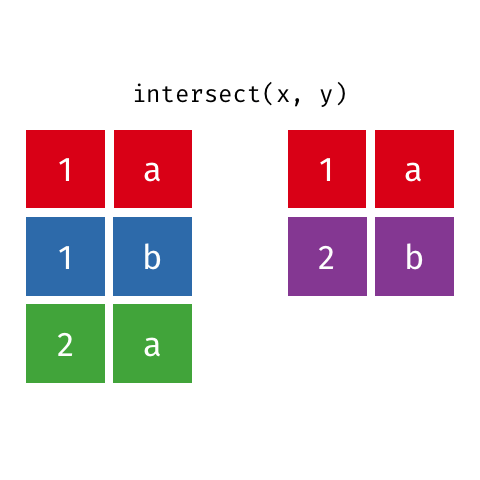
Principais argumentos da função intersect
x- um dos tibbles a serem operacionalizados;y- um dos tibbles a serem operacionalizados.
#Identificando as linhas comuns as duas bases
comum = intersect(x = base_socio1, #primeira base
y = base_socio2) #segunda base
#Visualizando o objeto
comum## # A tibble: 2 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0O resultado retorna todas as linhas comuns nos objetos base_socio1 e base_socio2.
Já a função setdiff retorna os elementos de uma base, retirando as interseções que a mesma possui com uma outra base.
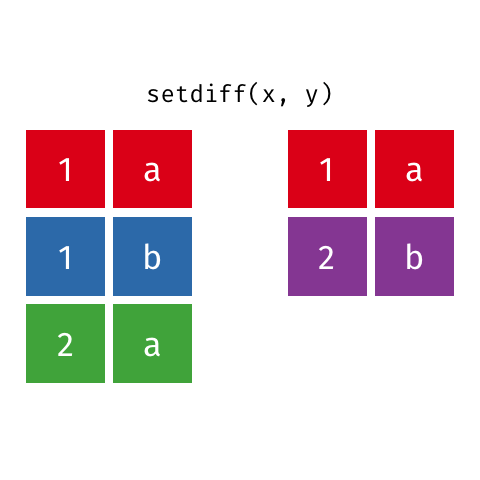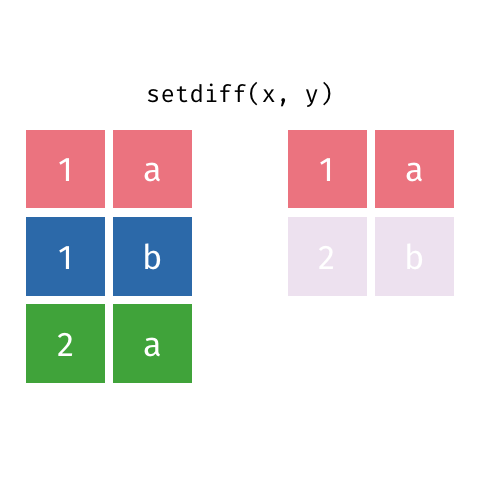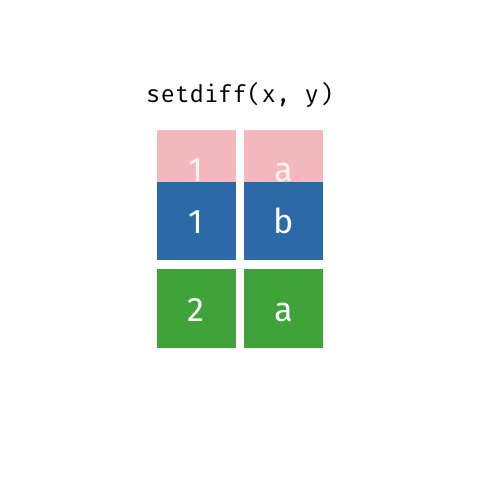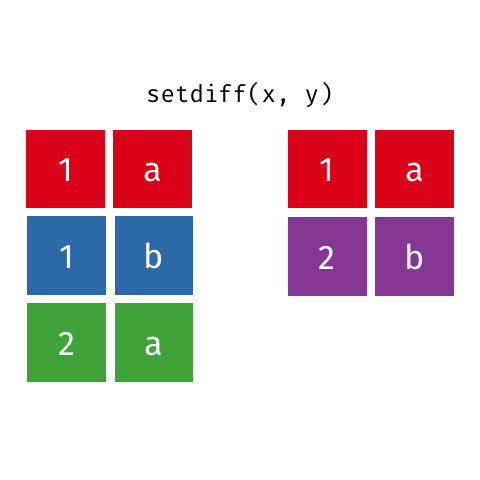
Principais argumentos da função setdiff
x- um dos tibbles a serem operacionalizados;y- um dos tibbles a serem operacionalizados.
#Identificando as linhas de base_socio1 que não se encontram em base_socio2
diferenca = setdiff(x = base_socio1, #primeira base
y = base_socio3) #segunda base
#Visualizando o objeto
diferenca## # A tibble: 4 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0
## 3 3010 M 18 3
## 4 5010 F 19 0O resultado retorna todas as linhas do objeto base_socio1, retirando as linhas comuns entre os objetos base_socio1 e base_socio3.
Suponha que desejamos criar um objeto com todas as linhas das bases base_socio1 e base_socio3. Podemos realizar esta tarefa usando a função union.
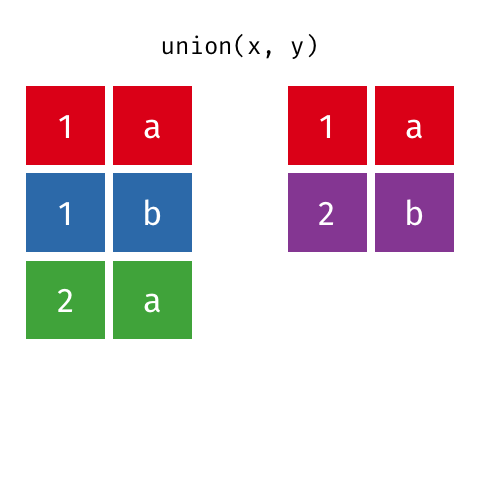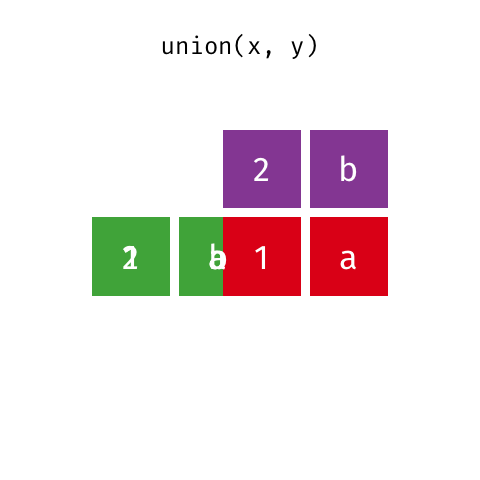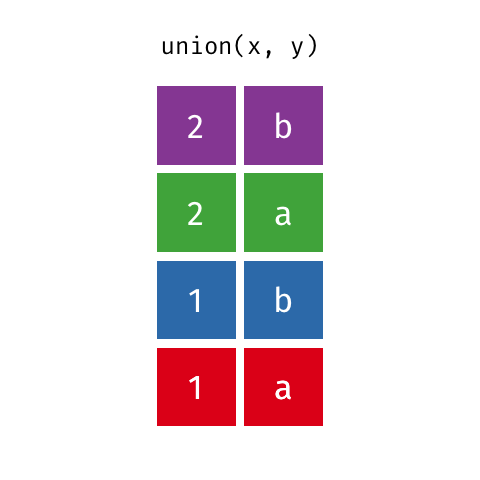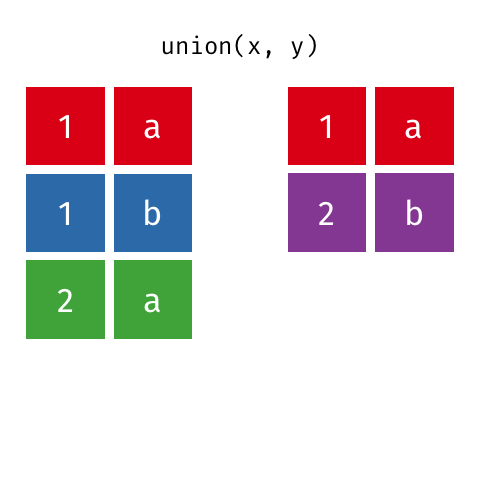
Principais argumentos da função union
x- um dos tibbles a serem operacionalizados;y- um dos tibbles a serem operacionalizados.
#Unindo as linhas de base_socio1 e base_socio3, sem duplicatas
uniao = union(x = base_socio1, #primeira base
y = base_socio3) #segunda base
#Visualizando o objeto
uniao## # A tibble: 7 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0
## 3 3010 M 18 3
## 4 4010 F 15 5
## 5 5010 F 19 0
## 6 2011 F 20 1
## 7 1017 F 19 1O resultado retorna todas as linhas dos objetos base_socio1 e base_socio3 Perceba que o objeto base_socio1 possui 5 linhas e o objeto base_socio3 possui 3 linhas, entretanto a ação resultante retorna 7 linhas (e não 8), isto acontece porque existe 1 indivíduo comum as duas bases. A função union elimina linhas repetidas.
A função bind_rows tem o objetivo de empilhar duas bases de dados.

#Empilhando objetos
empilhando = bind_rows(base_socio1, base_socio3)
#Visualizando o objeto
empilhando## # A tibble: 8 × 4
## ID Sexo Idade irmaos
## <dbl> <chr> <dbl> <dbl>
## 1 1010 M 21 3
## 2 2010 F 31 0
## 3 3010 M 18 3
## 4 4010 F 15 5
## 5 5010 F 19 0
## 6 4010 F 15 5
## 7 2011 F 20 1
## 8 1017 F 19 1Percebemos que o resultado é diferente da função union, uma vez que a função bind_rows somente empilha sem checar se existem linhas repetidas. O resultado final possui 8 linhas, incluindo duas vezes a linha referente ao indivíduo 4010.
Agora vamos importar o arquivo Socio familia4.csv, que contém variáveis diferentes poara os mesmos indivíduos que se encontram no objeto base_socio3.
#Importando o arquivo Socio familia4.csv
base_socio4 = read_csv(file = "Socio familia4.csv")## Rows: 3 Columns: 3
## ── Column specification ───────────────────────────────────
## Delimiter: ","
## chr (2): casado, mora_pai
## dbl (1): ID
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.#Visualizando o objeto
base_socio4## # A tibble: 3 × 3
## ID casado mora_pai
## <dbl> <chr> <chr>
## 1 4010 N S
## 2 2011 S N
## 3 1017 N SA função bind_cols tem o objetivo de acoplar duas bases de dados, uma ao lado da outra. Naturalmente para fazer o uso desta função, as bases precisam ter a mesma dimensão e a mesma ordenação.

#Acoplando objetos
lado_a_lado = bind_cols(base_socio3, base_socio4)## New names:
## • `ID` -> `ID...1`
## • `ID` -> `ID...5`#Visualizando o objeto
lado_a_lado## # A tibble: 3 × 7
## ID...1 Sexo Idade irmaos ID...5 casado mora_pai
## <dbl> <chr> <dbl> <dbl> <dbl> <chr> <chr>
## 1 4010 F 15 5 4010 N S
## 2 2011 F 20 1 2011 S N
## 3 1017 F 19 1 1017 N SPodemos perceber que o resultado inclui a variável ID duas vezes na base. Como os dois objetos possuem o mesmo tamanho e a mesma ordenação, o correto seria retirarmos a coluna ID de um dos dois objetos como feito abaixo.
#Acoplando objetos
lado_a_lado = base_socio3 |>
select(-ID) |>
bind_cols(base_socio4)
#Visualizando o objeto
lado_a_lado## # A tibble: 3 × 6
## Sexo Idade irmaos ID casado mora_pai
## <chr> <dbl> <dbl> <dbl> <chr> <chr>
## 1 F 15 5 4010 N S
## 2 F 20 1 2011 S N
## 3 F 19 1 1017 N S5.14 Desafio 3
- Importe os arquivos Dados Socio geral.csv (dados de pessoas que trabalham e de pessoas que não trabalham) e Dados Trabalho empregados.rds (dados referentes ao emprego das pessoas que trabalham).
- Crie uma base de dados que contenha todas as variáveis disponíveis nos arquivos Dados Socio geral.csv e Dados Trabalho empregados.rds e somente os indivíduos que trabalham.
- Crie uma base de dados que contenha todas as variáveis disponíveis nos arquivos Dados Socio geral.csv e Dados Trabalho empregados.rds e todos os indivíduos.
- Desejamos criar um arquivo que contenha todas as variáveis sóciodemográficas dos indivíduos, incluindo as informações disponíveis sobre os estados. Use os arquivos *Dados Socio geral.csv e Dados UF.csv**.