9 Writing and Visualizing
9.1 Final Project and Presentation
Here (reproduced from the syllabus) is information on your final projects in this course:
The final project of this course is to produce a short (less than 1000 words) data-journalism style blog post that makes use of data. For this project you will find your own data and use it to produce a series of figures and tables to support an argument suitable for a non-technical audience. This project brings together the two learning goals of this course: the technical ability to find, clean, and present data; as well as the ability to write about your findings in a clear and persuasive way. Accordingly, you will be graded on both the quality and rigorousness of your statistical findings, as well as the presentation and writing of the piece. To emphasize: a major component of this project and of your grade is determined by how you write your results up. 1000 words is short for a final project. As such, I would highly encourage you to start work on this early. Part of the goal of the problem sets is to have you think a lot about how to present statistics in an approachable and non-technical way. Many undergrads spend 95% of their time writing and 5% of their time editing. (In your working life post-undergrad these two percentages will be almost exactly flipped!) Given the amount of time and the light word count, my expectation is that you meet with the teaching team to talk about your research question relatively early, and spend the majority of the time editing your work, not writing.
Presentations will be about the same topic as your final paper (see below). These presentations will take place in week 12 during your usual recitation period. Each presentation will be no more than 3 minutes long (with a strict cutoff). You will present exactly one slide with one figure on it that you think best tells the “story” of your final paper. The goal is to walk the audience through why you have a question they want to know the answer to, and why you have the data to answer it. This format is commonly used in “Three Minute Thesis” competitions. An example of this format is posted on Canvas.
Both of these formats are set up to be particularly short and focused on purpose. They are set up this way to force you into thinking about some fundamental things regarding reading and writing that I think are important to work as a data scientist.
Learning how to write about and present data science work is at least as important as any R skills. None of this happens in a vacuum, and eventually you are going to have to email or show someone what you are doing. Even if you do very little formal “writing” or “presenting”, it’s important to internalize skills that will allow you to communicate findings effectively.
9.2 The Pessimistic Writer
Much of this advice is based on William Zinnser’s “On Writing Well” and the pdf Writing Tips for PhD Students.
The fundamental orientation that I take for writing is that nobody cares.
This may come off as overly pessimistic, but thinking about the reader in this way helps me to re-frame the task that I am doing. Pretending that the reader cares about what I am doing would invite laziness: why think hard about being clear and interesting if our mythical ready will tolerate sludge?
Here is what Zinnser says about readers:
Who is this elusive creature, the reader? The reader is someone with an attention span of about 30 seconds – a person assailed by many forces competing for attention…. The man or woman snoozing in a chair with a magazine or a book is a person who was being given too much unnecessary trouble by the writer.
I have found it fairly remarkable the degree to which you have to hold your reader’s hands and to provide them incentives to learn what it is that you are doing. This became abundantly clear when I started writing articles for peer review. I would get reviews back of my scholarly work that totally misunderstood what I was saying. While I was initially angry, on closer inspection it was clear that my writing was dense, and worse, it was dull. With the same content I focused on my writing and placed work in top journals.
So what are you going to do, now that you know that you have a lazy reader who doesn’t care about you?
9.2.1 Know what you are trying to say
If your reader isn’t paying attention then you better make it super clear what it is that you are trying to say.
Think about the best newspaper article or academic article that you have recently read: how would you describe it? Like, how many words would it take you to tell a friend about it? Ten? Twenty? If that’s what you remember from the best article you’ve read recently, we can only really expect our readers to similarly only remember ten or twenty words from the hundreds that we write.
If that’s the case, you better know what you want those ten words to be!
Another key quotes from Zinnser:
Writers must therefore constantly ask: what am I trying to say? Surprisingly often they don’t know. Then they must look at what they’ve written and ask: have I said it? Is it clear to someone encountering the subject for the first time? If it’s not, some fuzz has worked its way into the machinery. The clear writer is some-one clearheaded enough to see this stuff for what is is: fuzz.
Your foremost thought throughout writing anything is what the one sentence someone is going to remember is going to be. This includes both making this sentence clear within the first 3 or 4 sentences of your paper, and also constantly circling back to it throughout your piece. This flows directly from getting into the head-space of the reader asking “Why should I read this?”
The biggest impediment to working in this way is what I call a “And here’s another thing!” essay. In this type of writing the author is more interested in demonstrating all the things that they know rather than trying to make a single central point. The result is largely unreadable (and, indeed, no one will read it.)
Focusing on making a singular point and avoiding an info-dump essay leads to the next point…
9.2.2 The ordering of ideas is paramount
While you might know what your “one point” is, you can’t just copy and paste that 100 times to fill out your 1000 words. So what are you actually supposed to do to write an essay where people will walk away understand what you are trying to tell them.
Here’s what Zinnser has to say in two quotes:
Writing is not a special language owned by the English teacher. Writing is thinking on paper. Anyone who thinks clearly can write clearly, about anything at all… Writing, demystified, is just another way for scientists to transmit what they know.
Describing how a process works is valuable for two reasons. It forces you to make sure you know how it works. Then it forces you to take the reader through the same sequence of ideas and deductions that made the process clear to you… It’s just a matter of putting one sentence after another. The ‘after’, however, is crucial. Nowhere else must you work so hard to write sentences that form a linear sequence.
The way that we transmit our one idea to our readers is generated from spending a great deal of time thinking through the logical order in which information has to be presented to people in order for them to understand our point.
Elsewhere, Zinnser says “Clear writing is clear thinking”. And this is really the key: the process of writing can only really start when you have a clear sense of what you are trying to argue and what the sequence of ideas and deductions allow a reader to reach the right conclusion.
(While good writing can only really happen when you are thinking clearly about your topic, for many people the process of writing is how they think. That’s fine! Just know that if you “think through writing” you are going to have to do significant edits after the fact. Oftentimes for me that is just starting over again once I wrote enough to figure out what i’m actually trying to say.)
When it comes to sequencing we have to think about both the order of paragraphs in our essay and the order of sentences within those paragraphs.
The latter (order of sentences) is particularly important for science where you are trying to on-board the reader into relatively complicated things.
Consider this figure (which is from my dissertation). When looking at this figure I want to explain to my readers that this type of pattern is indicative of a “non-nationalized” election. How can I do that?
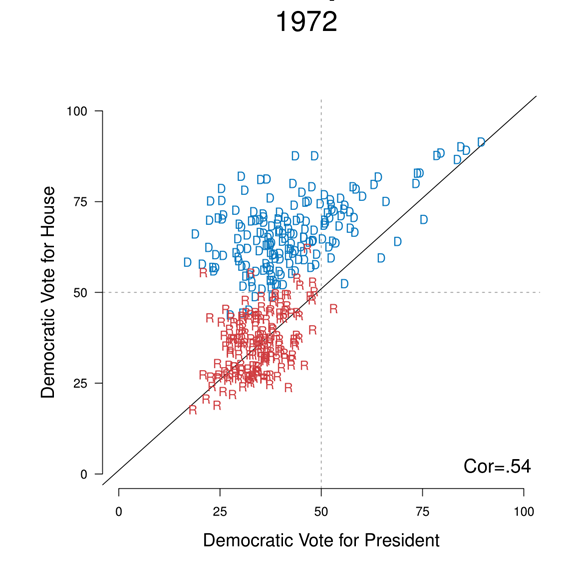
Here is what a bad job would look like
A lack of nationalization is shown in Figure 1. The correlation here is only .54, which is low. There are a lot of Democratic house members that are off the main diagonal, which indicates that they are elected from less nationalized districts. Republicans are largely the same. The correlation is much higher in other more recent years. Nationalization happens when the correlation is a lot higher. In the graph Democratic members are shown in blue and Republicans are shown in Red. The 2008 graph is the same, except that Democrats are elected in Democratic districts and Republicans are elected in Republican districts.
All of these sentences are true, but the order of them makes no sense. The reader (you) probably has no idea what i’m talking about. Why does this show a lack of nationalization? Why is the correlation important? How low is that correlation? What would be high?
Let’s do a better job:
Nationalization was not always present in US voting patterns, and the 1972 election was a particular low point. One way to visualize nationalization is to think about the relationship between how each district votes for president and how they vote for the House. Figure 1 displays, for the 1972 election , the Democratic vote for president in each district on the x-axis and the Democratic for the House in each district on the y-axis. If voters are nationalized and vote simply on the basis of partisanship, all points would be on the 45 degree line. But that’s not what we see in the data. Many House members are in the upper left quadrant: districts that voted to re-elect Republican Richard Nixon, while also returning their Democratic members to the house.
Thinking through what i’m doing here. First, I use an introductory sentence to tell the reader what they will learn in this pargraph: that 1972 is a really good counter-example to nationalization. Then I tell them how this graph will show a lack of nationalization (looking at the relationship between pres and house voting), telling them what is in the graph and what we would expect if voters were nationalized. The phrase “but that’s not whay we see” is KEY, this wakes the reader up and says “This is surprising!”. I then talk thgough the data using real proper nouns the reader can understand.
The sentences within a pargraph matter, and (maybe more so) the order of paragraphs matter.
This, more than anythign else, flows from clear thinking about your topic. In what order do I need to present things so that the reader understands? You accomplish this with correct ordering and proper signposting along the way to keep the reader on track.
Proper ordering is something that can be practiced and learned. One practice that I do is to do a “meta-outline” for articles that I am reading. I look at an article that I think does a good job and think about the purpose of each paragraph in the piece. What part of the argument does the paragraph convey? Does it introduce a new point? Is it a change in direction? A signpost? Does it give an example that helps the reader understand technical material to come later?
Let’s consider this NYT article on race on mobility.
I’m going to go through the first 5 paragraphs and think about what the purpose of each is:
Black boys raised in America, even in the wealthiest families and living in some of the most well-to-do neighborhoods, still earn less in adulthood than white boys with similar backgrounds, according to a sweeping new study that traced the lives of millions of children.
Introduces the overall argument and data, that black boys earn less than white boys even after taking into account their backgrounds.
White boys who grow up rich are likely to remain that way. Black boys raised at the top, however, are more likely to become poor than to stay wealthy in their own adult households.
Briefly states the evidence for this claim: White boys who are rich stay rich, rich black boys are more likely to become poor than to stay wealthy.
Even when children grow up next to each other with parents who earn similar incomes, black boys fare worse than white boys in 99 percent of America. And the gaps only worsen in the kind of neighborhoods that promise low poverty and good schools.
Makes clear the finding is robust to a potential critique: this isn’t solely about neighborhood. Even black boys who grow up in similar neighborhoods fare worse.
According to the study, led by researchers at Stanford, Harvard and the Census Bureau, income inequality between blacks and whites is driven entirely by what is happening among these boys and the men they become. Though black girls and women face deep inequality on many measures, black and white girls from families with comparable earnings attain similar individual incomes as adults.
Discusses a complication to the maing findings, that this has to do with the intersection of gender and race, as this seems to only occurring among boys, not girls.
“You would have thought at some point you escape the poverty trap,” said Nathaniel Hendren, a Harvard economist and an author of the study.
Gives A quote from a researcher that connects the research to a broader issue: this isn’t just about economic data, but speaks to broader concerns about poverty and the American Dream.
What is the point in doing this?
First such an exercise can show us how pargraphs should be ordered to make logical sense. Notive how I can make a paragraph out of the topics of these paragraphs:
Black boys earn less than white boys even after taking into account the childen’s background. White boys who are wealthy stay wealth, while black boys are more likely to become poor than be upwardly mobile. This finding isn’t about neighborhood: even Black boys who grow up in the same neighborhood as White boys fare worse. This relationship is about the intersection of gender and race, as this only really occurs among Black boys, not girls. Experts feel that this isnot just about economic data, but speaks to broader concerns about poverty and the American Dream.
This was really easy to write, and helps show that these paragraphs are in a logical order.
Down further you will find paragraphs that explicitly indicate an objection, or a change in direction. As above you can easily form the topics of those paragraphs into a “meta” narrative by connecting them with things like “But” and “Additionally…”. The key point is that all go together in a good order, and the thing that connects them is not “And here’s another thing”.
This type of outlining is very helpful for your own writing. Particularly if you already have things written in can force you to confront if things are in a reasonable order or not.
The other thing that I would encourage you to do is to plagiarize the structure of articles that you like.
I still do this often. I will find an academic article that is similar to what I want to write and that is well regarded. I will go through and think about what the purpose of each paragraph is and write my article in the same way. “Here is where they briefly discuss their findings.”; “Next they talk about a common objection and discuss why it doesn’t apply”; “After that they discuss how they measured a key variable” etc. To be clear: don’t plagiarize the content of an article, but you are free to plagiarize the structure.
One particularly helpful “meta-narrative” move for work in data is to hook the reader in with an example from your data.
One of my grad school mentors, Larry Bartels, would always try to remind us that every observation in a dataset is infinitely interesting on it’s own. For example, in the “Nationalization” figure above each of those points is a politician with a whole career and life! We can get “databrain” where we start seeing everything as numbers and forget that we can tell interesting stories about just one row.
So for example, before introducing the graph above I may write:
Voters in today’s politics are overwhelmingly driven by partisanship. Up and down the ballot, voters largely vote on the basis of national partisanship, not making distinctions based on the individual merits of candidates. But such distinctions were commonplace 40 years ago. Consider Democrat Chester E. Holified running in California’s 19th district in 1972. In that election, Holified’s constituents voted 60-40 to re-elect the Republican president, Richard Nixon. In 2020, such a clear preference for one party over the other would doom this incumbent. But Holifield didn’t just squeak out a win: he won 70% of his constituent’s support. Voters in California’s 19th district in 1972 were clearly applying different criteria to different offices – criteria that would allow them to overwhelmingly re-elect a Republican President and a Democratic member of the House.
The readers now have an actual human example of the overall phenomenon i’m describing, which will hook them in.
That’s not all, now that they understand a particular case, I can point them to the bigger phenomenon that represents:
Was Holified unique in his ability to outperform the Democratic candidate for President – George McGovern – in his district? Figure 1 displays, for the 1972 election , the Democratic vote for president in each district and the Democratic for the House in each district. If voters are nationalized and vote simply on the basis of partisanship, all points would be on the 45 degree line. But that’s not what we see in the data. Many House members – including Holifield, highlighted in red – are in the upper left quadrant: districts that voted to re-elect Republican Richard Nixon, while also returning their Democratic members to the house.
(I’m too lazy to go back to my thesis data and to highlight Holified, but you get how that would be helpful.)
9.2.3 Keep it Simple
The other key tip from Zinnser is to keep things simple:
Clutter is the disease of American writing. We are a society strangling in unnecessary words, circular constructions, pompous frills, and meaningless jargon…. The secret of good writing is to strip every sentence to its cleanest components.
(As a non-American let me assure you that clutter is not a purely American phenomenon.)
Avoiding unnecessary words is really important – particularly when writing about technical subjects. I really try my hardest to take out as many words as possible from my writing.
I was listening to a podcast where Mike Birbiglia was talking to John Mulaney about joke writing. They are talking about refining jokes and how, if they had a 60 word joke, they would write a 20 word version and see if it’s still funny. I think you have to do something similar with writing: if you have an introduction that is 400 words, can you try to write a 100 word version that still does the same thing?
I think this is particularly important when thinking about anything that comes before the “main” figure. When considering the lazy reader, getting to the point as fast as possible is paramount. I often ask: what is the minimum amount of words I need to put before the title and the first figure so that the reader understands and cares about that figure. (It’s usually not a lot, or way less than you would think.)
The other big part of this when it comes to statistics is avoiding jargon. Jargon plagues statistics. I try my hardest to explain things in regular, human, language. I would encourage you to do the same. Can you describe the results of a regression without using any of the jargon from regression? Can you explain the results of a statistics test without saying “standard error” or “p-value”. It’s good to try. When jargon is unavoidable you should, at the very least, explain what the jargon means.
9.2.4 Other Tips
There are couple of other little tips I think about when writing.
- Never repeat yourself. A good sign of poor editing is if I see the exact same point being made in two places. So never repeat yourself.
- Mostly everything I write is in the present tense.
- Avoid adjectives: “
verysignificant”, “noteworthyresult”. Definitely avoid double adjectives “verynovel”. (I’m bad at this) - Whenever I find myself typing “In other words…” it simply means I subconciously know I did a bad job of explaining the something the first time. Just go do it better the first time.
- Saying “I” in an essay, or even academic article, is fine. That’s a weird high school rule.
- The singular “they/their” in the place of his/her is now accepted practice. “The student was curious about their grade.”
9.3 Tips on Presenting
Oh buddy, you think your reader doesn’t care about you?
All advice above for lazy readers goes double for in-person presentations.
No one is paying attention. Seriously. No one is paying attention.
The sooner you start presenting with this in mind the better. Similar to writing, the goal of a presentation (at something like a conference) is for someone to remember your name, your topic, and to think that you are smart. That’s it. All I want is for people to come up to me and say, “Oh Marc, you presented on straight-ticket voting at AAPOR, right?”.
As above, to present well you need to know what your singular contribution is and to get to it ask quickly as possible.
You need to get to this contribution as fast as possible. In Cochrane’s writing tips above he suggests starting presentations with “Here’s Figure 1”. I’ve never had the confidence to do that, but I try to put as little as possible before my main result.
First off: you should state your main finding and conclusion in the first 3 sentences of your presentation, even if people don’t fully understand it. Then think: what is the minimum amount of “Theory” and “Literature Review” you need to do so people understand your result. It is often zero.
Similarly, people rarely care about descriptive statistics. Sometimes people will preview the results in case they don’t have time to get to them which Cochrane calls a “self-fulfilling prophecy of time wasting”.
To get to and highlight your singular contribution you need to remember that most things don’t need to be in a presentation.
One common violation of this is that people think about presentations as Lab Reports: Here’s all the stuff I did! The audience doesn’t care about, and won’t remember, the process you took to get to the results, they just care about the results. Occasionally, your process is your contribution: say if you have a new measure or collected interesting data. That’s fine, but most of the time you want to skip over this stuff.
Another common violation of putting too much in a presentation is when people list through 6 different hypotheses they have. There is no way people are going to remember these things. Your presentation is an advertisement for people to learn more about your work or to read a longer paper that you have prepared. You don’t need everything, just the big main finding that hooks them in. The interested people will go and read about your other 5 hypotheses and alternative measures.
In general, like with writing you want to get to the main finding as quickly as possible, which means putting the minimum amount of material between the start of the presentation and the main finding. The material you do put will be a reflection of your clear understanding of your topic. Once you really understand something, you are ready to answer the question “What do people need to know to understand what I am trying to say and why it is important?”
When it comes to how to present your main finding you would be surprised at how simple you need to make things, even for relatively sophisticated audiences. It’s good to remember (even for your small presentations you have this semester) that nobody has thought as much about this thing as you. It’s really easy in that situation to think: “Surely this is too dumbed down. People are going to laugh at how simple this is.” In my experience this is almost never true and instead there have been many many times where I have no idea what people are trying to show me. (And lots of times where people had no idea what I was trying to show them.)
A good rule of thumb is to always start with the simplest possible view of your “main” relationship, even if that is not the most “complicated” version of what you do.
Let me give two examples:
Here is the “main” relationship from my Science article about partisan responses to the COVID social distancing guidelines.
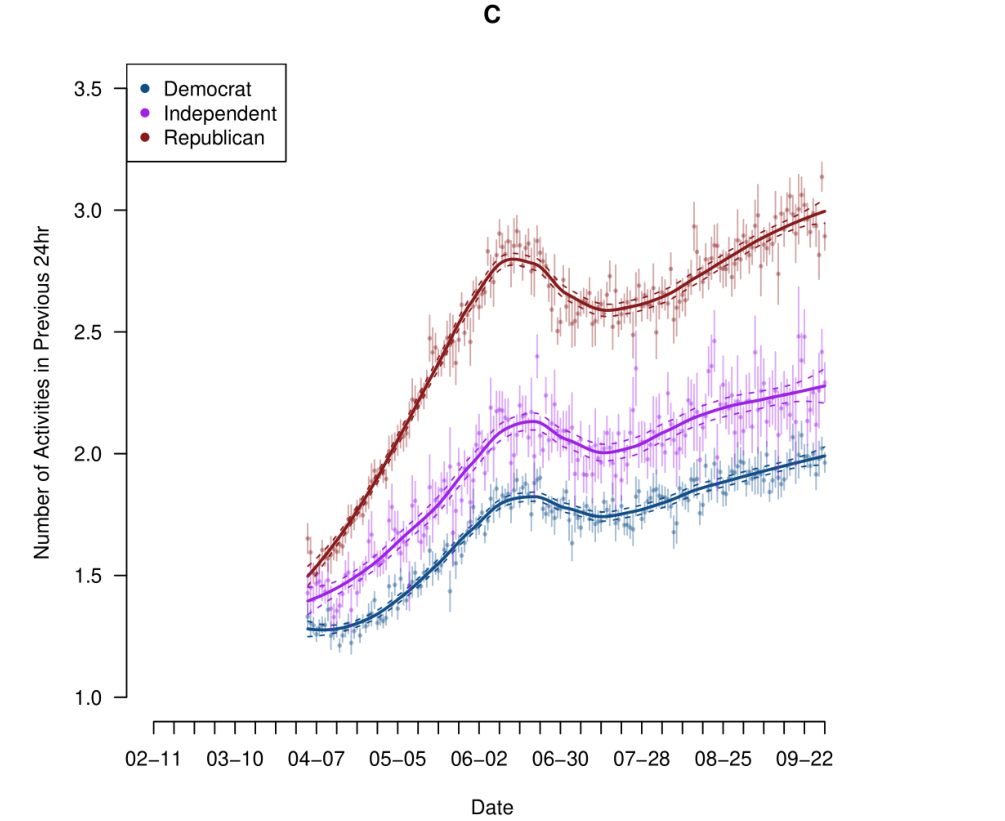
This graph is relatively simple, I’m just plotting the average number of activities each group did over time and then adding a “smooth” line to each. This is easy to understand and to explain. Now, in the paper I run much more complicated models that take into account all sorts of possible threats to inference. But the thing is all these results just confirm this simple result. There is no real reason to show people these complicated models because this simple, understandable, graph is enough. You can tell people: “Don’t worry! This result holds up when we do X,Y,Z.”
Here’s a second example, from my Thesis. This is another simple graph showing the number of Broadband providers in a district on the x-axis and the difference between the house and presidential vote in the district on the y-axis.
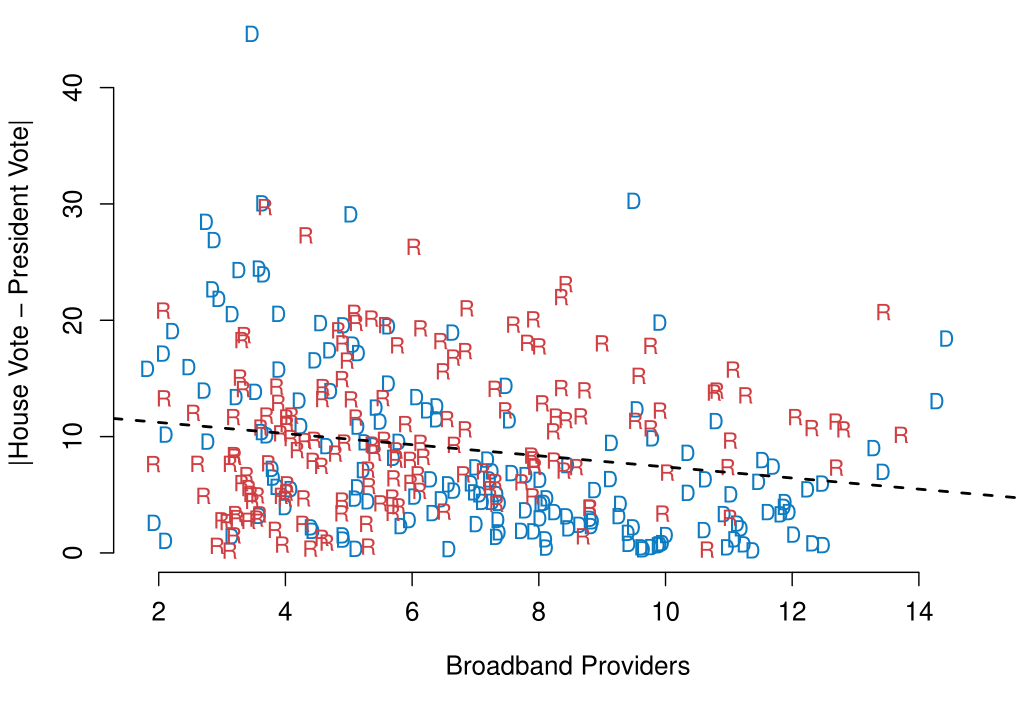
This, again, is a relatively simple graphic, but in this case it is actually very misleading. The tests I run in my thesis severely complicate this simple story, to the point that I don’t want this to be the “main” result. However, I will still show this first so people can understand what relationship I’m looking for. It is then much easier to transition to “And here is why this is misleading” if they have the grounding of the graph first.
Another trick I do with my main results is to present the graph with no data first. Graphs are hard to understand! You need to think about what the two different axes are measuring, and if you are trying to do that while the presenter is talking about the result it’s often too much to process.
So for this figure, a key part of my work, I will present this empty figure first and say:
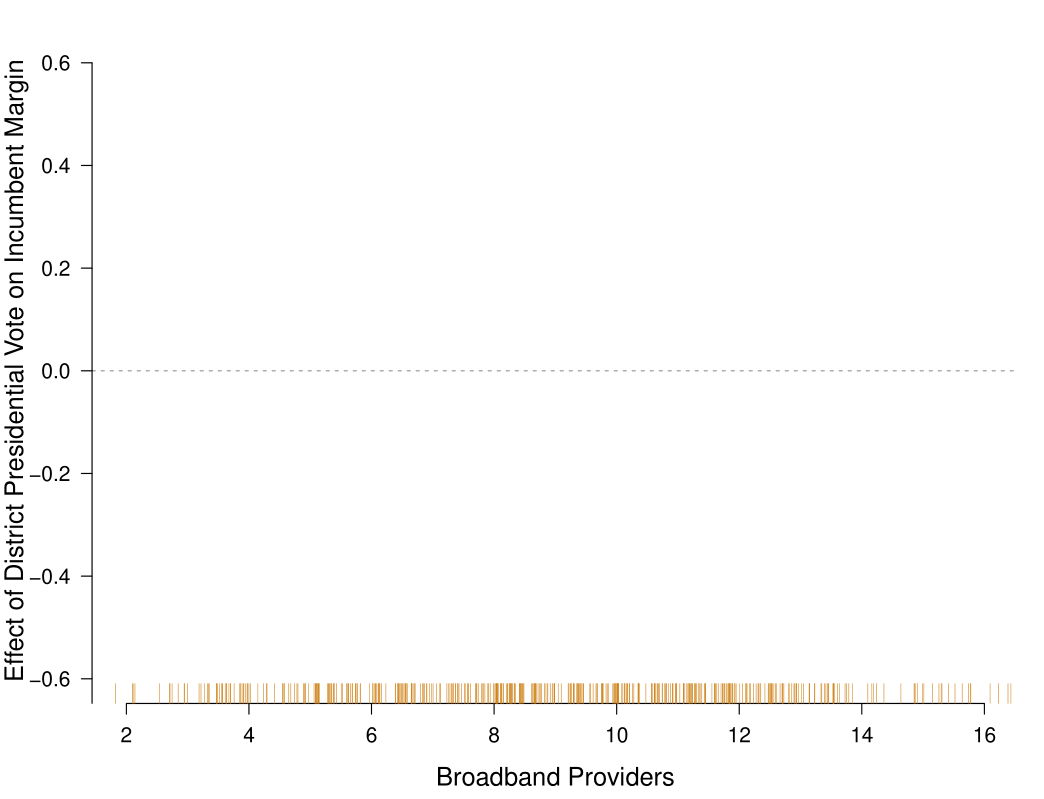
This graph shows the number of Broadband Providers on the x axis, and on the y-axis the effect voting for President has on voting for the House. In a world of political nationalization this effect will be positive and non-zero: as a district votes more Democratic (or Republican) for President they will also vote more Democratic (or Republican) in the house. Our expectation is that this relationship will become more positive as the number of Broadband Providers increases.
Then I reveal the data and say:
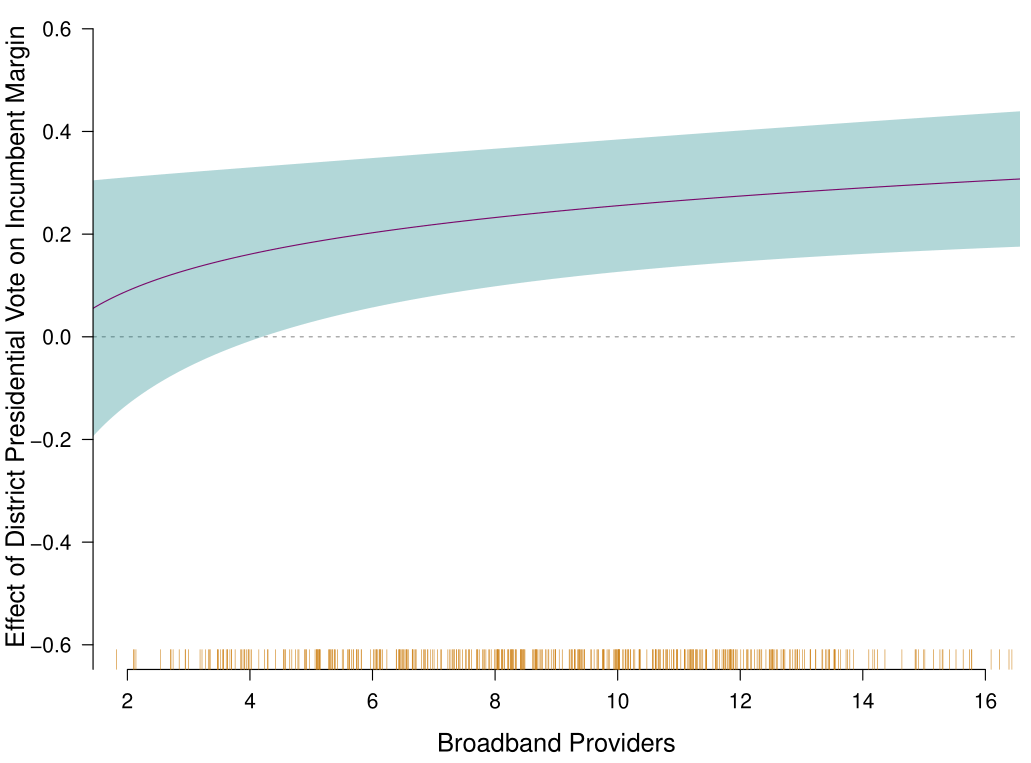
And that’s just what we see. At low levels of Broadband the effect of Presidential vote on House vote is close to zero, indicating that these things are operating independently. But as the number of broadband providers increases, the effect becomes more positive and distinguishable from zero.
This splits the presentation of the graph into two parts for the listener to digest in turn: (1) What this graph is designed to show; (2) what the results are. Number (2) will have the impact you want if you take your time on (1).
Some other minor tips for good presenting:
Keep slide words to a minimum. They should be visual aids for people who weren’t paying attention who want to re-engage, but most of the content should be coming from you.
Conditional on keeping slide words to a minimum you can have as many slides as you want. Rapid fire slides with images/text cues can help people stay engages so I don’t worry about stuff like “No more than 1 slide per minute”. Indeed, if you spend 1 full minute on a slide people will check out.
Speak confidently and directly while making eye contact with as many people as possible. If you find you are not a confident presenter I would (no lie) watch a lot of stand up comedy. Don’t try to be funny, but stand-ups are experts at choosing a cadence that engages people.
You don’t really have to answer questions. 95% of questions happen because people are bored and want to hear their own voices, so they don’t really care about the answers. That being said, you should really listen to questions. Don’t try to jump the gun and guess what the person will ask. If you listen to questions you will better be able to politician-pivot to the question you actually wanted to answer and have content for. Finally, if there is a really good and hard question you don’t know the answer to you can literally say, “Wow! That’s a really good question. I haven’t thought about it in that way. I’m going to have to think more about that. Thank you.”
And all of the above advice filters back to the “taking questions” thing, because the situation where you will face the hardest and most annoying questions is when you don’t communicate clearly what you are doing. Put in a more positive way: If you are confident about what you are doing and why you will get less inane questions.
9.4 Improving (?) Visualizations with ggplot
Guest Lecture by Dylan Radley
The visualization methods that we have used thus far in this class can get you very far. The combination of plot add-ons like points abline segments etc are extremely powerful. Making good use of these things will allow you to make pretty much any sort of plot that you wish to make with a high degree of customization. Indeed, this is all I’ve ever felt the need to use in my career and i’ve been able to built a distinct personal style using nothing but the basic tools. (By “distinct personal style” I mean that my grad school friends make fun of me for how all my graphs look the same.)
A lot of other people using R don’t like using the basic plotting tools and instead use the package ggplot2 in order to make their visualizations. It’s so ubiqutous that I definitely have to share it with you, but don’t worry if it’s not for you! Similarly: if you love ggplot and don’t want to use basic plots that’s also fine! Use whatever tool helps you to express what you want to express.
In this chapter we are going to briefly cover some rules of thumb/tips for good data visualization, then we will go through some examples of graphs using GGPlot.
9.4.1 Tips for Good Visualizations
1. Make sure your visuals are clear!
- A good graph should be able to stand on its own; make sure there is enough information in the title, axis labels, any legends, etc. for the reader to interpret it without additional context.
2. Pay attention to your data!
- Think about what type of graph best fits your data.
- Looking at the correlations between two continuous variables? Something like a scatter plot might work.
- Want to graph the proportion of your observations in each group? A bar graph may be appropriate here.
- Trying to evaluate a single variable? A box plot, density plot, or histogram can all help.
- You may have to reformat your data to make graphing easier in some cases.
- Make sure your pick scales that represent your data and do not accidentally exclude values.
3. Think in terms of dimensions!
- You can think of each thing that you can change on a graph as a dimension, which can communicate information. For example, the (x, y) coordinates can tell you where an observation is with respect to two variables. The color you use can split the points into groups. Different panels can further split the points into groups, and so on.
- Try to keep things simple and clear: Generally you only want one ‘dimension’ corresponding to a single variable, and vice versa. For example, there’s no reason to have population change the size of your points AND be the x-axis on a scatterplot.
4. Draw the visual you want to make!
- Trying to create a visual in code completely from scratch can feel confusing or overwhelming. Instead, just draw a picture of what you imagine the graph should look like. Then, it can be easier to code one piece of the graph at a time.
5. Look at graphs for inspiration, and don’t be afraid to Google!
- The possibilities for data visualization are endless! You can take inspiration from other graphs, take a look at GGPlot functions to explore new graph types, and so on. That said, there’s also a great deal you can communicate using just a well-made scatter plot, so don’t go overboard on fancy graph types when a simpler graph can do the trick.
- Google is your friend when it comes to creating plots. There are many ggplot tools, and I would be lying if I said I didn’t have to google functions for my plots when I want to do things all the time!
If you keep those tips in mind, you will be well on your way to creating compelling data visualizations! Let’s work through two examples: a scatterplot and a barplot.
9.4.2 Loading our Data
First, let’s load in our data and take a quick look at it:
elect <- rio::import("https://github.com/marctrussler/IDS-Data/raw/main/VizData.Rds")
head(elect)
#> state district.id plean.16 plean.20 pshift.16to20
#> 1 AK AK001 -8.280316 -4.551938 3.7283773
#> 2 AL AL002 -4.615244 -15.357825 -10.7425809
#> 3 AL AL003 -17.023121 -17.571795 -0.5486738
#> 4 AL AL005 -16.794313 NA NA
#> 5 AL AL006 -24.558236 NA NA
#> 6 AR AR001 NA NA NA
#> pop pop.density area p.bach unemployment.rate
#> 1 738516 1.293411 570983.198 29.23 7.40
#> 2 680575 67.098880 10142.867 22.47 7.04
#> 3 706705 93.683650 7543.526 21.68 6.93
#> 4 714145 194.176500 3677.813 31.84 5.79
#> 5 703715 168.707400 4171.215 36.08 4.74
#> 6 722915 37.420210 19318.839 16.42 6.52
#> med.hh.inc adult.poverty.rate p.uninsured p.white
#> 1 76715 9.98 14.42 61.04
#> 2 46817 17.29 10.31 61.80
#> 3 46576 18.08 9.12 67.65
#> 4 55043 13.54 9.29 72.67
#> 5 65464 9.95 7.54 76.04
#> 6 40980 18.65 8.24 75.92
#> p.nonwhite p.black p.amerindian p.asian p.hawaiian
#> 1 38.96 3.09 14.02 6.18 1.16
#> 2 38.20 31.11 0.37 1.11 0.01
#> 3 32.35 25.35 0.28 1.80 0.02
#> 4 27.33 17.34 0.61 1.65 0.07
#> 5 23.96 15.34 0.20 1.73 0.02
#> 6 24.08 17.46 0.32 0.50 0.06
#> p.other.race p.multiracial p.hispanic highly.educated
#> 1 0.20 7.40 6.93 0
#> 2 0.12 1.92 3.55 0
#> 3 0.10 1.69 3.10 0
#> 4 0.18 2.39 5.09 1
#> 5 0.20 1.64 4.83 1
#> 6 0.10 2.28 3.34 0
#> dem.win16 dem.win20 flip dem.2party.vote16
#> 1 0 0 0 41.71968
#> 2 0 0 0 45.38476
#> 3 0 0 0 32.97688
#> 4 0 NA NA 33.20569
#> 5 0 NA NA 25.44176
#> 6 NA NA NA NA
#> dem.2party.vote20 region
#> 1 45.44806 West
#> 2 34.64217 South
#> 3 32.42821 South
#> 4 NA South
#> 5 NA South
#> 6 NA SouthThis is the data I used for my final project when I took this class! (So let’s also not judge baby Dylan too harshly for any weirdness or inconsistencies in the data)
Our unit of analysis for this data is a Congressional District. This data contains 2016 and 2020 Election Results at the Congressional District level, as well as a great deal of demographic information from the 2019 ACS. This data omits congressional districts that redistricted between 2016 and 2020, because we cannot make a comparison between them in that case.
There are four variables worth explaining in the data.
- plean.16 is the Partisan Lean of the district in 2016. This is an idea I stole from 538, and it’s essentially the Democratic two-party vote share in 2016 minus 50. In other words, a district with a partisan lean of 0 would be tied exactly between Democrats and Republicans. A partisan lean of 30 means this is a heavily democratic district; the Democrat won by 30-points. The reverse, -30, would be a heavily Republican district.
- plean.20 is the same concept, but for the 2020 election.
- pshift.16to20 is the Partisan Shift from 2016 to 2020, calculated as plean.20 - plean.16. This allows us to see how certain disricts have shifted, with positive values indicating a shift towards Democrats, and neative a shift towards Republicans.
Now that we have an understanding of the data, I want to make a scatterplot that shows us the relationship between the Partisan Lean in 2016 and the % White in a District.
9.4.3 Creating a Scatterplot
First, I’m going to load the ggplot2 package!
When we set up a plot in ggplot, we have two pieces to start. First, we call the ggplot function, and put in the data that we are going to use, in this case, elect. We can then define our x and y axis for the plot as parts of the aes(), or ‘aesthetics’ argument. Finally, we add a ‘geom’ to our plot, which you can think of as a type of graph. We use a ‘+’ sign and then call the geom_point() function
ggplot(elect, aes(x = p.white, y = plean.20)) +
geom_point()
#> Warning: Removed 21 rows containing missing values or values outside
#> the scale range (`geom_point()`).
You can also define your x and y axes in the aesthetics for your geom, which can come in handy if you’re using different aesthetics for different geoms on the plot. We’ll do it that way and stick with that for the rest of the example.
ggplot(elect) +
geom_point(aes(x = p.white, y = plean.20))
#> Warning: Removed 21 rows containing missing values or values outside
#> the scale range (`geom_point()`).
You’ll also notice that I’m getting warnings when I plot; it’s saying that it removed 21 rows containing missing values. In this case, it’s removing the 21 districts where there was not a competitive election in 2020, resulting in plean.20 being NA. This is a case where I might want to modify my data somewhat for my graph, like so:
elect20 <- elect[!is.na(elect$plean.20), ]Next, I want to add axis titles and a title to the plot. We do this by using +’s to continue adding pieces to our graph. We use ggtitle() for the title, xlab() for the x-axis label, and ylab() for the y-axis label.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20)) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)")
We can also easily change the appearance of the plot using different ggthemes. There’s a list of the different themes at this link: https://ggplot2.tidyverse.org/reference/ggtheme.html.
We’ll add theme_bw() to our plot.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20)) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw()
There is also a ggthemes package if you want more options, you can google that if you are interested!
Next, I want to modify my points a little bit, so that they are a bit smaller and a different shape. To do that, I just need to add the pch and cex arguments, which work similarly to before, to my geom_point object.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20),
pch = 1, cex = 1.1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw()
Next, I am going to modify my axes. I want more tick marks on both, and I also would like the x axis to be formatted as a percent. First, I am going to load the scales package, which we’ll need for the percent formatting.
To modify our axes, we can use scale_y_continious and scale_x_continuous. There is also scale_y_discrete and scale_x_discrete, but we’re using the continuous versions because our axes are both continuous variables. In each of these functions, we can define the limits (like xlim and ylim in the past), as well as the breaks, where we’ll define the tick marks we want to appear.
Finally, we will use the labels argument to define our labels. The percent_format function from scales will come in handy here, and setting the scale argument of that function to 1 will have it scale from 1-100%.
library(scales)
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20),
pch = 1, cex = 1.1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1))
So far, we’ve been thinking about just partisan lean and percent white, but we can add more information to our graph by adding another ‘dimension’. We’re not going 3D, but we can add color to our graph. I’m going to add a color argument to the aesthetics for geom_point and set it equal to highly.educated, which mean that the points will now be colored by education. Highly.educated is a indicator variable where 1 is equal to places at or above the median educational attainment, and 0 is below it.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20, color = highly.educated),
pch = 16, cex = 1.1) + # changed the point shape too
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1))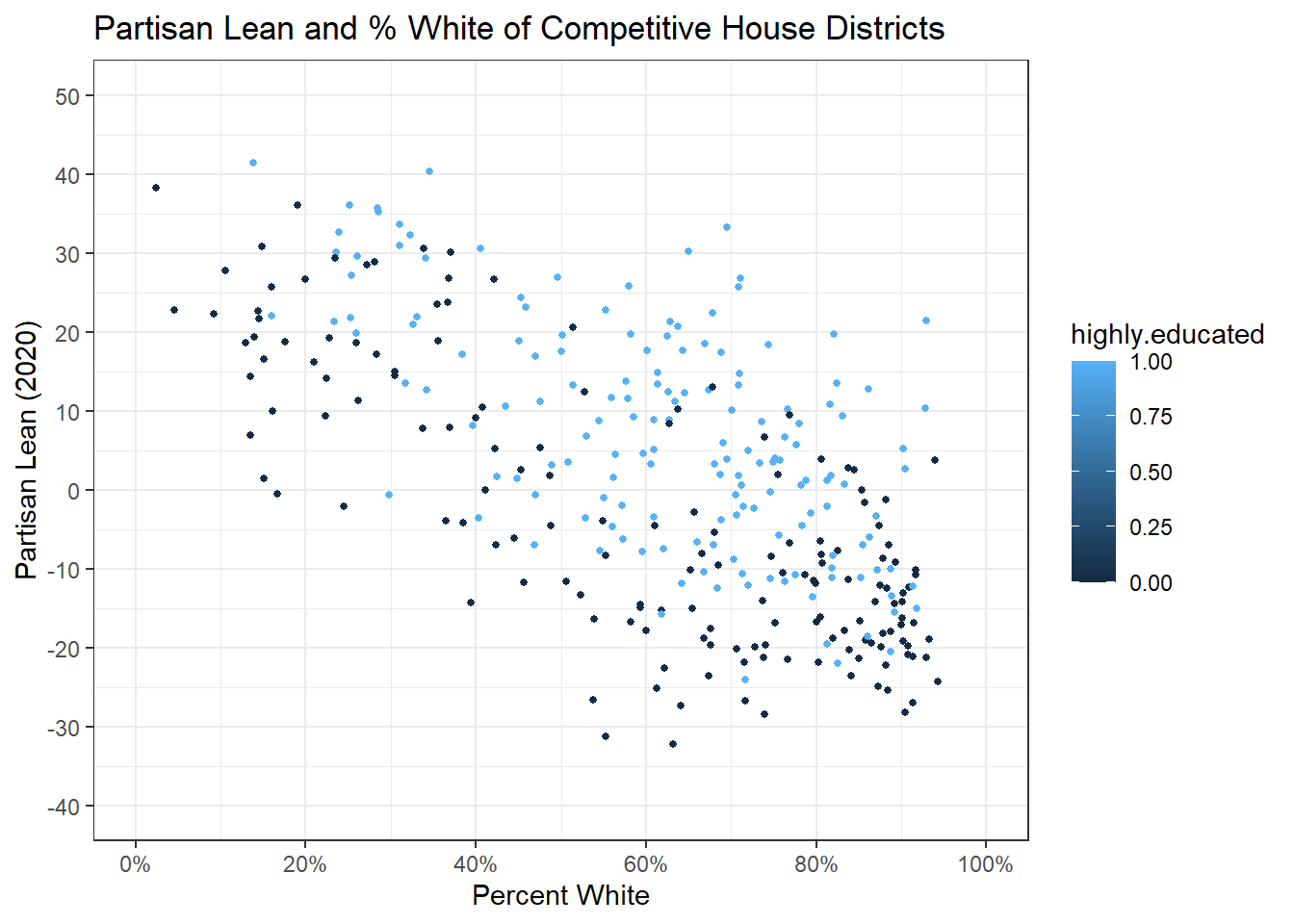
You’ll notice that our legend is being put in as a gradient. This is because our indicator of 0-1 is being interpreted as a continuous variable. We could convert it to a T/F variable, but instead I’m just going to use as.factor() instead.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20, color = as.factor(highly.educated)),
pch = 16, cex = 1.1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1))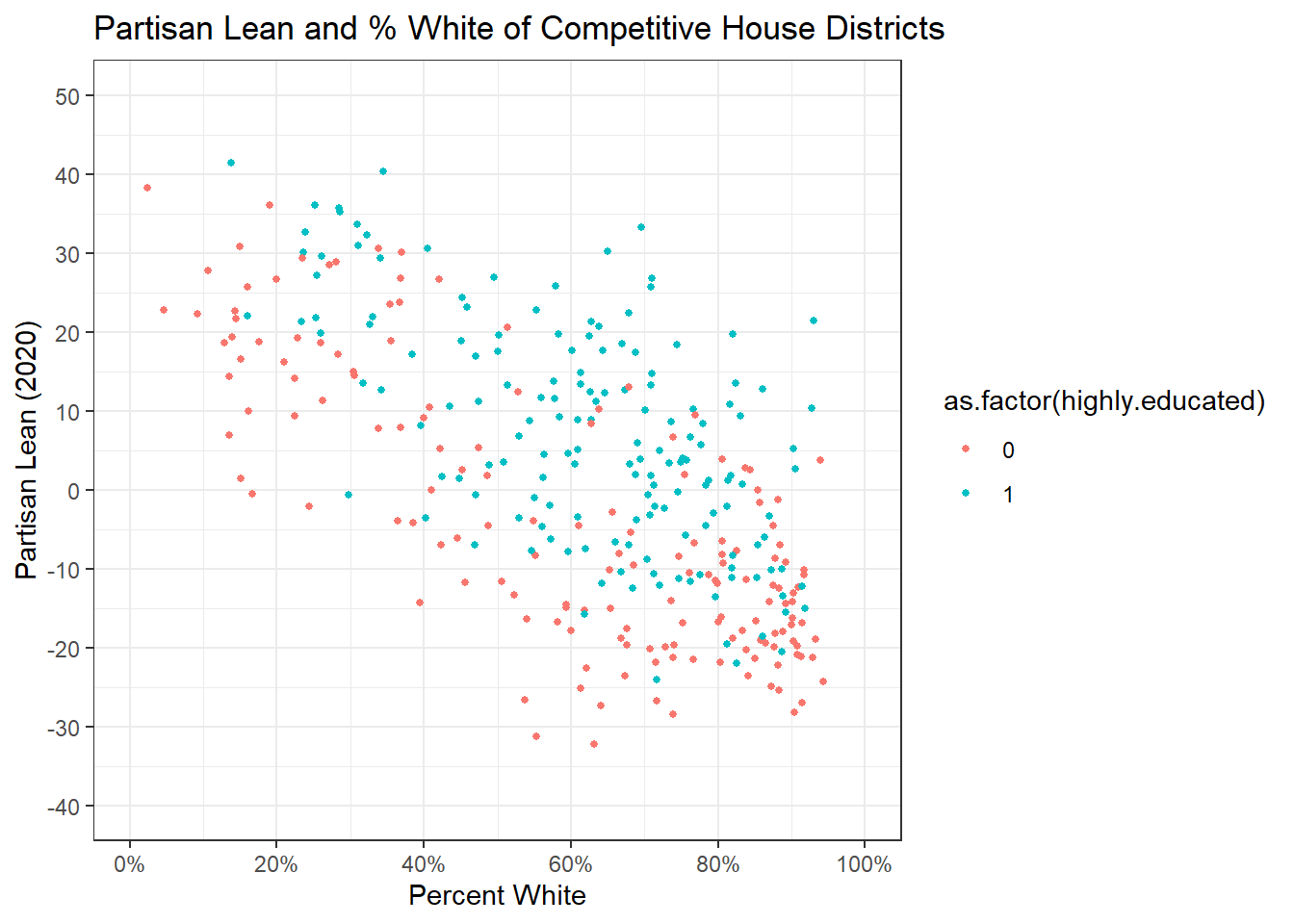
This is a bit better, but I also would like to improve my legend a bit. First, I’m going to move it to the bottom of the graph. I can do this by adding the theme() function, which can be used for other aspects of the graph as well. We can add the legend.position argument and set it equal to “bottom” in this case.
I will also add the labs() function and set the col argument in that function equal to my title for the legend.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20, color = as.factor(highly.educated)),
pch = 16, cex = 1.1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom") +
labs(col = "Above-Median With a Bachelor's Degree")
Now, I would also like to change the colors of my points, as well as their labels in the legend. I can do this using the scale_color_manual() function, where the values argument can be set to be the colors I want, and the labels argument the labels I’d like for each color.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20, color = as.factor(highly.educated)),
pch = 16, cex = 1.1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
labs(col = "Above-Median With a Bachelor's Degree")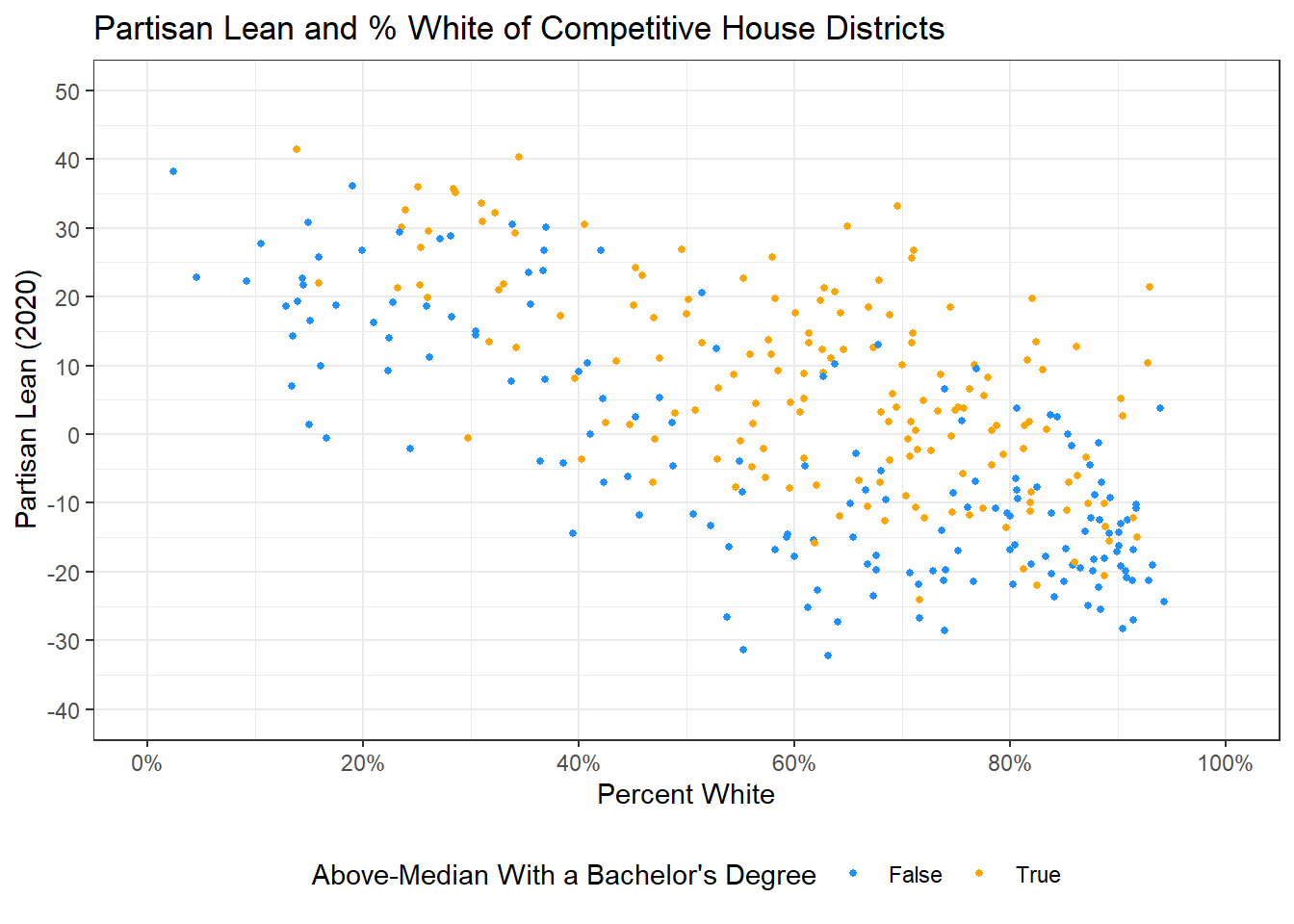
This is a pretty solid graph! I’m going to add another dimension though, so express even more information about the Congressional Districts. I’m going to add the size argument to the aesthetics for geom_point, and set it equal to the pop.density variable. I will also remove the cex argument; this sets the size of our points, so we need to remove it to allow size to vary between points. I will also change the shape of the points to be empty circles again, so that larger points do not overlap the smaller.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
labs(col = "Above-Median With a Bachelor's Degree")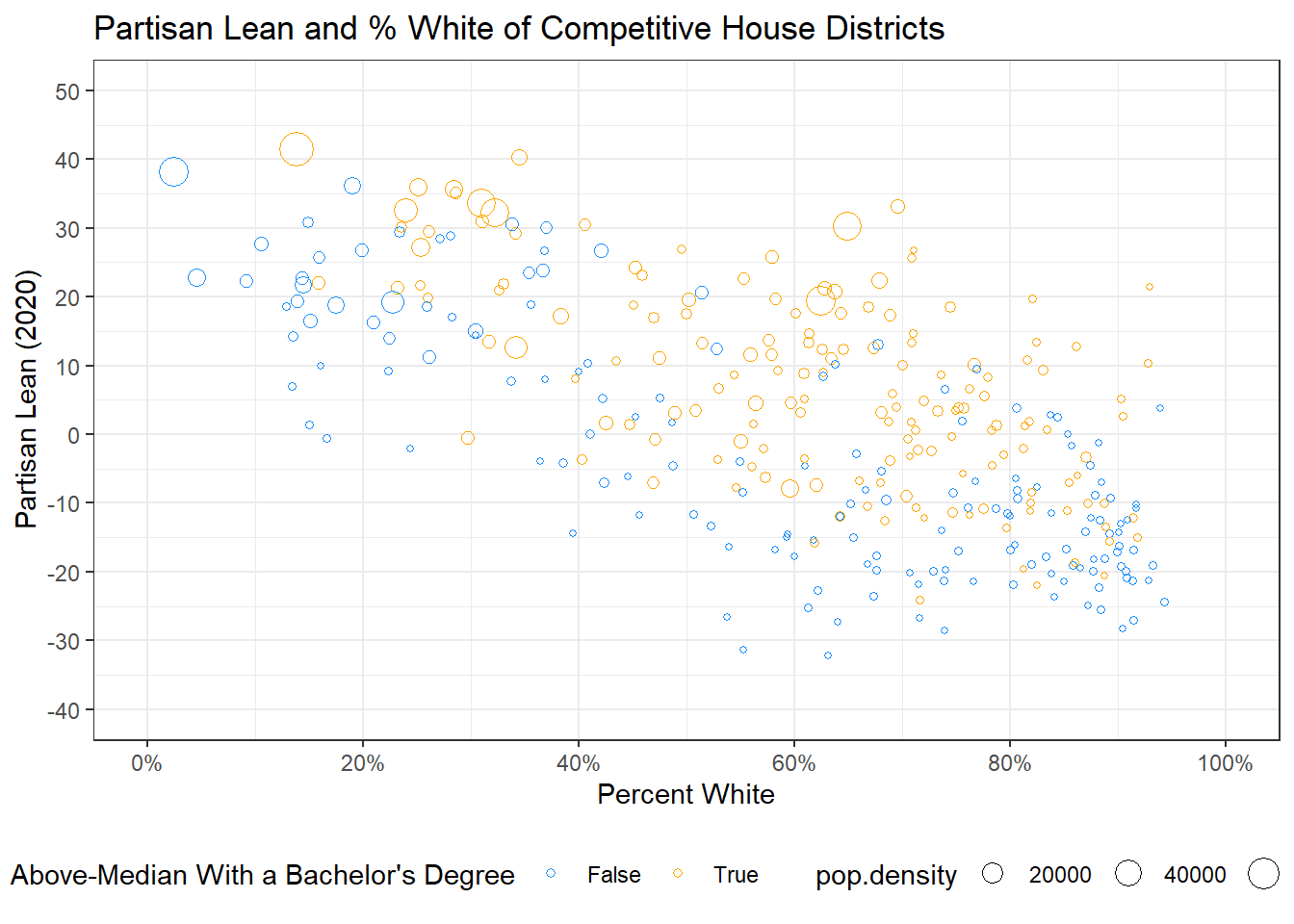
I want to make some more adjustments to our legend now. I’m going to add the scale_size function, which is kind of like scale_x or y, but for the size argument we’ve created. I’ll set limits on the size of the points, as well as breaks that I’d like to have in my legend. Note, the size of the circles can take on more than three values still, but what is expressed in the legend will be defined by breaks.
To modify the legend, I want to do two things. First, I want to add a label for pop.density, which is as simple as adding to my labs function an argument for size. I also want to make our legend vertical rather than horizontal, which I can do by modifying the theme() function, setting the legend.box function equal to vertical.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom",
legend.box = "vertical") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
scale_size(limits = c(0, 80000),
breaks = c(100, 1000, 10000)) +
labs(col = "Above-Median With a Bachelor's Degree",
size = "Population Density")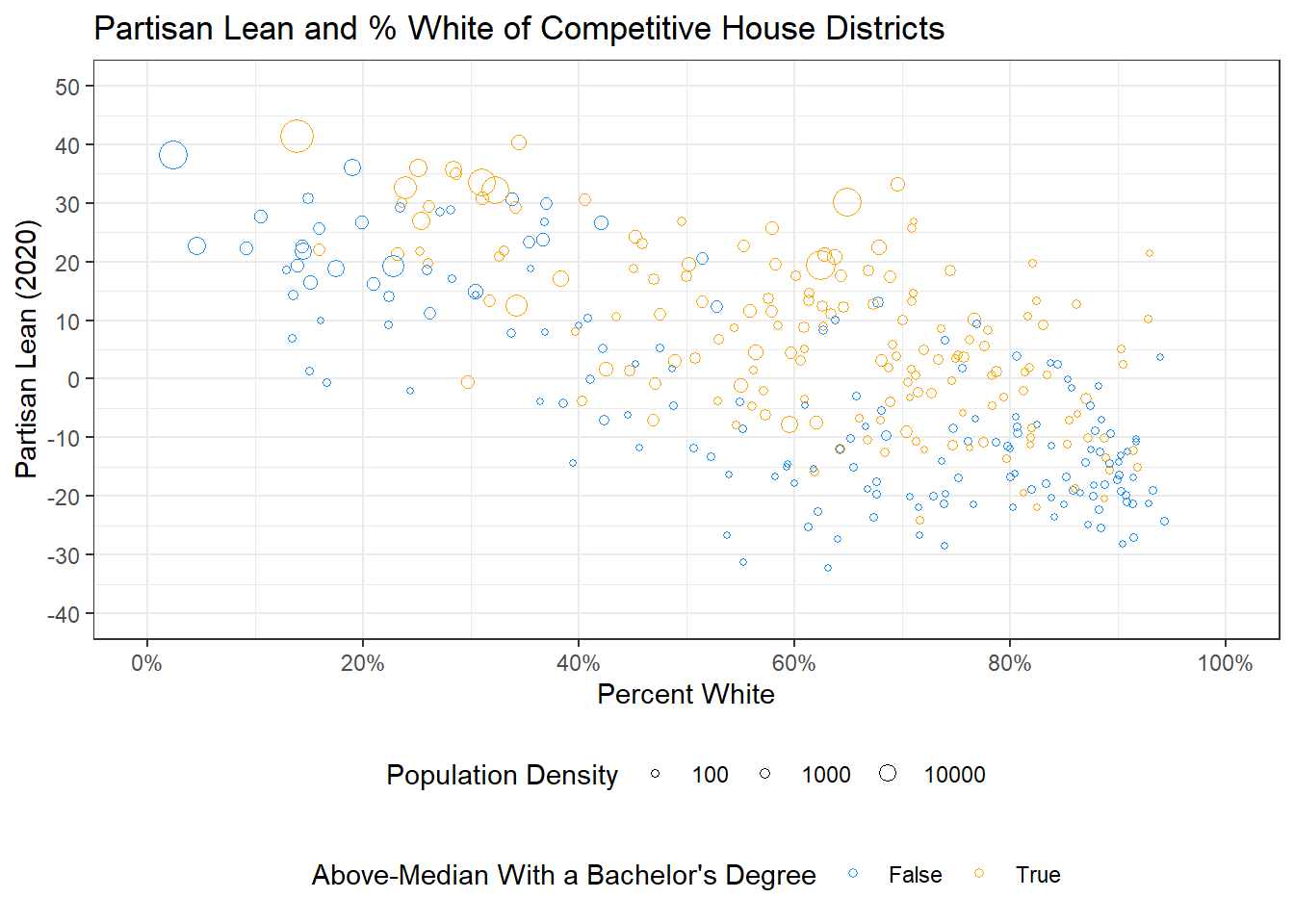
We’re going to now add one more dimension to our graph using what is called a facet_wrap. This allows us to automatically create graphs based on sub-groups. For example, let’s say I want to have separate graphs for each Census Region, to see if the relationship between my variables and partisan lean is affected by region.
To do that, I just have to add the facet_wrap() geom/function. I put region inside of a ‘quoting function’ called vars inside that facet_wrap, and it does the rest automatically!
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
facet_wrap(vars(region)) +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom",
legend.box = "vertical") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
scale_size(limits = c(0, 80000),
breaks = c(100, 1000, 10000)) +
labs(col = "Above-Median With a Bachelor's Degree",
size = "Population Density")
As one last detail, it is sometimes helpful to add lines or other annotations to your graph to increase clarity, or to help make certain conclusions stand out to your reader. In this case, I want to add a dotted line at 0 in my graph, to help show the boundary between Democratic districts above the line, and Republican districts below it.
To do this, I will use the geom_hline() geom (I remember it as horizontal line, to distinguish from geom_vline, or vertical line), with y-intercept set equal to 0, and linetype set to dotted.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
facet_wrap(vars(region)) +
geom_hline(yintercept = 0, linetype = "dotted") +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom",
legend.box = "vertical") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
scale_size(limits = c(0, 80000),
breaks = c(100, 1000, 10000)) +
labs(col = "Above-Median With a Bachelor's Degree",
size = "Population Density")
I’ll also add that line to the non-facet-wrapped version of the graph.
ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
geom_hline(yintercept = 0, linetype = "dotted") +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom",
legend.box = "vertical") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
scale_size(limits = c(0, 80000),
breaks = c(100, 1000, 10000)) +
labs(col = "Above-Median With a Bachelor's Degree",
size = "Population Density")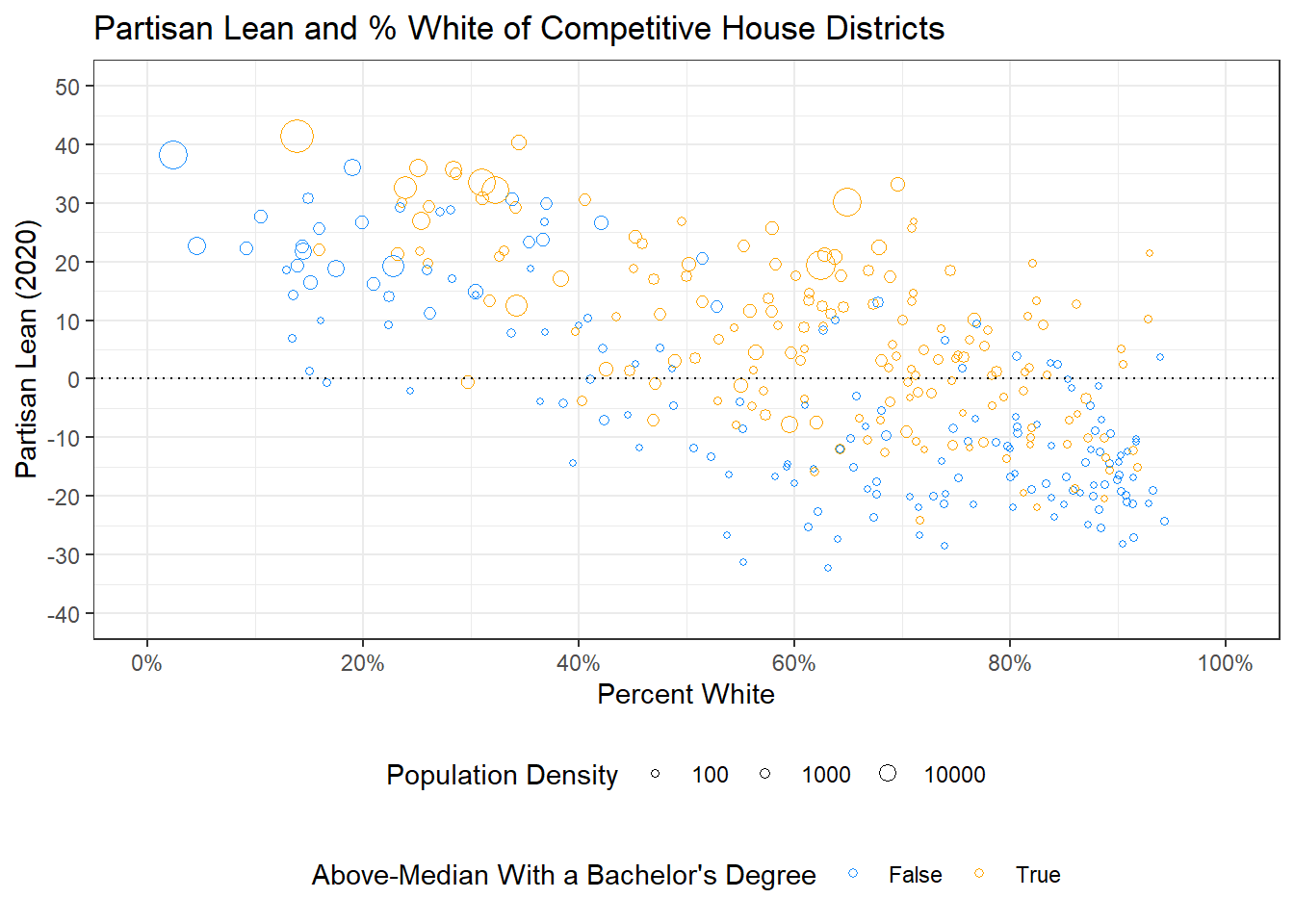
Let’s pause and take a deep breath now. We’ve made a pretty dense plot! You could probably write like two paragraphs about these graphs, at least! I will note that not every graph needs to pack in this much information. Doing so may even be a little overwhelming if you are not careful. In addition, think about how much of a step-by-step process this graph was; we thought carefully about what pieces we wanted to add, one at a time.
Now, I’d like to do one more brief example to show you the basics of making barplots with ggplot!
9.4.4 Making a Bar Plot
Let’s say I want to make a bar plot that just has the proportion of my congressional districts in each Census Region. In order to do this, we need to think about what data we’ll feed into ggplot, for x and y values.
To get the proportion of districts in each region, I can just use prop.table(). Then, I’ll save that as a dataframe to use for graphing!
region.prop <- prop.table(table(elect$region))
region.dta <- data.frame(region.prop)
head(region.dta)
#> Var1 Freq
#> 1 Midwest 0.2573099
#> 2 Northeast 0.1608187
#> 3 South 0.2865497
#> 4 West 0.2953216Now I can make my bar plot! We use a lot of the same tools as before, such as xlab, ylab, ggtitle, etc. In this case, we will put our aesthetics in the ggplot function. We then add the geom_bar() geom, and set the stat argument equal to “identity”. This essentially tells it to set the y-values equal to the value for y for each x. It’s a weird terminology, but it’s how it works!
ggplot(region.dta, aes(x = Var1, y = Freq)) +
geom_bar(stat = "identity") +
ggtitle("Region of Congressional Districts") +
xlab("") +
ylab("Proportion of Districts")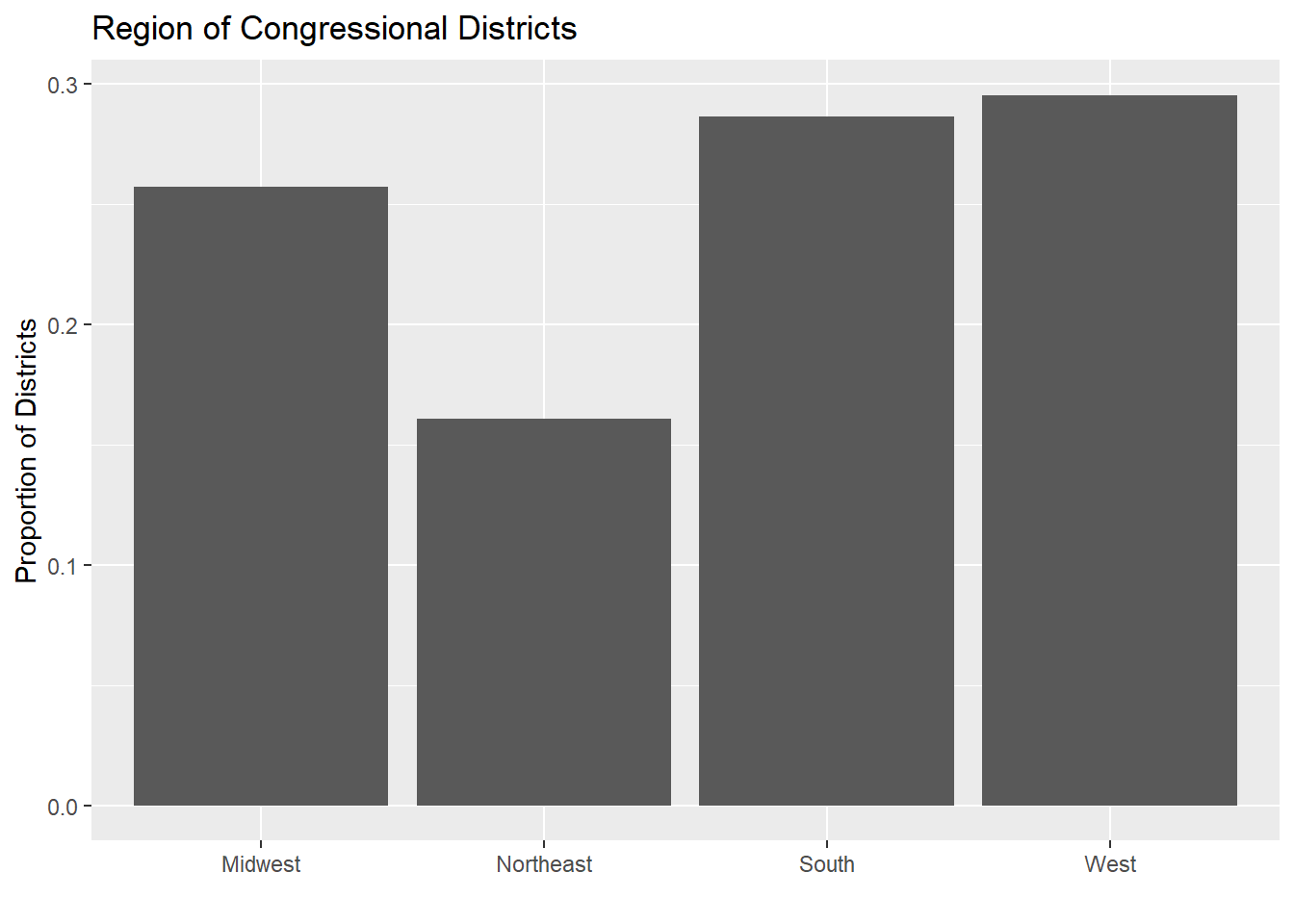
That is the worse shade of grey I’ve ever seen. We can add color (the outline) and fill (what it’s colored in as) arguments to the barplot, like so:
ggplot(region.dta, aes(x = Var1, y = Freq)) +
geom_bar(stat = "identity", color = "black", fill = "lightblue") +
ggtitle("Region of Congressional Districts") +
xlab("") +
ylab("Proportion of Districts")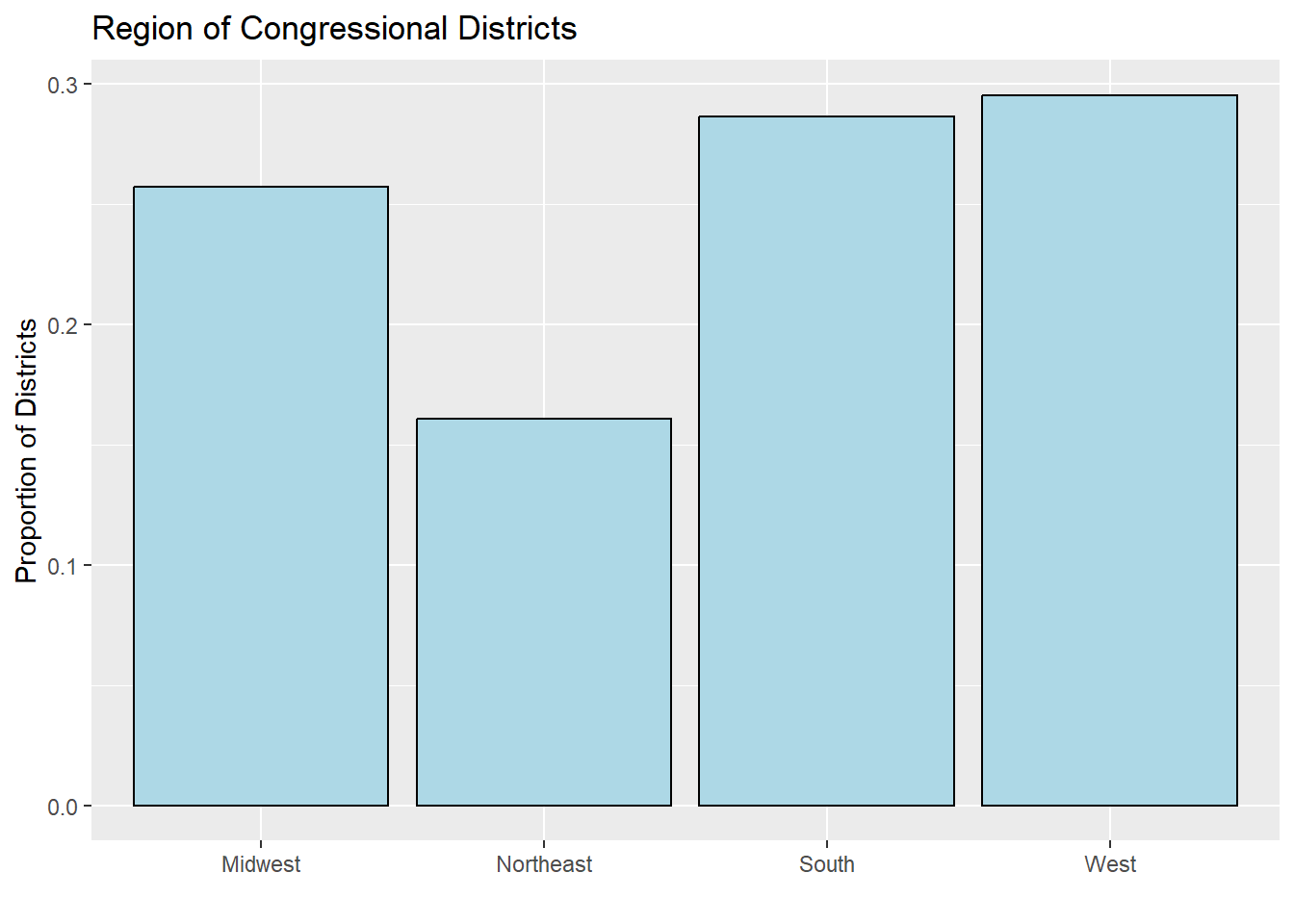
That’s where we’ll leave our bar plots for now! I will go over some additional tricks and tools for barplots in Recitation this week!
9.4.5 Saving your Plots
As one last note, I wanted to show you how to save your plots! Now, your final papers will be written in Rmd, so it will be easy to incorporate your plots into your text. However, if you’re just creating a graphic for work, for a 2-minute presentation for class, or something like that, it can be helpful to save your figures!
Let’s save one of the graphs we made earlier. We can save ggplots as objects, which makes it easier to reference them later, without needing all the code to create the graph.
plean.and.white <- ggplot(elect20) +
geom_point(aes(x = p.white, y = plean.20,
color = as.factor(highly.educated),
size = pop.density),
pch = 1) +
geom_hline(yintercept = 0, linetype = "dotted") +
ggtitle("Partisan Lean and % White of Competitive House Districts") +
xlab("Percent White") +
ylab("Partisan Lean (2020)") +
theme_bw() +
scale_y_continuous(limits = c(-40, 50), breaks = seq(-40, 50, 10)) +
scale_x_continuous(limits = c(0, 100), breaks = seq(0, 100, 20),
labels = percent_format(scale = 1)) +
theme(legend.position = "bottom",
legend.box = "vertical") +
scale_color_manual(values = c("dodgerblue", "orange"),
labels = c("False", "True")) +
scale_size(limits = c(0, 80000),
breaks = c(100, 1000, 10000)) +
labs(col = "Above-Median With a Bachelor's Degree",
size = "Population Density")We use the ggsave() function to save, putting in a filename and what we want to save. We can put in a ggplot object like the one we saved, or it will default to the last plot we created.
ggsave("figureForPaper.png", plean.and.white)
#> Saving 7 x 5 in imageWe can also specify how big we want the image to be!
ggsave("figureForPaperSmall.png", plean.and.white, width = 4, height = 4, units = "in")
# I will note that on this smaller graph the title gets cut off, so be careful of that!